 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularized Soft Actor-Critic for Behavior Transfer Learning
Paper and Code
Sep 27, 2022
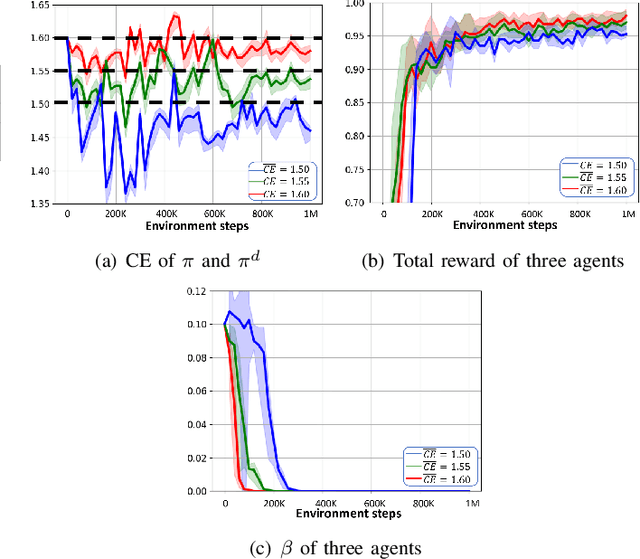
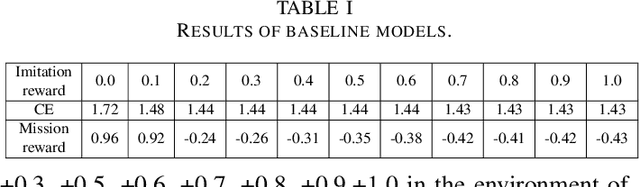
Existing imitation learning methods mainly focus on making an agent effectively mimic a demonstrated behavior, but do not address the potential contradiction between the behavior style and the objective of a task. There is a general lack of efficient methods that allow an agent to partially imitate a demonstrated behavior to varying degrees, while completing the main objective of a task. In this paper we propose a method called Regularized Soft Actor-Critic which formulates the main task and the imitation task under the Constrained Markov Decision Process framework (CMDP). The main task is defined as the maximum entropy objective used in Soft Actor-Critic (SAC) and the imitation task is defined as a constraint. We evaluate our method on continuous control tasks relevant to video games applications.