 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaST: Feature-aware Sampling and Tuning for Personalized Preference Alignment with Limited Data
Aug 06, 2025LLM-powered conversational assistants are often deployed in a one-size-fits-all manner, which fails to accommodate individual user preferences. Recently, LLM personalization -- tailoring models to align with specific user preferences -- has gained increasing attention as a way to bridge this gap. In this work, we specifically focus on a practical yet challenging setting where only a small set of preference annotations can be collected per user -- a problem we define as Personalized Preference Alignment with Limited Data (PPALLI). To support research in this area, we introduce two datasets -- DnD and ELIP -- and benchmark a variety of alignment techniques on them. We further propose FaST, a highly parameter-efficient approach that leverages high-level features automatically discovered from the data, achieving the best overall performance.
Zebra: In-Context and Generative Pretraining for Solving Parametric PDEs
Oct 04, 2024
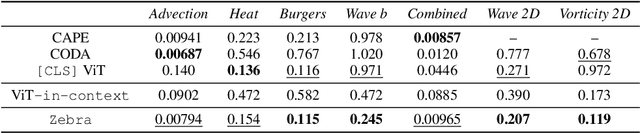
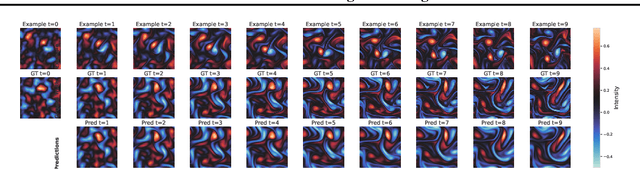
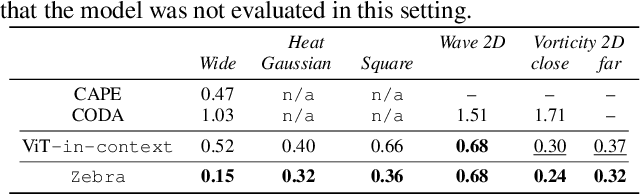
Solving time-dependent parametric partial differential equations (PDEs) is challenging, as models must adapt to variations in parameters such as coefficients, forcing terms, and boundary conditions. Data-driven neural solvers either train on data sampled from the PDE parameters distribution in the hope that the model generalizes to new instances or rely on gradient-based adaptation and meta-learning to implicitly encode the dynamics from observations. This often comes with increased inference complexity. Inspired by the in-context learning capabilities of large language models (LLMs), we introduce Zebra, a novel generative auto-regressive transformer designed to solve parametric PDEs without requiring gradient adaptation at inference. By leveraging in-context information during both pre-training and inference, Zebra dynamically adapts to new tasks by conditioning on input sequences that incorporate context trajectories or preceding states. This approach enables Zebra to flexibly handle arbitrarily sized context inputs and supports uncertainty quantification through the sampling of multiple solution trajectories. We evaluate Zebra across a variety of challenging PDE scenarios, demonstrating its adaptability, robustness, and superior performance compared to existing approaches.
An Evaluation Framework for Attributed Information Retrieval using Large Language Models
Sep 12, 2024With the growing success of Large Language models (LLMs) in information-seeking scenarios, search engines are now adopting generative approaches to provide answers along with in-line citations as attribution. While existing work focuses mainly on attributed question answering, in this paper, we target information-seeking scenarios which are often more challenging due to the open-ended nature of the queries and the size of the label space in terms of the diversity of candidate-attributed answers per query. We propose a reproducible framework to evaluate and benchmark attributed information seeking, using any backbone LLM, and different architectural designs: (1) Generate (2) Retrieve then Generate, and (3) Generate then Retrieve. Experiments using HAGRID, an attributed information-seeking dataset, show the impact of different scenarios on both the correctness and attributability of answers.
ACCO: Accumulate while you Communicate, Hiding Communications in Distributed LLM Training
Jun 03, 2024


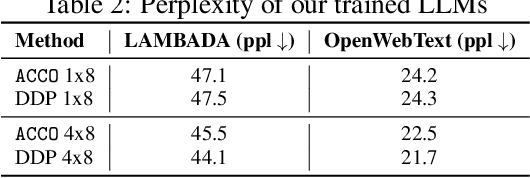
Training Large Language Models (LLMs) relies heavily on distributed implementations, employing multiple GPUs to compute stochastic gradients on model replicas in parallel. However, synchronizing gradients in data parallel settings induces a communication overhead increasing with the number of distributed workers, which can impede the efficiency gains of parallelization. To address this challenge, optimization algorithms reducing inter-worker communication have emerged, such as local optimization methods used in Federated Learning. While effective in minimizing communication overhead, these methods incur significant memory costs, hindering scalability: in addition to extra momentum variables, if communications are only allowed between multiple local optimization steps, then the optimizer's states cannot be sharded among workers. In response, we propose $\textbf{AC}$cumulate while $\textbf{CO}$mmunicate ($\texttt{ACCO}$), a memory-efficient optimization algorithm tailored for distributed training of LLMs. $\texttt{ACCO}$ allows to shard optimizer states across workers, overlaps gradient computations and communications to conceal communication costs, and accommodates heterogeneous hardware. Our method relies on a novel technique to mitigate the one-step delay inherent in parallel execution of gradient computations and communications, eliminating the need for warmup steps and aligning with the training dynamics of standard distributed optimization while converging faster in terms of wall-clock time. We demonstrate the effectiveness of $\texttt{ACCO}$ on several LLMs training and fine-tuning tasks.
PAQA: Toward ProActive Open-Retrieval Question Answering
Feb 26, 2024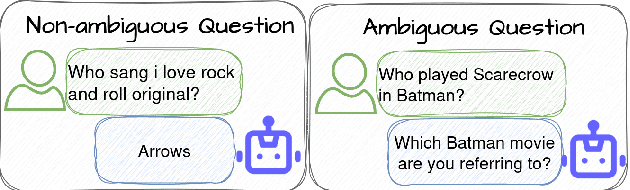

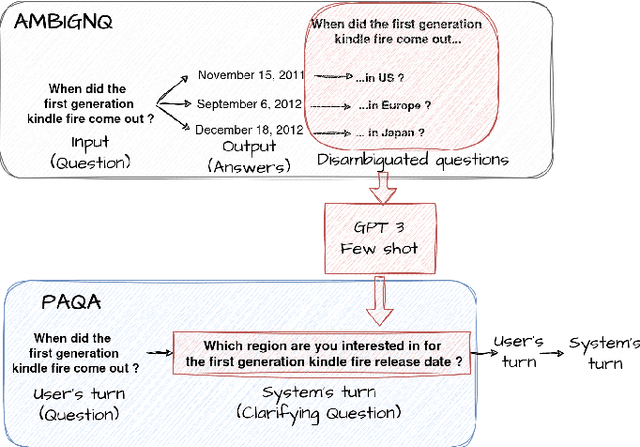
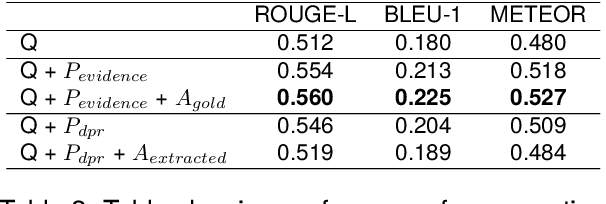
Conversational systems have made significant progress in generating natural language responses. However, their potential as conversational search systems is currently limited due to their passive role in the information-seeking process. One major limitation is the scarcity of datasets that provide labelled ambiguous questions along with a supporting corpus of documents and relevant clarifying questions. This work aims to tackle the challenge of generating relevant clarifying questions by taking into account the inherent ambiguities present in both user queries and documents. To achieve this, we propose PAQA, an extension to the existing AmbiNQ dataset, incorporating clarifying questions. We then evaluate various models and assess how passage retrieval impacts ambiguity detection and the generation of clarifying questions. By addressing this gap in conversational search systems, we aim to provide additional supervision to enhance their active participation in the information-seeking process and provide users with more accurate results.
Navigating Uncertainty: Optimizing API Dependency for Hallucination Reduction in Closed-Book Question Answering
Jan 03, 2024



While Large Language Models (LLM) are able to accumulate and restore knowledge, they are still prone to hallucination. Especially when faced with factual questions, LLM cannot only rely on knowledge stored in parameters to guarantee truthful and correct answers. Augmenting these models with the ability to search on external information sources, such as the web, is a promising approach to ground knowledge to retrieve information. However, searching in a large collection of documents introduces additional computational/time costs. An optimal behavior would be to query external resources only when the LLM is not confident about answers. In this paper, we propose a new LLM able to self-estimate if it is able to answer directly or needs to request an external tool. We investigate a supervised approach by introducing a hallucination masking mechanism in which labels are generated using a close book question-answering task. In addition, we propose to leverage parameter-efficient fine-tuning techniques to train our model on a small amount of data. Our model directly provides answers for $78.2\%$ of the known queries and opts to search for $77.2\%$ of the unknown ones. This results in the API being utilized only $62\%$ of the time.
Augmenting Ad-Hoc IR Dataset for Interactive Conversational Search
Nov 10, 2023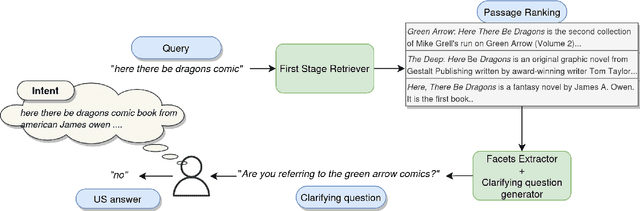
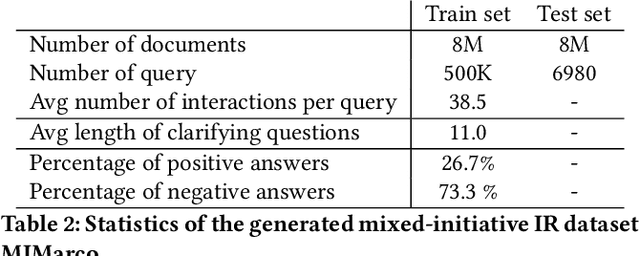
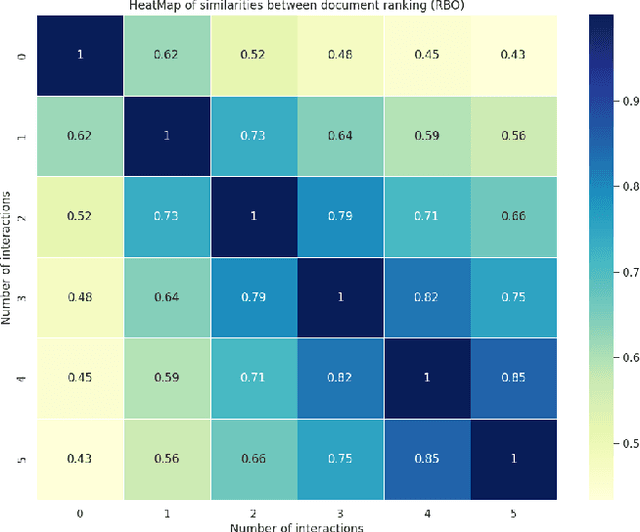
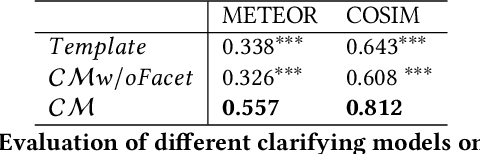
A peculiarity of conversational search systems is that they involve mixed-initiatives such as system-generated query clarifying questions. Evaluating those systems at a large scale on the end task of IR is very challenging, requiring adequate datasets containing such interactions. However, current datasets only focus on either traditional ad-hoc IR tasks or query clarification tasks, the latter being usually seen as a reformulation task from the initial query. The only two datasets known to us that contain both document relevance judgments and the associated clarification interactions are Qulac and ClariQ. Both are based on the TREC Web Track 2009-12 collection, but cover a very limited number of topics (237 topics), far from being enough for training and testing conversational IR models. To fill the gap, we propose a methodology to automatically build large-scale conversational IR datasets from ad-hoc IR datasets in order to facilitate explorations on conversational IR. Our methodology is based on two processes: 1) generating query clarification interactions through query clarification and answer generators, and 2) augmenting ad-hoc IR datasets with simulated interactions. In this paper, we focus on MsMarco and augment it with query clarification and answer simulations. We perform a thorough evaluation showing the quality and the relevance of the generated interactions for each initial query. This paper shows the feasibility and utility of augmenting ad-hoc IR datasets for conversational IR.
CIRCLE: Multi-Turn Query Clarifications with Reinforcement Learning
Nov 05, 2023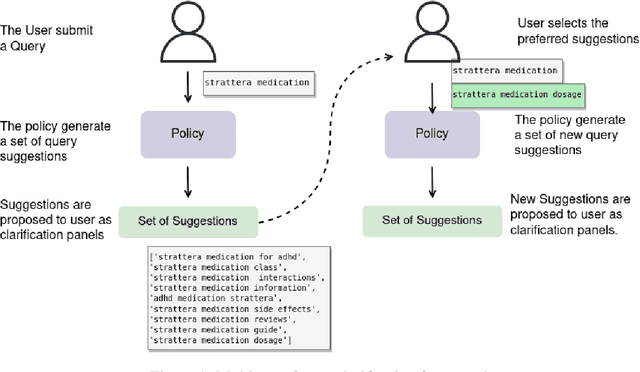
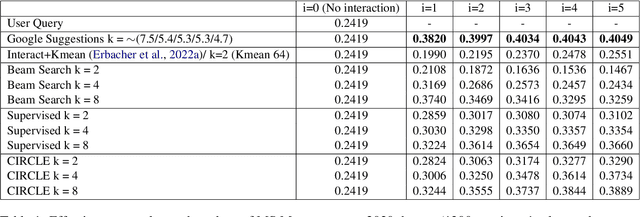
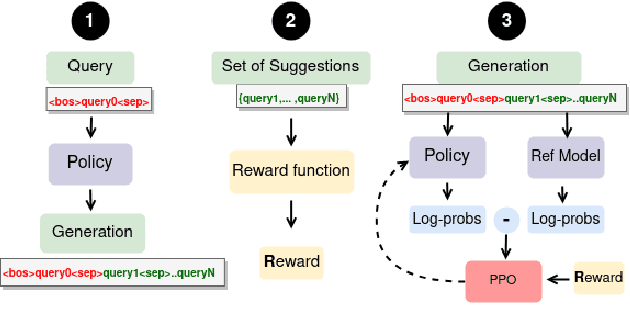

Users often have trouble formulating their information needs into words on the first try when searching online. This can lead to frustration, as they may have to reformulate their queries when retrieved information is not relevant. This can be due to a lack of familiarity with the specific terminology related to their search topic, or because queries are ambiguous and related to multiple topics. Most modern search engines have interactive features that suggest clarifications or similar queries based on what others have searched for. However, the proposed models are either based on a single interaction or evaluated on search logs, hindering the naturalness of the interactions. In this paper, we introduce CIRCLE, a generative model for multi-turn query Clarifications wIth ReinforCement LEarning that leverages multi-turn interactions through a user simulation framework. Our model aims at generating a diverse set of query clarifications using a pretrained language model fine-tuned using reinforcement learning. We evaluate it against well established google suggestions using a user simulation framework.
Interactive Query Clarification and Refinement via User Simulation
May 31, 2022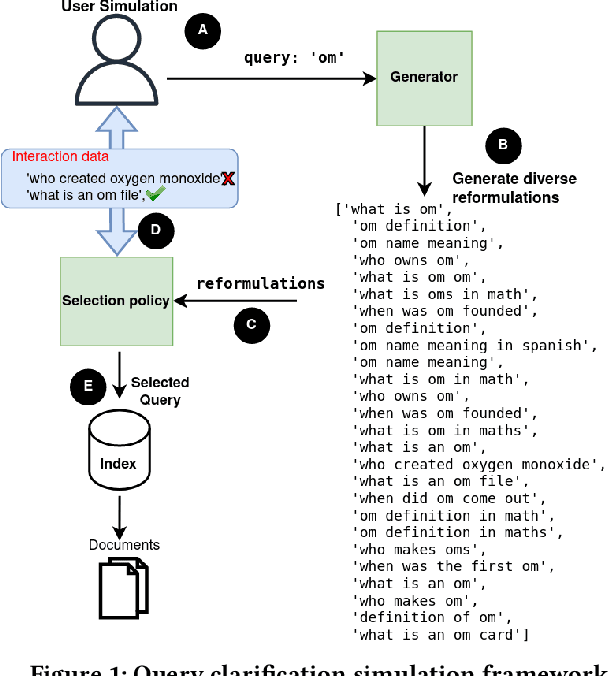
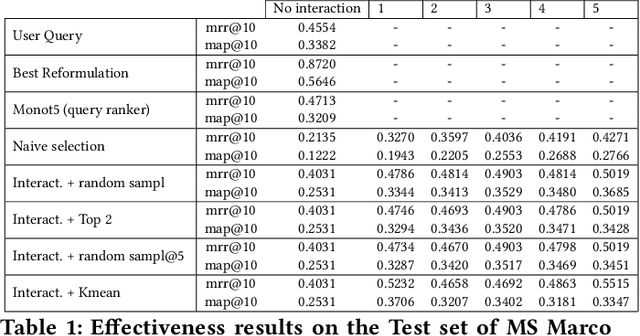
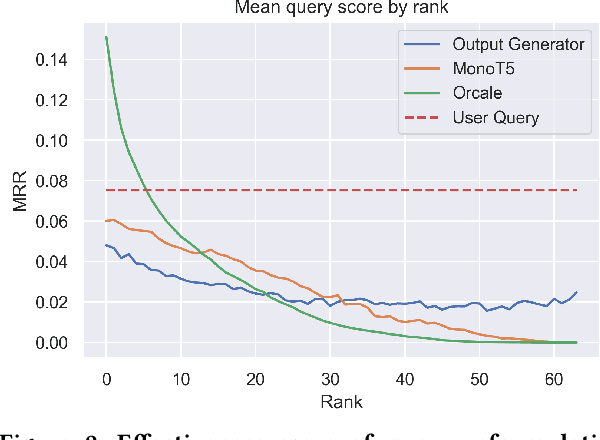
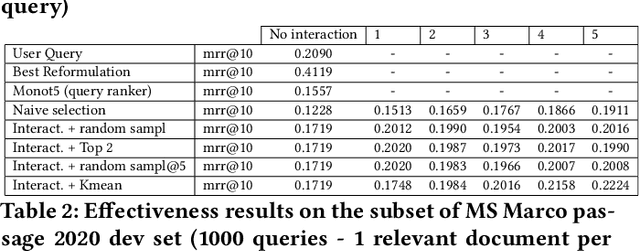
When users initiate search sessions, their queries are often unclear or might lack of context; this resulting in inefficient document ranking. Multiple approaches have been proposed by the Information Retrieval community to add context and retrieve documents aligned with users' intents. While some work focus on query disambiguation using users' browsing history, a recent line of work proposes to interact with users by asking clarification questions or/and proposing clarification panels. However, these approaches count either a limited number (i.e., 1) of interactions with user or log-based interactions. In this paper, we propose and evaluate a fully simulated query clarification framework allowing multi-turn interactions between IR systems and user agents.
State of the Art of User Simulation approaches for conversational information retrieval
Jan 10, 2022Conversational Information Retrieval (CIR) is an emerging field of Information Retrieval (IR) at the intersection of interactive IR and dialogue systems for open domain information needs. In order to optimize these interactions and enhance the user experience, it is necessary to improve IR models by taking into account sequential heterogeneous user-system interactions. Reinforcement learning has emerged as a paradigm particularly suited to optimize sequential decision making in many domains and has recently appeared in IR. However, training these systems by reinforcement learning on users is not feasible. One solution is to train IR systems on user simulations that model the behavior of real users. Our contribution is twofold: 1)reviewing the literature on user modeling and user simulation for information access, and 2) discussing the different research perspectives for user simulations in the context of CIR