 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimax Exploiter: A Data Efficient Approach for Competitive Self-Play
Nov 28, 2023Recent advances in Competitive Self-Play (CSP) have achieved, or even surpassed, human level performance in complex game environments such as Dota 2 and StarCraft II using Distributed Multi-Agent Reinforcement Learning (MARL). One core component of these methods relies on creating a pool of learning agents -- consisting of the Main Agent, past versions of this agent, and Exploiter Agents -- where Exploiter Agents learn counter-strategies to the Main Agents. A key drawback of these approaches is the large computational cost and physical time that is required to train the system, making them impractical to deploy in highly iterative real-life settings such as video game productions. In this paper, we propose the Minimax Exploiter, a game theoretic approach to exploiting Main Agents that leverages knowledge of its opponents, leading to significant increases in data efficiency. We validate our approach in a diversity of settings, including simple turn based games, the arcade learning environment, and For Honor, a modern video game. The Minimax Exploiter consistently outperforms strong baselines, demonstrating improved stability and data efficiency, leading to a robust CSP-MARL method that is both flexible and easy to deploy.
Improving Intrinsic Exploration by Creating Stationary Objectives
Nov 03, 2023Exploration bonuses in reinforcement learning guide long-horizon exploration by defining custom intrinsic objectives. Count-based methods use the frequency of state visits to derive an exploration bonus. In this paper, we identify that any intrinsic reward function derived from count-based methods is non-stationary and hence induces a difficult objective to optimize for the agent. The key contribution of our work lies in transforming the original non-stationary rewards into stationary rewards through an augmented state representation. For this purpose, we introduce the Stationary Objectives For Exploration (SOFE) framework. SOFE requires identifying sufficient statistics for different exploration bonuses and finding an efficient encoding of these statistics to use as input to a deep network. SOFE is based on proposing state augmentations that expand the state space but hold the promise of simplifying the optimization of the agent's objective. Our experiments show that SOFE improves the agents' performance in challenging exploration problems, including sparse-reward tasks, pixel-based observations, 3D navigation, and procedurally generated environments.
Learning Computational Efficient Bots with Costly Features
Aug 18, 2023



Deep reinforcement learning (DRL) techniques have become increasingly used in various fields for decision-making processes. However, a challenge that often arises is the trade-off between both the computational efficiency of the decision-making process and the ability of the learned agent to solve a particular task. This is particularly critical in real-time settings such as video games where the agent needs to take relevant decisions at a very high frequency, with a very limited inference time. In this work, we propose a generic offline learning approach where the computation cost of the input features is taken into account. We derive the Budgeted Decision Transformer as an extension of the Decision Transformer that incorporates cost constraints to limit its cost at inference. As a result, the model can dynamically choose the best input features at each timestep. We demonstrate the effectiveness of our method on several tasks, including D4RL benchmarks and complex 3D environments similar to those found in video games, and show that it can achieve similar performance while using significantly fewer computational resources compared to classical approaches.
Direct Behavior Specification via Constrained Reinforcement Learning
Jan 19, 2022
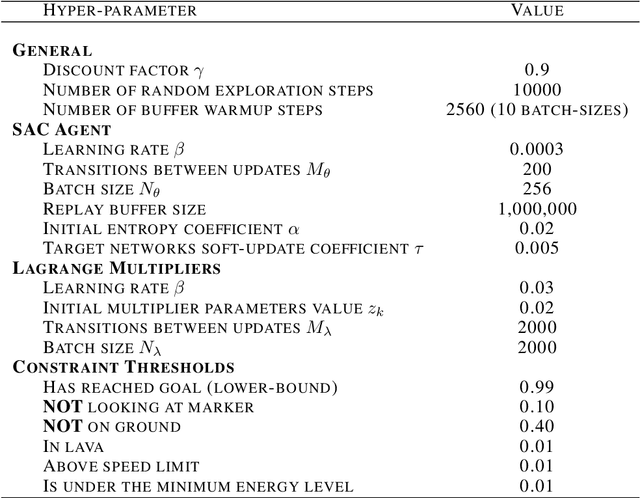
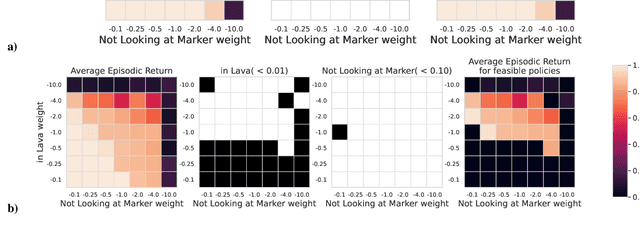

The standard formulation of Reinforcement Learning lacks a practical way of specifying what are admissible and forbidden behaviors. Most often, practitioners go about the task of behavior specification by manually engineering the reward function, a counter-intuitive process that requires several iterations and is prone to reward hacking by the agent. In this work, we argue that constrained RL, which has almost exclusively been used for safe RL, also has the potential to significantly reduce the amount of work spent for reward specification in applied RL projects. To this end, we propose to specify behavioral preferences in the CMDP framework and to use Lagrangian methods to automatically weigh each of these behavioral constraints. Specifically, we investigate how CMDPs can be adapted to solve goal-based tasks while adhering to several constraints simultaneously. We evaluate this framework on a set of continuous control tasks relevant to the application of Reinforcement Learning for NPC design in video games.
Graph augmented Deep Reinforcement Learning in the GameRLand3D environment
Dec 22, 2021


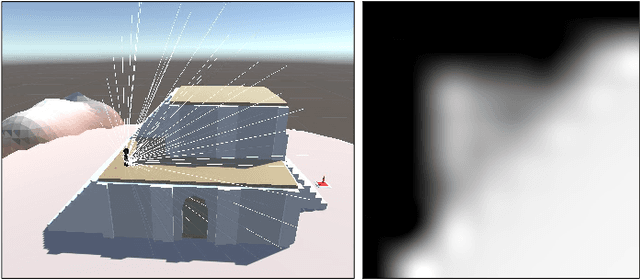
We address planning and navigation in challenging 3D video games featuring maps with disconnected regions reachable by agents using special actions. In this setting, classical symbolic planners are not applicable or difficult to adapt. We introduce a hybrid technique combining a low level policy trained with reinforcement learning and a graph based high level classical planner. In addition to providing human-interpretable paths, the approach improves the generalization performance of an end-to-end approach in unseen maps, where it achieves a 20% absolute increase in success rate over a recurrent end-to-end agent on a point to point navigation task in yet unseen large-scale maps of size 1km x 1km. In an in-depth experimental study, we quantify the limitations of end-to-end Deep RL approaches in vast environments and we also introduce "GameRLand3D", a new benchmark and soon to be released environment can generate complex procedural 3D maps for navigation tasks.
Deep Reinforcement Learning for Navigation in AAA Video Games
Nov 09, 2020
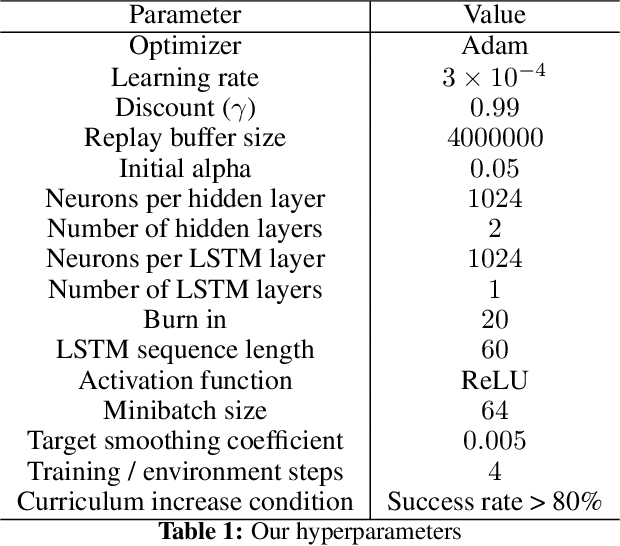
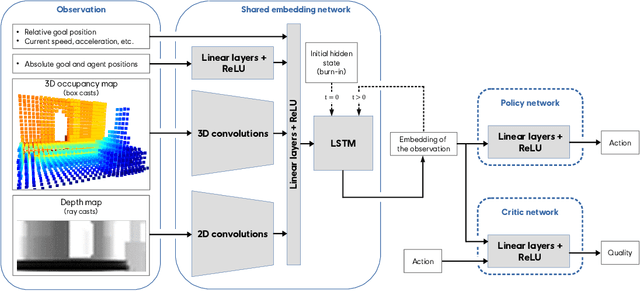
In video games, non-player characters (NPCs) are used to enhance the players' experience in a variety of ways, e.g., as enemies, allies, or innocent bystanders. A crucial component of NPCs is navigation, which allows them to move from one point to another on the map. The most popular approach for NPC navigation in the video game industry is to use a navigation mesh (NavMesh), which is a graph representation of the map, with nodes and edges indicating traversable areas. Unfortunately, complex navigation abilities that extend the character's capacity for movement, e.g., grappling hooks, jetpacks, teleportation, or double-jumps, increases the complexity of the NavMesh, making it intractable in many practical scenarios. Game designers are thus constrained to only add abilities that can be handled by a NavMesh if they want to have NPC navigation. As an alternative, we propose to use Deep Reinforcement Learning (Deep RL) to learn how to navigate 3D maps using any navigation ability. We test our approach on complex 3D environments in the Unity game engine that are notably an order of magnitude larger than maps typically used in the Deep RL literature. One of these maps is directly modeled after a Ubisoft AAA game. We find that our approach performs surprisingly well, achieving at least $90\%$ success rate on all tested scenarios. A video of our results is available at https://youtu.be/WFIf9Wwlq8M.
TDprop: Does Jacobi Preconditioning Help Temporal Difference Learning?
Jul 06, 2020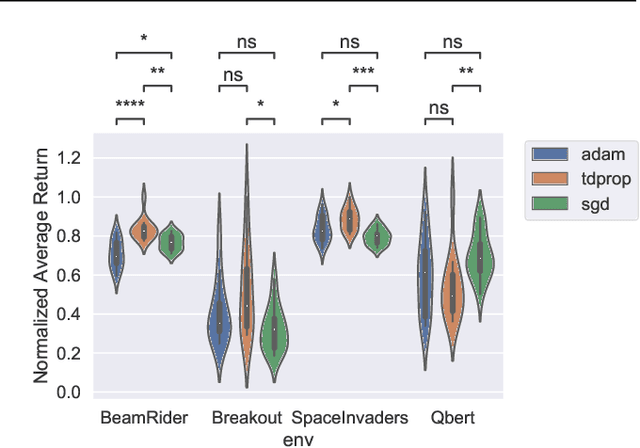

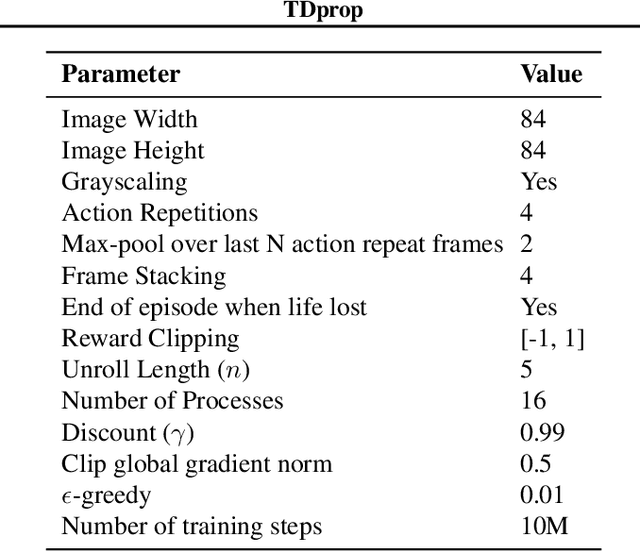
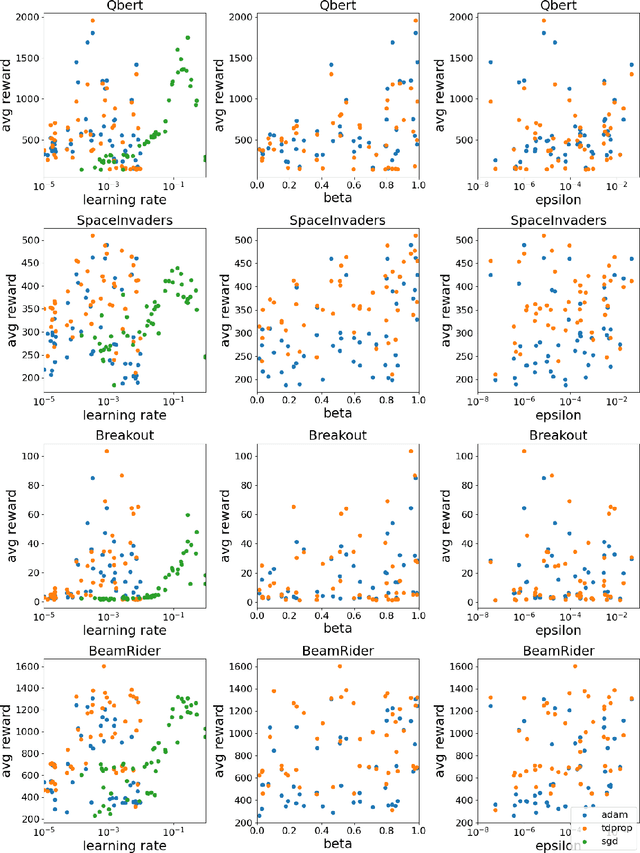
We investigate whether Jacobi preconditioning, accounting for the bootstrap term in temporal difference (TD) learning, can help boost performance of adaptive optimizers. Our method, TDprop, computes a per parameter learning rate based on the diagonal preconditioning of the TD update rule. We show how this can be used in both $n$-step returns and TD($\lambda$). Our theoretical findings demonstrate that including this additional preconditioning information is, surprisingly, comparable to normal semi-gradient TD if the optimal learning rate is found for both via a hyperparameter search. In Deep RL experiments using Expected SARSA, TDprop meets or exceeds the performance of Adam in all tested games under near-optimal learning rates, but a well-tuned SGD can yield similar improvements -- matching our theory. Our findings suggest that Jacobi preconditioning may improve upon typical adaptive optimization methods in Deep RL, but despite incorporating additional information from the TD bootstrap term, may not always be better than SGD.
Towards the Systematic Reporting of the Energy and Carbon Footprints of Machine Learning
Jan 31, 2020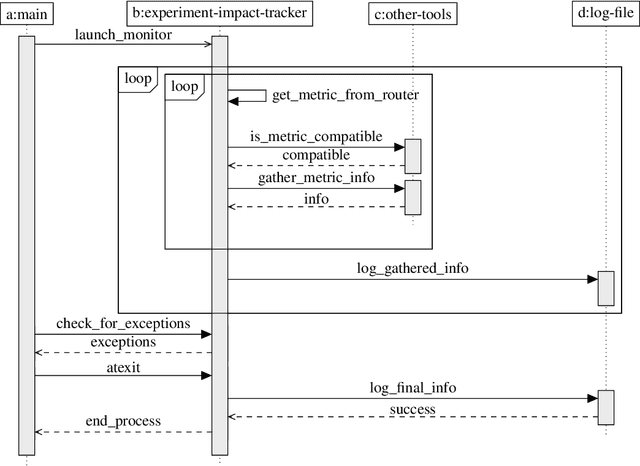
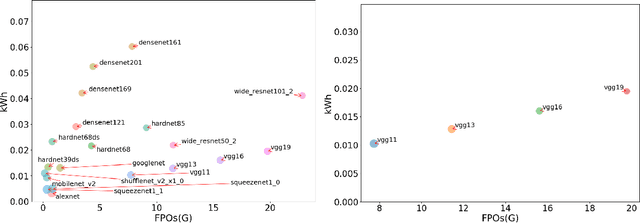
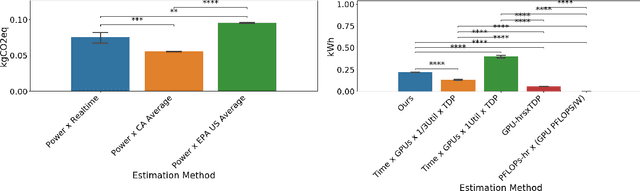
Accurate reporting of energy and carbon usage is essential for understanding the potential climate impacts of machine learning research. We introduce a framework that makes this easier by providing a simple interface for tracking realtime energy consumption and carbon emissions, as well as generating standardized online appendices. Utilizing this framework, we create a leaderboard for energy efficient reinforcement learning algorithms to incentivize responsible research in this area as an example for other areas of machine learning. Finally, based on case studies using our framework, we propose strategies for mitigation of carbon emissions and reduction of energy consumption. By making accounting easier, we hope to further the sustainable development of machine learning experiments and spur more research into energy efficient algorithms.
Gossip-based Actor-Learner Architectures for Deep Reinforcement Learning
Jun 09, 2019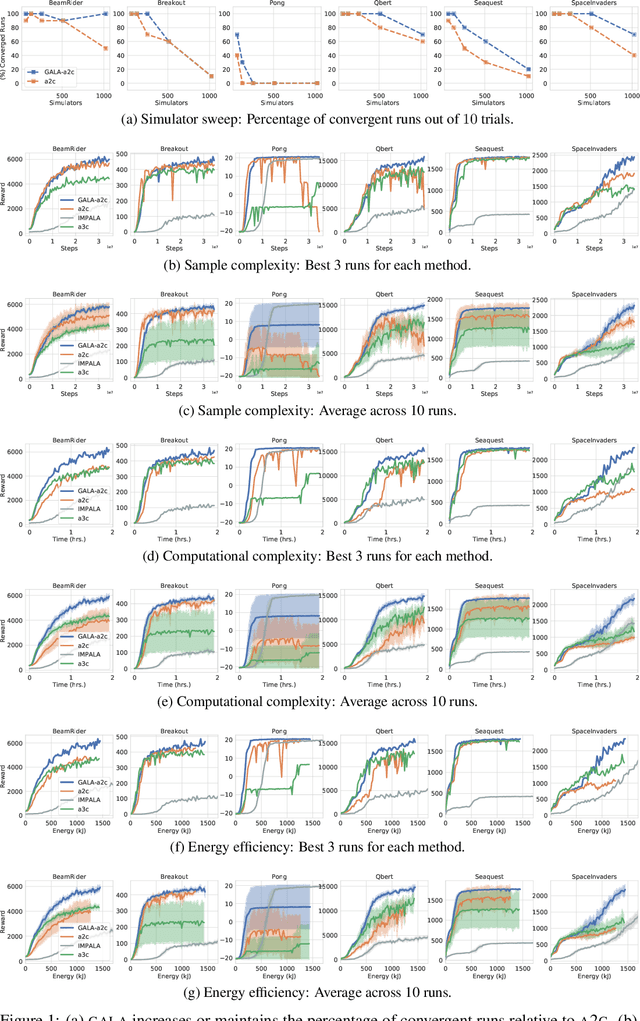
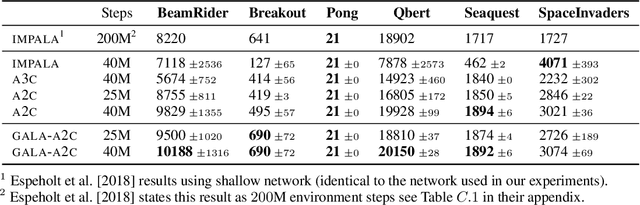
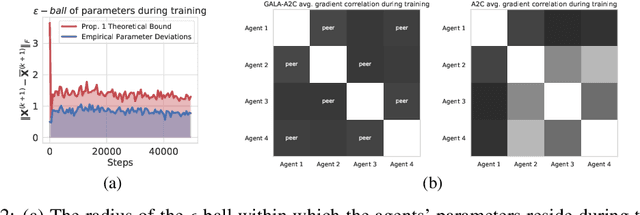
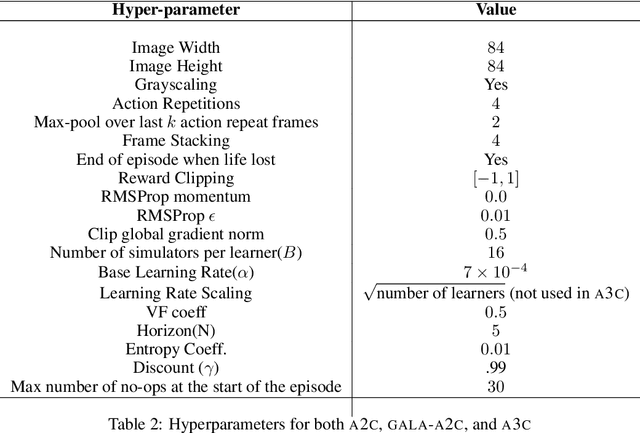
Multi-simulator training has contributed to the recent success of Deep Reinforcement Learning by stabilizing learning and allowing for higher training throughputs. We propose Gossip-based Actor-Learner Architectures (GALA) where several actor-learners (such as A2C agents) are organized in a peer-to-peer communication topology, and exchange information through asynchronous gossip in order to take advantage of a large number of distributed simulators. We prove that GALA agents remain within an epsilon-ball of one-another during training when using loosely coupled asynchronous communication. By reducing the amount of synchronization between agents, GALA is more computationally efficient and scalable compared to A2C, its fully-synchronous counterpart. GALA also outperforms A2C, being more robust and sample efficient. We show that we can run several loosely coupled GALA agents in parallel on a single GPU and achieve significantly higher hardware utilization and frame-rates than vanilla A2C at comparable power draws.
Separating value functions across time-scales
Feb 08, 2019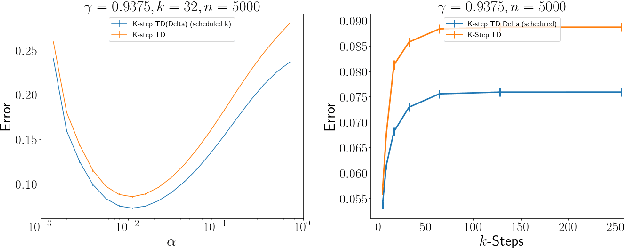

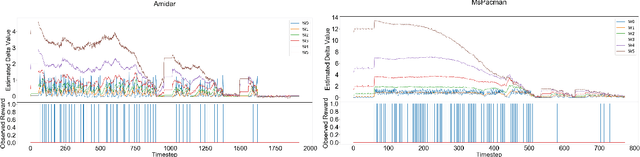
In many finite horizon episodic reinforcement learning (RL) settings, it is desirable to optimize for the undiscounted return - in settings like Atari, for instance, the goal is to collect the most points while staying alive in the long run. Yet, it may be difficult (or even intractable) mathematically to learn with this target. As such, temporal discounting is often applied to optimize over a shorter effective planning horizon. This comes at the cost of potentially biasing the optimization target away from the undiscounted goal. In settings where this bias is unacceptable - where the system must optimize for longer horizons at higher discounts - the target of the value function approximator may increase in variance leading to difficulties in learning. We present an extension of temporal difference (TD) learning, which we call TD($\Delta$), that breaks down a value function into a series of components based on the differences between value functions with smaller discount factors. The separation of a longer horizon value function into these components has useful properties in scalability and performance. We discuss these properties and show theoretic and empirical improvements over standard TD learning in certain settings.