 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-time Generalization for Physics through Neural Operator Splitting
Jan 31, 2026Neural operators have shown promise in learning solution maps of partial differential equations (PDEs), but they often struggle to generalize when test inputs lie outside the training distribution, such as novel initial conditions, unseen PDE coefficients or unseen physics. Prior works address this limitation with large-scale multiple physics pretraining followed by fine-tuning, but this still requires examples from the new dynamics, falling short of true zero-shot generalization. In this work, we propose a method to enhance generalization at test time, i.e., without modifying pretrained weights. Building on DISCO, which provides a dictionary of neural operators trained across different dynamics, we introduce a neural operator splitting strategy that, at test time, searches over compositions of training operators to approximate unseen dynamics. On challenging out-of-distribution tasks including parameter extrapolation and novel combinations of physics phenomena, our approach achieves state-of-the-art zero-shot generalization results, while being able to recover the underlying PDE parameters. These results underscore test-time computation as a key avenue for building flexible, compositional, and generalizable neural operators.
ENMA: Tokenwise Autoregression for Generative Neural PDE Operators
Jun 06, 2025Solving time-dependent parametric partial differential equations (PDEs) remains a fundamental challenge for neural solvers, particularly when generalizing across a wide range of physical parameters and dynamics. When data is uncertain or incomplete-as is often the case-a natural approach is to turn to generative models. We introduce ENMA, a generative neural operator designed to model spatio-temporal dynamics arising from physical phenomena. ENMA predicts future dynamics in a compressed latent space using a generative masked autoregressive transformer trained with flow matching loss, enabling tokenwise generation. Irregularly sampled spatial observations are encoded into uniform latent representations via attention mechanisms and further compressed through a spatio-temporal convolutional encoder. This allows ENMA to perform in-context learning at inference time by conditioning on either past states of the target trajectory or auxiliary context trajectories with similar dynamics. The result is a robust and adaptable framework that generalizes to new PDE regimes and supports one-shot surrogate modeling of time-dependent parametric PDEs.
Learning a Neural Solver for Parametric PDE to Enhance Physics-Informed Methods
Oct 09, 2024

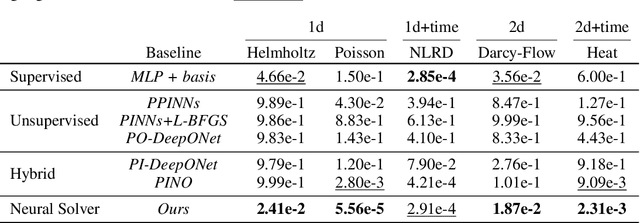
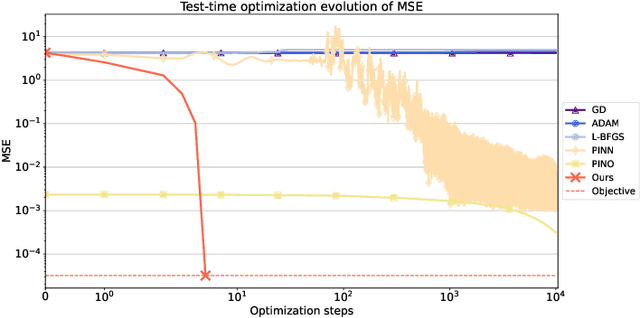
Physics-informed deep learning often faces optimization challenges due to the complexity of solving partial differential equations (PDEs), which involve exploring large solution spaces, require numerous iterations, and can lead to unstable training. These challenges arise particularly from the ill-conditioning of the optimization problem, caused by the differential terms in the loss function. To address these issues, we propose learning a solver, i.e., solving PDEs using a physics-informed iterative algorithm trained on data. Our method learns to condition a gradient descent algorithm that automatically adapts to each PDE instance, significantly accelerating and stabilizing the optimization process and enabling faster convergence of physics-aware models. Furthermore, while traditional physics-informed methods solve for a single PDE instance, our approach addresses parametric PDEs. Specifically, our method integrates the physical loss gradient with the PDE parameters to solve over a distribution of PDE parameters, including coefficients, initial conditions, or boundary conditions. We demonstrate the effectiveness of our method through empirical experiments on multiple datasets, comparing training and test-time optimization performance.
Zebra: In-Context and Generative Pretraining for Solving Parametric PDEs
Oct 04, 2024
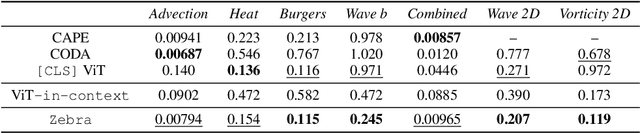
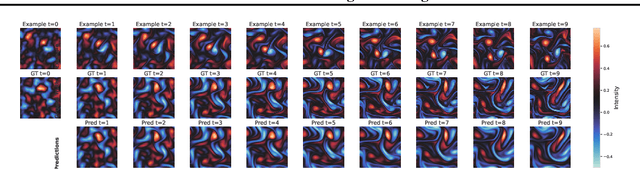
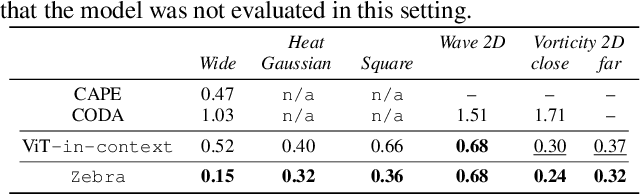
Solving time-dependent parametric partial differential equations (PDEs) is challenging, as models must adapt to variations in parameters such as coefficients, forcing terms, and boundary conditions. Data-driven neural solvers either train on data sampled from the PDE parameters distribution in the hope that the model generalizes to new instances or rely on gradient-based adaptation and meta-learning to implicitly encode the dynamics from observations. This often comes with increased inference complexity. Inspired by the in-context learning capabilities of large language models (LLMs), we introduce Zebra, a novel generative auto-regressive transformer designed to solve parametric PDEs without requiring gradient adaptation at inference. By leveraging in-context information during both pre-training and inference, Zebra dynamically adapts to new tasks by conditioning on input sequences that incorporate context trajectories or preceding states. This approach enables Zebra to flexibly handle arbitrarily sized context inputs and supports uncertainty quantification through the sampling of multiple solution trajectories. We evaluate Zebra across a variety of challenging PDE scenarios, demonstrating its adaptability, robustness, and superior performance compared to existing approaches.
AROMA: Preserving Spatial Structure for Latent PDE Modeling with Local Neural Fields
Jun 04, 2024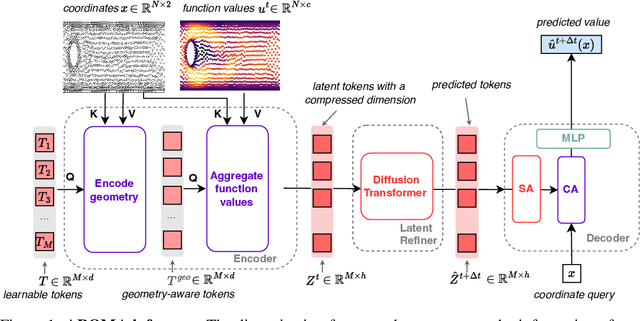
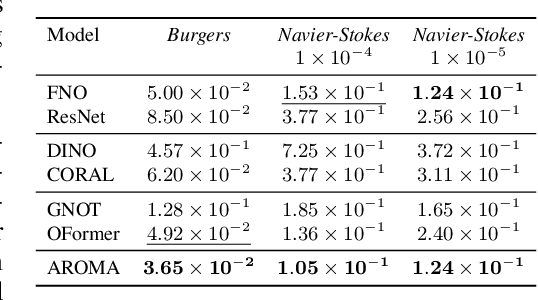
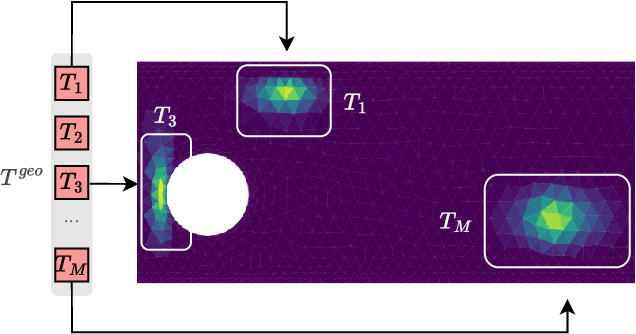
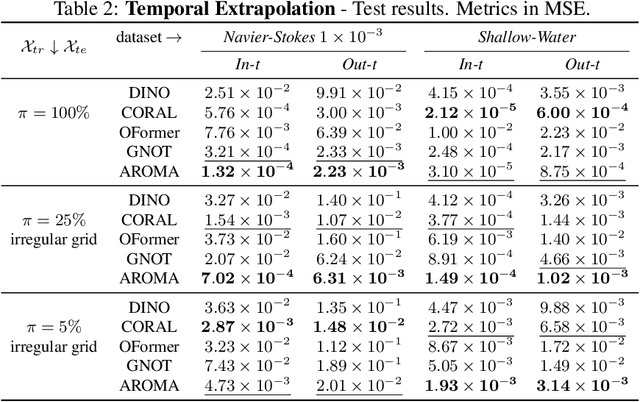
We present AROMA (Attentive Reduced Order Model with Attention), a framework designed to enhance the modeling of partial differential equations (PDEs) using local neural fields. Our flexible encoder-decoder architecture can obtain smooth latent representations of spatial physical fields from a variety of data types, including irregular-grid inputs and point clouds. This versatility eliminates the need for patching and allows efficient processing of diverse geometries. The sequential nature of our latent representation can be interpreted spatially and permits the use of a conditional transformer for modeling the temporal dynamics of PDEs. By employing a diffusion-based formulation, we achieve greater stability and enable longer rollouts compared to conventional MSE training. AROMA's superior performance in simulating 1D and 2D equations underscores the efficacy of our approach in capturing complex dynamical behaviors.
ACCO: Accumulate while you Communicate, Hiding Communications in Distributed LLM Training
Jun 03, 2024


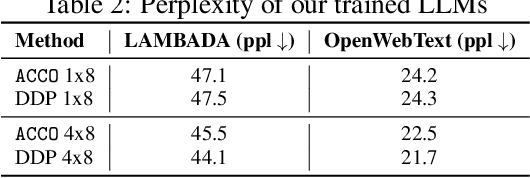
Training Large Language Models (LLMs) relies heavily on distributed implementations, employing multiple GPUs to compute stochastic gradients on model replicas in parallel. However, synchronizing gradients in data parallel settings induces a communication overhead increasing with the number of distributed workers, which can impede the efficiency gains of parallelization. To address this challenge, optimization algorithms reducing inter-worker communication have emerged, such as local optimization methods used in Federated Learning. While effective in minimizing communication overhead, these methods incur significant memory costs, hindering scalability: in addition to extra momentum variables, if communications are only allowed between multiple local optimization steps, then the optimizer's states cannot be sharded among workers. In response, we propose $\textbf{AC}$cumulate while $\textbf{CO}$mmunicate ($\texttt{ACCO}$), a memory-efficient optimization algorithm tailored for distributed training of LLMs. $\texttt{ACCO}$ allows to shard optimizer states across workers, overlaps gradient computations and communications to conceal communication costs, and accommodates heterogeneous hardware. Our method relies on a novel technique to mitigate the one-step delay inherent in parallel execution of gradient computations and communications, eliminating the need for warmup steps and aligning with the training dynamics of standard distributed optimization while converging faster in terms of wall-clock time. We demonstrate the effectiveness of $\texttt{ACCO}$ on several LLMs training and fine-tuning tasks.
INFINITY: Neural Field Modeling for Reynolds-Averaged Navier-Stokes Equations
Jul 25, 2023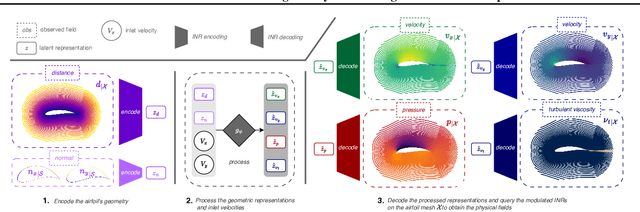
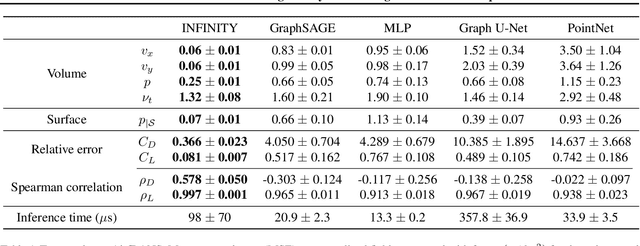
For numerical design, the development of efficient and accurate surrogate models is paramount. They allow us to approximate complex physical phenomena, thereby reducing the computational burden of direct numerical simulations. We propose INFINITY, a deep learning model that utilizes implicit neural representations (INRs) to address this challenge. Our framework encodes geometric information and physical fields into compact representations and learns a mapping between them to infer the physical fields. We use an airfoil design optimization problem as an example task and we evaluate our approach on the challenging AirfRANS dataset, which closely resembles real-world industrial use-cases. The experimental results demonstrate that our framework achieves state-of-the-art performance by accurately inferring physical fields throughout the volume and surface. Additionally we demonstrate its applicability in contexts such as design exploration and shape optimization: our model can correctly predict drag and lift coefficients while adhering to the equations.
* ICML 2023 Workshop on Synergy of Scientific and Machine Learning Modeling
Time Series Continuous Modeling for Imputation and Forecasting with Implicit Neural Representations
Jun 12, 2023Although widely explored, time series modeling continues to encounter significant challenges when confronted with real-world data. We propose a novel modeling approach leveraging Implicit Neural Representations (INR). This approach enables us to effectively capture the continuous aspect of time series and provides a natural solution to recurring modeling issues such as handling missing data, dealing with irregular sampling, or unaligned observations from multiple sensors. By introducing conditional modulation of INR parameters and leveraging meta-learning techniques, we address the issue of generalization to both unseen samples and time window shifts. Through extensive experimentation, our model demonstrates state-of-the-art performance in forecasting and imputation tasks, while exhibiting flexibility in handling a wide range of challenging scenarios that competing models cannot.
Operator Learning with Neural Fields: Tackling PDEs on General Geometries
Jun 12, 2023



Machine learning approaches for solving partial differential equations require learning mappings between function spaces. While convolutional or graph neural networks are constrained to discretized functions, neural operators present a promising milestone toward mapping functions directly. Despite impressive results they still face challenges with respect to the domain geometry and typically rely on some form of discretization. In order to alleviate such limitations, we present CORAL, a new method that leverages coordinate-based networks for solving PDEs on general geometries. CORAL is designed to remove constraints on the input mesh, making it applicable to any spatial sampling and geometry. Its ability extends to diverse problem domains, including PDE solving, spatio-temporal forecasting, and inverse problems like geometric design. CORAL demonstrates robust performance across multiple resolutions and performs well in both convex and non-convex domains, surpassing or performing on par with state-of-the-art models.