 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Learning of Controllable Diverse Behaviors
Apr 25, 2025Imitation Learning (IL) techniques aim to replicate human behaviors in specific tasks. While IL has gained prominence due to its effectiveness and efficiency, traditional methods often focus on datasets collected from experts to produce a single efficient policy. Recently, extensions have been proposed to handle datasets of diverse behaviors by mainly focusing on learning transition-level diverse policies or on performing entropy maximization at the trajectory level. While these methods may lead to diverse behaviors, they may not be sufficient to reproduce the actual diversity of demonstrations or to allow controlled trajectory generation. To overcome these drawbacks, we propose a different method based on two key features: a) Temporal Consistency that ensures consistent behaviors across entire episodes and not just at the transition level as well as b) Controllability obtained by constructing a latent space of behaviors that allows users to selectively activate specific behaviors based on their requirements. We compare our approach to state-of-the-art methods over a diverse set of tasks and environments. Project page: https://mathieu-petitbois.github.io/projects/swr/
Hierarchical Subspaces of Policies for Continual Offline Reinforcement Learning
Dec 19, 2024



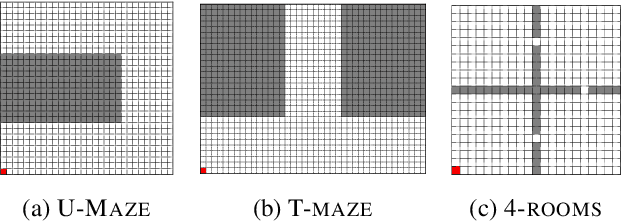
In dynamic domains such as autonomous robotics and video game simulations, agents must continuously adapt to new tasks while retaining previously acquired skills. This ongoing process, known as Continual Reinforcement Learning, presents significant challenges, including the risk of forgetting past knowledge and the need for scalable solutions as the number of tasks increases. To address these issues, we introduce HIerarchical LOW-rank Subspaces of Policies (HILOW), a novel framework designed for continual learning in offline navigation settings. HILOW leverages hierarchical policy subspaces to enable flexible and efficient adaptation to new tasks while preserving existing knowledge. We demonstrate, through a careful experimental study, the effectiveness of our method in both classical MuJoCo maze environments and complex video game-like simulations, showcasing competitive performance and satisfying adaptability according to classical continual learning metrics, in particular regarding memory usage. Our work provides a promising framework for real-world applications where continuous learning from pre-collected data is essential.
Navigation with QPHIL: Quantizing Planner for Hierarchical Implicit Q-Learning
Nov 12, 2024



Offline Reinforcement Learning (RL) has emerged as a powerful alternative to imitation learning for behavior modeling in various domains, particularly in complex navigation tasks. An existing challenge with Offline RL is the signal-to-noise ratio, i.e. how to mitigate incorrect policy updates due to errors in value estimates. Towards this, multiple works have demonstrated the advantage of hierarchical offline RL methods, which decouples high-level path planning from low-level path following. In this work, we present a novel hierarchical transformer-based approach leveraging a learned quantizer of the space. This quantization enables the training of a simpler zone-conditioned low-level policy and simplifies planning, which is reduced to discrete autoregressive prediction. Among other benefits, zone-level reasoning in planning enables explicit trajectory stitching rather than implicit stitching based on noisy value function estimates. By combining this transformer-based planner with recent advancements in offline RL, our proposed approach achieves state-of-the-art results in complex long-distance navigation environments.
Efficient Active Imitation Learning with Random Network Distillation
Nov 04, 2024



Developing agents for complex and underspecified tasks, where no clear objective exists, remains challenging but offers many opportunities. This is especially true in video games, where simulated players (bots) need to play realistically, and there is no clear reward to evaluate them. While imitation learning has shown promise in such domains, these methods often fail when agents encounter out-of-distribution scenarios during deployment. Expanding the training dataset is a common solution, but it becomes impractical or costly when relying on human demonstrations. This article addresses active imitation learning, aiming to trigger expert intervention only when necessary, reducing the need for constant expert input along training. We introduce Random Network Distillation DAgger (RND-DAgger), a new active imitation learning method that limits expert querying by using a learned state-based out-of-distribution measure to trigger interventions. This approach avoids frequent expert-agent action comparisons, thus making the expert intervene only when it is useful. We evaluate RND-DAgger against traditional imitation learning and other active approaches in 3D video games (racing and third-person navigation) and in a robotic locomotion task and show that RND-DAgger surpasses previous methods by reducing expert queries. https://sites.google.com/view/rnd-dagger
Policy Diversity for Cooperative Agents
Aug 28, 2023
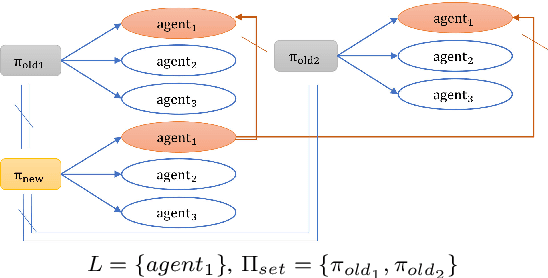


Standard cooperative multi-agent reinforcement learning (MARL) methods aim to find the optimal team cooperative policy to complete a task. However there may exist multiple different ways of cooperating, which usually are very needed by domain experts. Therefore, identifying a set of significantly different policies can alleviate the task complexity for them. Unfortunately, there is a general lack of effective policy diversity approaches specifically designed for the multi-agent domain. In this work, we propose a method called Moment-Matching Policy Diversity to alleviate this problem. This method can generate different team policies to varying degrees by formalizing the difference between team policies as the difference in actions of selected agents in different policies. Theoretically, we show that our method is a simple way to implement a constrained optimization problem that regularizes the difference between two trajectory distributions by using the maximum mean discrepancy. The effectiveness of our approach is demonstrated on a challenging team-based shooter.
Learning Computational Efficient Bots with Costly Features
Aug 18, 2023



Deep reinforcement learning (DRL) techniques have become increasingly used in various fields for decision-making processes. However, a challenge that often arises is the trade-off between both the computational efficiency of the decision-making process and the ability of the learned agent to solve a particular task. This is particularly critical in real-time settings such as video games where the agent needs to take relevant decisions at a very high frequency, with a very limited inference time. In this work, we propose a generic offline learning approach where the computation cost of the input features is taken into account. We derive the Budgeted Decision Transformer as an extension of the Decision Transformer that incorporates cost constraints to limit its cost at inference. As a result, the model can dynamically choose the best input features at each timestep. We demonstrate the effectiveness of our method on several tasks, including D4RL benchmarks and complex 3D environments similar to those found in video games, and show that it can achieve similar performance while using significantly fewer computational resources compared to classical approaches.
Building a Subspace of Policies for Scalable Continual Learning
Nov 18, 2022The ability to continuously acquire new knowledge and skills is crucial for autonomous agents. Existing methods are typically based on either fixed-size models that struggle to learn a large number of diverse behaviors, or growing-size models that scale poorly with the number of tasks. In this work, we aim to strike a better balance between an agent's size and performance by designing a method that grows adaptively depending on the task sequence. We introduce Continual Subspace of Policies (CSP), a new approach that incrementally builds a subspace of policies for training a reinforcement learning agent on a sequence of tasks. The subspace's high expressivity allows CSP to perform well for many different tasks while growing sublinearly with the number of tasks. Our method does not suffer from forgetting and displays positive transfer to new tasks. CSP outperforms a number of popular baselines on a wide range of scenarios from two challenging domains, Brax (locomotion) and Continual World (manipulation).
Regularized Soft Actor-Critic for Behavior Transfer Learning
Sep 27, 2022
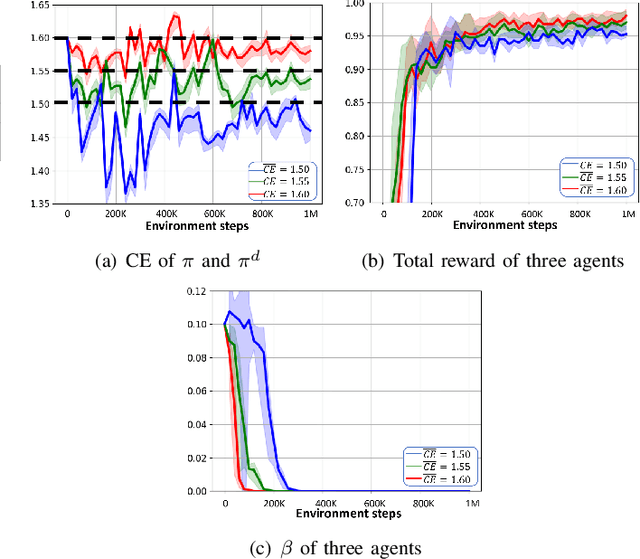
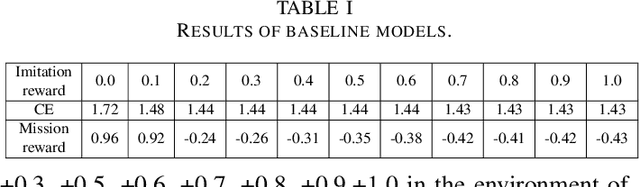
Existing imitation learning methods mainly focus on making an agent effectively mimic a demonstrated behavior, but do not address the potential contradiction between the behavior style and the objective of a task. There is a general lack of efficient methods that allow an agent to partially imitate a demonstrated behavior to varying degrees, while completing the main objective of a task. In this paper we propose a method called Regularized Soft Actor-Critic which formulates the main task and the imitation task under the Constrained Markov Decision Process framework (CMDP). The main task is defined as the maximum entropy objective used in Soft Actor-Critic (SAC) and the imitation task is defined as a constraint. We evaluate our method on continuous control tasks relevant to video games applications.
Interactive Query Clarification and Refinement via User Simulation
May 31, 2022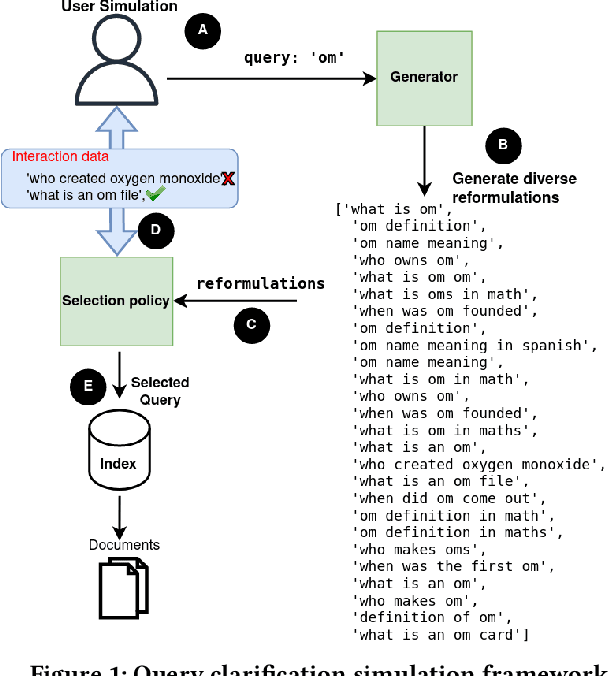
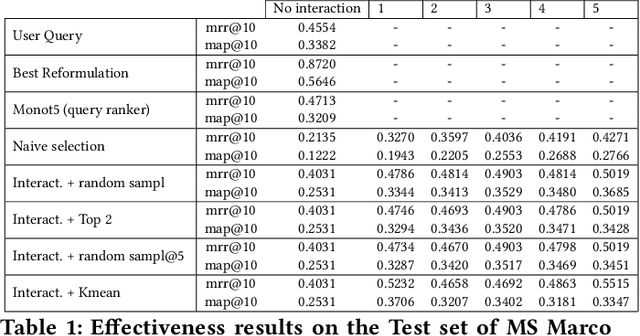
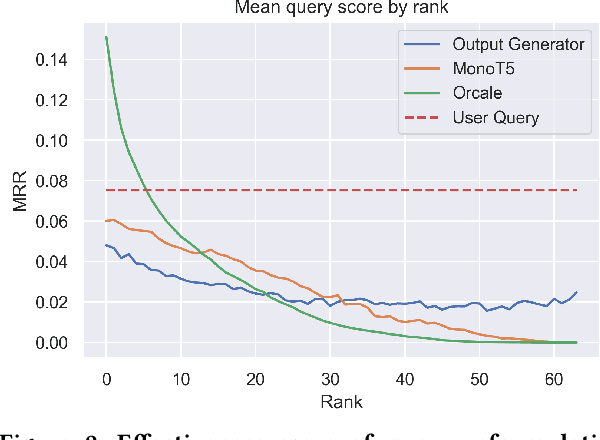
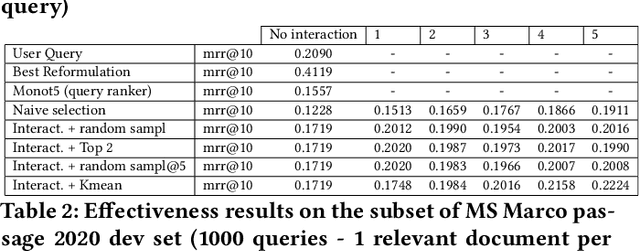
When users initiate search sessions, their queries are often unclear or might lack of context; this resulting in inefficient document ranking. Multiple approaches have been proposed by the Information Retrieval community to add context and retrieve documents aligned with users' intents. While some work focus on query disambiguation using users' browsing history, a recent line of work proposes to interact with users by asking clarification questions or/and proposing clarification panels. However, these approaches count either a limited number (i.e., 1) of interactions with user or log-based interactions. In this paper, we propose and evaluate a fully simulated query clarification framework allowing multi-turn interactions between IR systems and user agents.
Temporal Abstractions-Augmented Temporally Contrastive Learning: An Alternative to the Laplacian in RL
Mar 21, 2022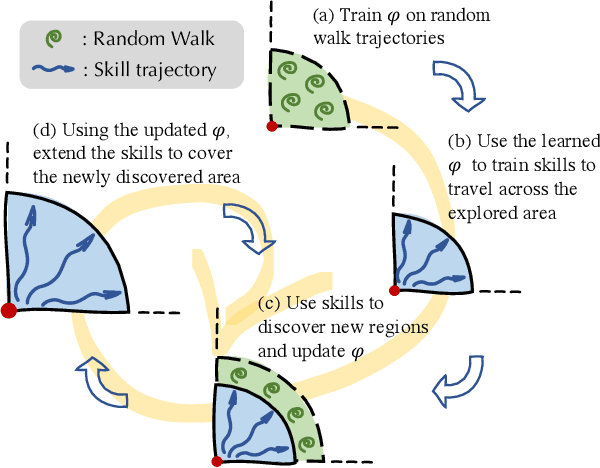

In reinforcement learning, the graph Laplacian has proved to be a valuable tool in the task-agnostic setting, with applications ranging from skill discovery to reward shaping. Recently, learning the Laplacian representation has been framed as the optimization of a temporally-contrastive objective to overcome its computational limitations in large (or continuous) state spaces. However, this approach requires uniform access to all states in the state space, overlooking the exploration problem that emerges during the representation learning process. In this work, we propose an alternative method that is able to recover, in a non-uniform-prior setting, the expressiveness and the desired properties of the Laplacian representation. We do so by combining the representation learning with a skill-based covering policy, which provides a better training distribution to extend and refine the representation. We also show that a simple augmentation of the representation objective with the learned temporal abstractions improves dynamics-awareness and helps exploration. We find that our method succeeds as an alternative to the Laplacian in the non-uniform setting and scales to challenging continuous control environments. Finally, even if our method is not optimized for skill discovery, the learned skills can successfully solve difficult continuous navigation tasks with sparse rewards, where standard skill discovery approaches are no so effective.