 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Local Communications and Local Updates for LLM Pretraining
Jun 09, 2026Communication-efficient pre-training of LLMs is increasingly important as training draws on compute distributed across clusters, data centers, and lower-bandwidth links. Many practical methods reduce communication frequency but still rely on synchronous All-Reduce operations that maintain identical model states and tie progress to global collectives. This can become a bottleneck when bandwidth or worker speed is heterogeneous. We introduce GASLoC, a novel decentralized pre-training algorithm that generalizes the notion of communication acceleration to the recently popular "outer optimizer" to allow a practical gossip-based training framework that is compatible with adaptive optimizers, allows for local optimizer steps, and can utilize sparse randomized peer communication. Empirically, on a number of standard LLM training tasks, we demonstrate that GASLoC outperforms state-of-the-art decentralized algorithms in single step per communication setting for a number of topologies and, unlike existing decentralized methods in the LLM setting, it allows to obtain performance competitive with DiLoCo when utilizing multiple local steps. In the heterogeneous bandwidth setting we demonstrate the advantage of GASLoC showing that it can significantly outperform DiLoCo.
Learned Subspace Compression for Communication-Efficient Pipeline Parallelism
Jun 03, 2026Pipeline parallelism enables training of large language models that exceed single-device memory, yet inter-stage activation communication becomes the dominant bottleneck when trained on low-bandwidth networks. Recent work in this area has proposed using fixed orthogonal projections to compress activations. However, this still results in a significant performance degradation and requires a number of non-standard adaptations to constrain the optimization. A natural alternative is to learn a low rank projection for each pipeline stage, however maintaining the necessary orthogonality of these projectors during training remains a challenge. We present Manifold Aware Projection Learning (MAPL), a method that treats inter-stage compression as a learnable orthogonal projection under explicit Stiefel manifold (orthogonal matrices) constraints. Rather than prescribing a fixed global subspace, MAPL lets each pipeline stage discover and continuously adapt its own task-optimal compression subspace via manifold-constrained steepest descent. To recover token-specific signals at stage boundaries, we introduce per-stage factorized anchor embeddings that allow for full-rank activation reconstruction with negligible communication overhead. We further show that we can incorporate residual vector quantization after projection with a streaming codebook synchronization protocol that amortizes dictionary communication. Across LLaMA models from 150M to 1B parameters we show that MAPL can be easily applied to the existing pipeline and can achieve high compression with neglibile performance degradation with a drastically improved tradeoffs in performance vs. compression compared to Subspace Networks.
Unbiased Approximate Vector-Jacobian Products for Efficient Backpropagation
Feb 16, 2026In this work we introduce methods to reduce the computational and memory costs of training deep neural networks. Our approach consists in replacing exact vector-jacobian products by randomized, unbiased approximations thereof during backpropagation. We provide a theoretical analysis of the trade-off between the number of epochs needed to achieve a target precision and the cost reduction for each epoch. We then identify specific unbiased estimates of vector-jacobian products for which we establish desirable optimality properties of minimal variance under sparsity constraints. Finally we provide in-depth experiments on multi-layer perceptrons, BagNets and Visual Transfomers architectures. These validate our theoretical results, and confirm the potential of our proposed unbiased randomized backpropagation approach for reducing the cost of deep learning.
Stabilizing Native Low-Rank LLM Pretraining
Feb 12, 2026Foundation models have achieved remarkable success, yet their growing parameter counts pose significant computational and memory challenges. Low-rank factorization offers a promising route to reduce training and inference costs, but the community lacks a stable recipe for training models from scratch using exclusively low-rank weights while matching the performance of the dense model. We demonstrate that Large Language Models (LLMs) can be trained from scratch using exclusively low-rank factorized weights for all non-embedding matrices without auxiliary "full-rank" guidance required by prior methods. While native low-rank training often suffers from instability and loss spikes, we identify uncontrolled growth in the spectral norm (largest singular value) of the weight matrix update as the dominant factor. To address this, we introduce Spectron: Spectral renormalization with orthogonalization, which dynamically bounds the resultant weight updates based on the current spectral norms of the factors. Our method enables stable, end-to-end factorized training with negligible overhead. Finally, we establish compute-optimal scaling laws for natively low-rank transformers, demonstrating predictable power-law behavior and improved inference efficiency relative to dense models.
Test-time Generalization for Physics through Neural Operator Splitting
Jan 31, 2026Neural operators have shown promise in learning solution maps of partial differential equations (PDEs), but they often struggle to generalize when test inputs lie outside the training distribution, such as novel initial conditions, unseen PDE coefficients or unseen physics. Prior works address this limitation with large-scale multiple physics pretraining followed by fine-tuning, but this still requires examples from the new dynamics, falling short of true zero-shot generalization. In this work, we propose a method to enhance generalization at test time, i.e., without modifying pretrained weights. Building on DISCO, which provides a dictionary of neural operators trained across different dynamics, we introduce a neural operator splitting strategy that, at test time, searches over compositions of training operators to approximate unseen dynamics. On challenging out-of-distribution tasks including parameter extrapolation and novel combinations of physics phenomena, our approach achieves state-of-the-art zero-shot generalization results, while being able to recover the underlying PDE parameters. These results underscore test-time computation as a key avenue for building flexible, compositional, and generalizable neural operators.
DISCO: learning to DISCover an evolution Operator for multi-physics-agnostic prediction
Apr 28, 2025We address the problem of predicting the next state of a dynamical system governed by unknown temporal partial differential equations (PDEs) using only a short trajectory. While standard transformers provide a natural black-box solution to this task, the presence of a well-structured evolution operator in the data suggests a more tailored and efficient approach. Specifically, when the PDE is fully known, classical numerical solvers can evolve the state accurately with only a few parameters. Building on this observation, we introduce DISCO, a model that uses a large hypernetwork to process a short trajectory and generate the parameters of a much smaller operator network, which then predicts the next state through time integration. Our framework decouples dynamics estimation (i.e., DISCovering an evolution operator from a short trajectory) from state prediction (i.e., evolving this operator). Experiments show that pretraining our model on diverse physics datasets achieves state-of-the-art performance while requiring significantly fewer epochs. Moreover, it generalizes well and remains competitive when fine-tuned on downstream tasks.
PETRA: Parallel End-to-end Training with Reversible Architectures
Jun 04, 2024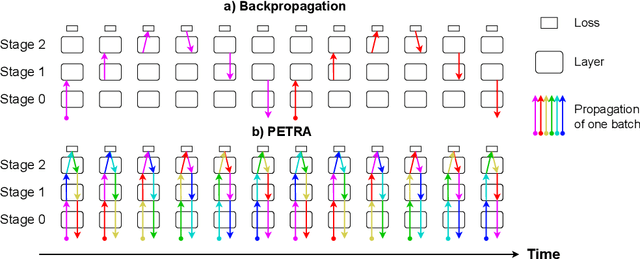
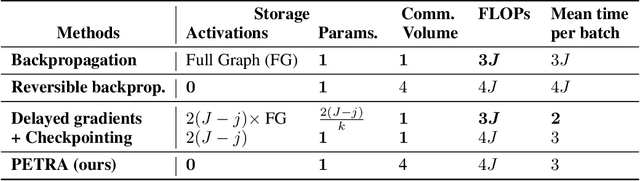
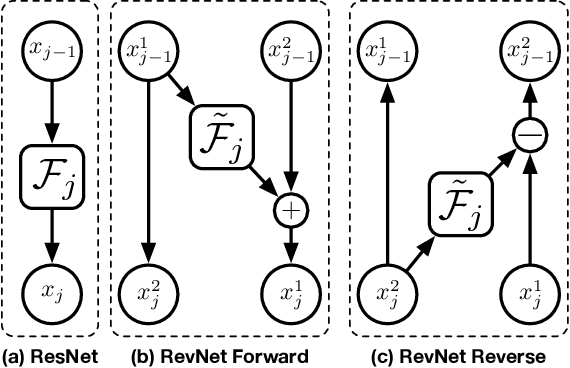
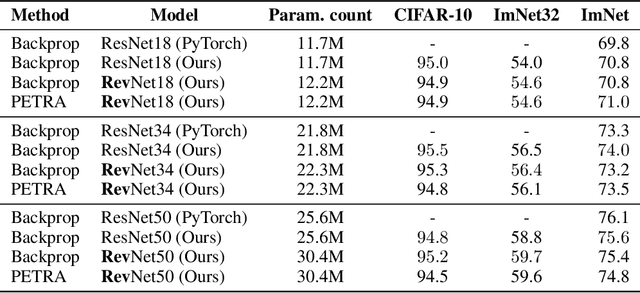
Reversible architectures have been shown to be capable of performing on par with their non-reversible architectures, being applied in deep learning for memory savings and generative modeling. In this work, we show how reversible architectures can solve challenges in parallelizing deep model training. We introduce PETRA, a novel alternative to backpropagation for parallelizing gradient computations. PETRA facilitates effective model parallelism by enabling stages (i.e., a set of layers) to compute independently on different devices, while only needing to communicate activations and gradients between each other. By decoupling the forward and backward passes and keeping a single updated version of the parameters, the need for weight stashing is also removed. We develop a custom autograd-like training framework for PETRA, and we demonstrate its effectiveness on CIFAR-10, ImageNet32, and ImageNet, achieving competitive accuracies comparable to backpropagation using ResNet-18, ResNet-34, and ResNet-50 models.
ACCO: Accumulate while you Communicate, Hiding Communications in Distributed LLM Training
Jun 03, 2024


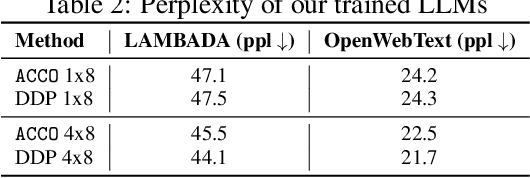
Training Large Language Models (LLMs) relies heavily on distributed implementations, employing multiple GPUs to compute stochastic gradients on model replicas in parallel. However, synchronizing gradients in data parallel settings induces a communication overhead increasing with the number of distributed workers, which can impede the efficiency gains of parallelization. To address this challenge, optimization algorithms reducing inter-worker communication have emerged, such as local optimization methods used in Federated Learning. While effective in minimizing communication overhead, these methods incur significant memory costs, hindering scalability: in addition to extra momentum variables, if communications are only allowed between multiple local optimization steps, then the optimizer's states cannot be sharded among workers. In response, we propose $\textbf{AC}$cumulate while $\textbf{CO}$mmunicate ($\texttt{ACCO}$), a memory-efficient optimization algorithm tailored for distributed training of LLMs. $\texttt{ACCO}$ allows to shard optimizer states across workers, overlaps gradient computations and communications to conceal communication costs, and accommodates heterogeneous hardware. Our method relies on a novel technique to mitigate the one-step delay inherent in parallel execution of gradient computations and communications, eliminating the need for warmup steps and aligning with the training dynamics of standard distributed optimization while converging faster in terms of wall-clock time. We demonstrate the effectiveness of $\texttt{ACCO}$ on several LLMs training and fine-tuning tasks.
$μ$LO: Compute-Efficient Meta-Generalization of Learned Optimizers
May 31, 2024



Learned optimizers (LOs) can significantly reduce the wall-clock training time of neural networks, substantially reducing training costs. However, they often suffer from poor meta-generalization, especially when training networks larger than those seen during meta-training. To address this, we use the recently proposed Maximal Update Parametrization ($\mu$P), which allows zero-shot generalization of optimizer hyperparameters from smaller to larger models. We extend $\mu$P theory to learned optimizers, treating the meta-training problem as finding the learned optimizer under $\mu$P. Our evaluation shows that LOs meta-trained with $\mu$P substantially improve meta-generalization as compared to LOs trained under standard parametrization (SP). Notably, when applied to large-width models, our best $\mu$LO, trained for 103 GPU-hours, matches or exceeds the performance of VeLO, the largest publicly available learned optimizer, meta-trained with 4000 TPU-months of compute. Moreover, $\mu$LOs demonstrate better generalization than their SP counterparts to deeper networks and to much longer training horizons (25 times longer) than those seen during meta-training.
WASH: Train your Ensemble with Communication-Efficient Weight Shuffling, then Average
May 27, 2024



The performance of deep neural networks is enhanced by ensemble methods, which average the output of several models. However, this comes at an increased cost at inference. Weight averaging methods aim at balancing the generalization of ensembling and the inference speed of a single model by averaging the parameters of an ensemble of models. Yet, naive averaging results in poor performance as models converge to different loss basins, and aligning the models to improve the performance of the average is challenging. Alternatively, inspired by distributed training, methods like DART and PAPA have been proposed to train several models in parallel such that they will end up in the same basin, resulting in good averaging accuracy. However, these methods either compromise ensembling accuracy or demand significant communication between models during training. In this paper, we introduce WASH, a novel distributed method for training model ensembles for weight averaging that achieves state-of-the-art image classification accuracy. WASH maintains models within the same basin by randomly shuffling a small percentage of weights during training, resulting in diverse models and lower communication costs compared to standard parameter averaging methods.