 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient World Models with Context-Aware Tokenization
Jun 27, 2024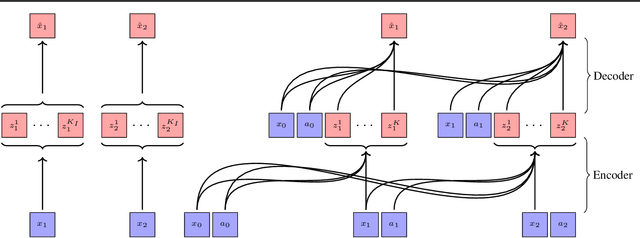
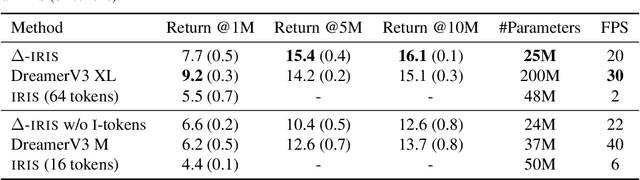
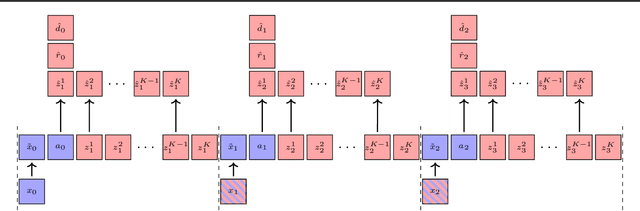

Scaling up deep Reinforcement Learning (RL) methods presents a significant challenge. Following developments in generative modelling, model-based RL positions itself as a strong contender. Recent advances in sequence modelling have led to effective transformer-based world models, albeit at the price of heavy computations due to the long sequences of tokens required to accurately simulate environments. In this work, we propose $\Delta$-IRIS, a new agent with a world model architecture composed of a discrete autoencoder that encodes stochastic deltas between time steps and an autoregressive transformer that predicts future deltas by summarizing the current state of the world with continuous tokens. In the Crafter benchmark, $\Delta$-IRIS sets a new state of the art at multiple frame budgets, while being an order of magnitude faster to train than previous attention-based approaches. We release our code and models at https://github.com/vmicheli/delta-iris.
Diffusion for World Modeling: Visual Details Matter in Atari
May 20, 2024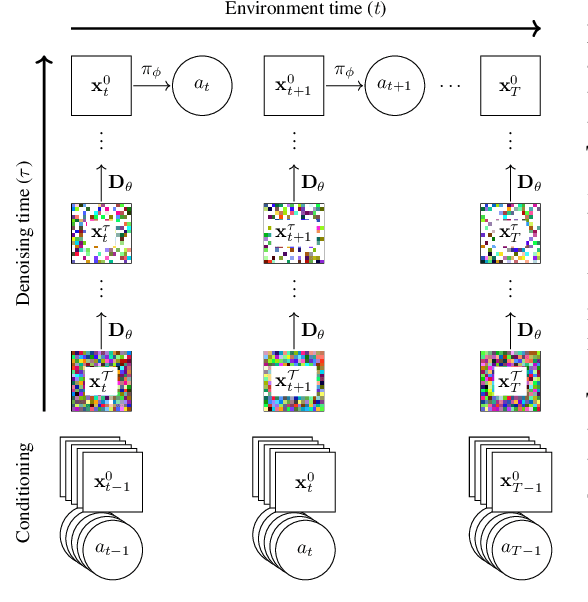
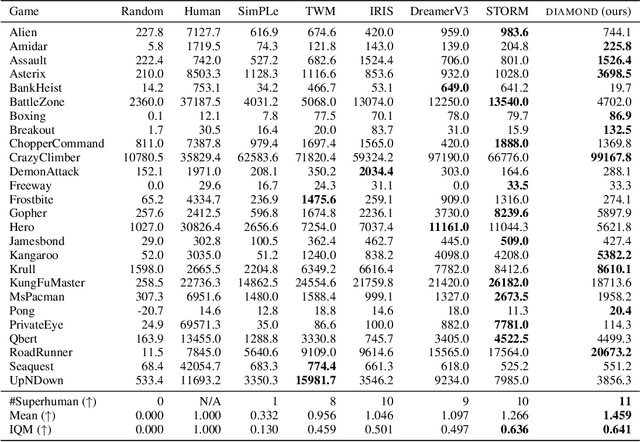
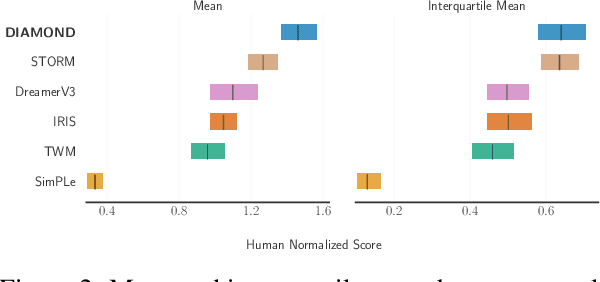
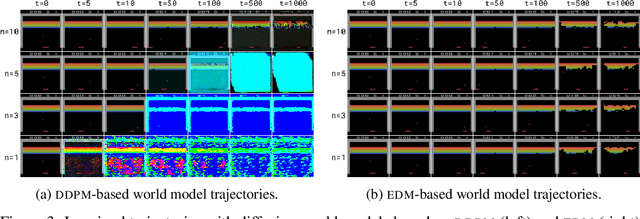
World models constitute a promising approach for training reinforcement learning agents in a safe and sample-efficient manner. Recent world models predominantly operate on sequences of discrete latent variables to model environment dynamics. However, this compression into a compact discrete representation may ignore visual details that are important for reinforcement learning. Concurrently, diffusion models have become a dominant approach for image generation, challenging well-established methods modeling discrete latents. Motivated by this paradigm shift, we introduce DIAMOND (DIffusion As a Model Of eNvironment Dreams), a reinforcement learning agent trained in a diffusion world model. We analyze the key design choices that are required to make diffusion suitable for world modeling, and demonstrate how improved visual details can lead to improved agent performance. DIAMOND achieves a mean human normalized score of 1.46 on the competitive Atari 100k benchmark; a new best for agents trained entirely within a world model. To foster future research on diffusion for world modeling, we release our code, agents and playable world models at https://github.com/eloialonso/diamond.
Transformers are Sample Efficient World Models
Sep 01, 2022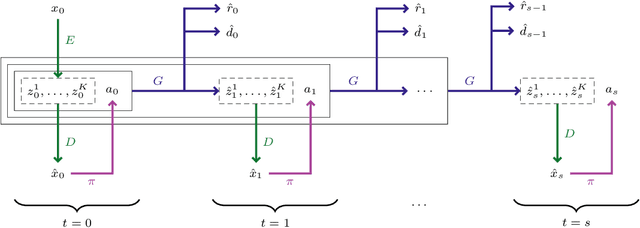
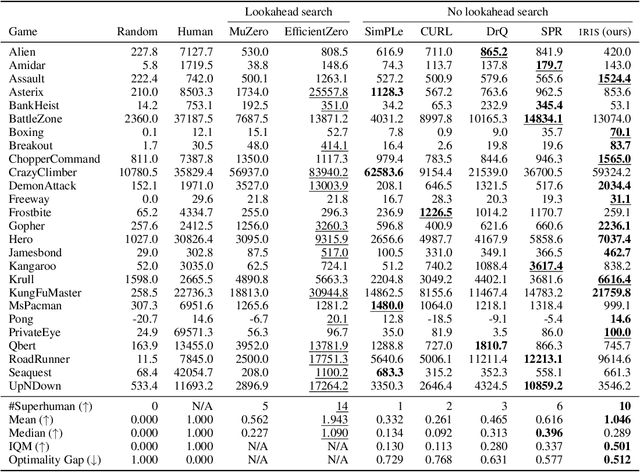


Deep reinforcement learning agents are notoriously sample inefficient, which considerably limits their application to real-world problems. Recently, many model-based methods have been designed to address this issue, with learning in the imagination of a world model being one of the most prominent approaches. However, while virtually unlimited interaction with a simulated environment sounds appealing, the world model has to be accurate over extended periods of time. Motivated by the success of Transformers in sequence modeling tasks, we introduce IRIS, a data-efficient agent that learns in a world model composed of a discrete autoencoder and an autoregressive Transformer. With the equivalent of only two hours of gameplay in the Atari 100k benchmark, IRIS achieves a mean human normalized score of 1.046, and outperforms humans on 10 out of 26 games. Our approach sets a new state of the art for methods without lookahead search, and even surpasses MuZero. To foster future research on Transformers and world models for sample-efficient reinforcement learning, we release our codebase at https://github.com/eloialonso/iris.
MineRL Diamond 2021 Competition: Overview, Results, and Lessons Learned
Feb 17, 2022
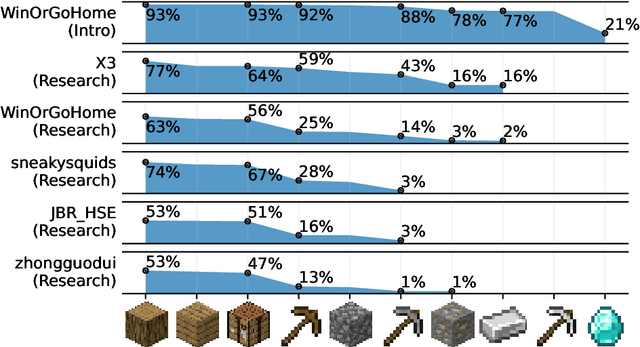
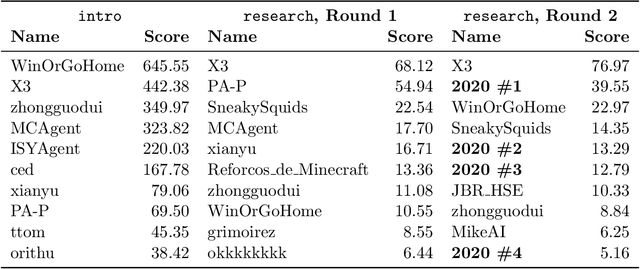
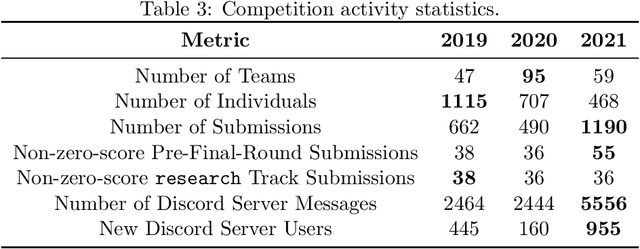
Reinforcement learning competitions advance the field by providing appropriate scope and support to develop solutions toward a specific problem. To promote the development of more broadly applicable methods, organizers need to enforce the use of general techniques, the use of sample-efficient methods, and the reproducibility of the results. While beneficial for the research community, these restrictions come at a cost -- increased difficulty. If the barrier for entry is too high, many potential participants are demoralized. With this in mind, we hosted the third edition of the MineRL ObtainDiamond competition, MineRL Diamond 2021, with a separate track in which we permitted any solution to promote the participation of newcomers. With this track and more extensive tutorials and support, we saw an increased number of submissions. The participants of this easier track were able to obtain a diamond, and the participants of the harder track progressed the generalizable solutions in the same task.
Reinforcement Learning Agents for Ubisoft's Roller Champions
Dec 10, 2020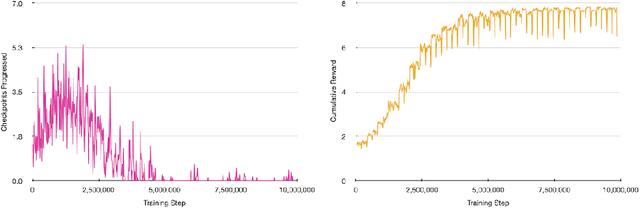
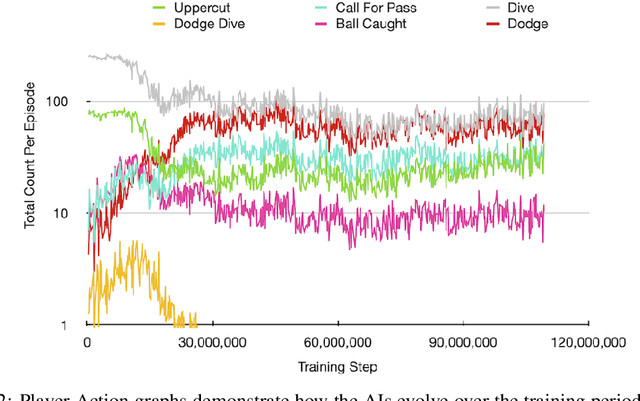
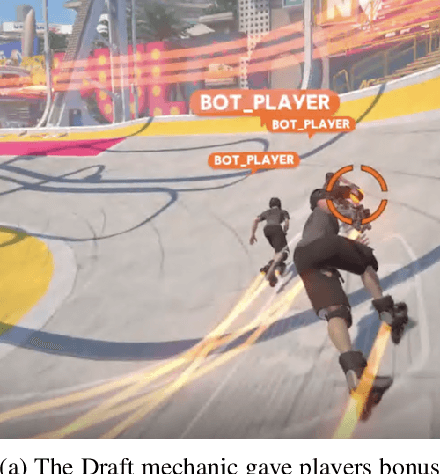
In recent years, Reinforcement Learning (RL) has seen increasing popularity in research and popular culture. However, skepticism still surrounds the practicality of RL in modern video game development. In this paper, we demonstrate by example that RL can be a great tool for Artificial Intelligence (AI) design in modern, non-trivial video games. We present our RL system for Ubisoft's Roller Champions, a 3v3 Competitive Multiplayer Sports Game played on an oval-shaped skating arena. Our system is designed to keep up with agile, fast-paced development, taking 1--4 days to train a new model following gameplay changes. The AIs are adapted for various game modes, including a 2v2 mode, a Training with Bots mode, in addition to the Classic game mode where they replace players who have disconnected. We observe that the AIs develop sophisticated co-ordinated strategies, and can aid in balancing the game as an added bonus. Please see the accompanying video at https://vimeo.com/466780171 (password: rollerRWRL2020) for examples.
Deep Reinforcement Learning for Navigation in AAA Video Games
Nov 09, 2020
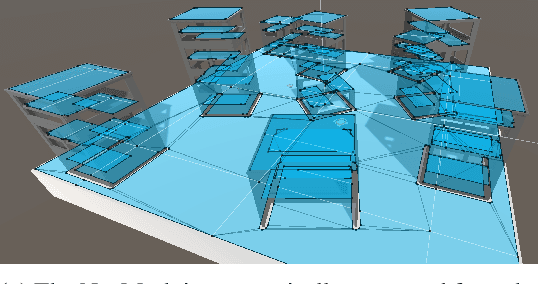
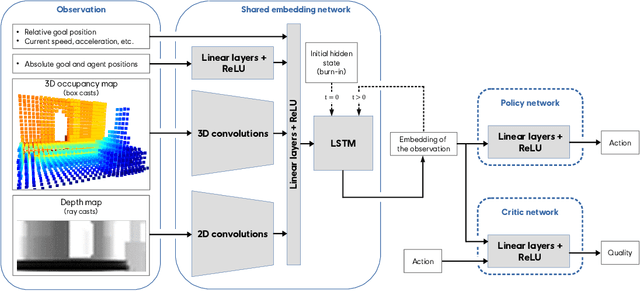
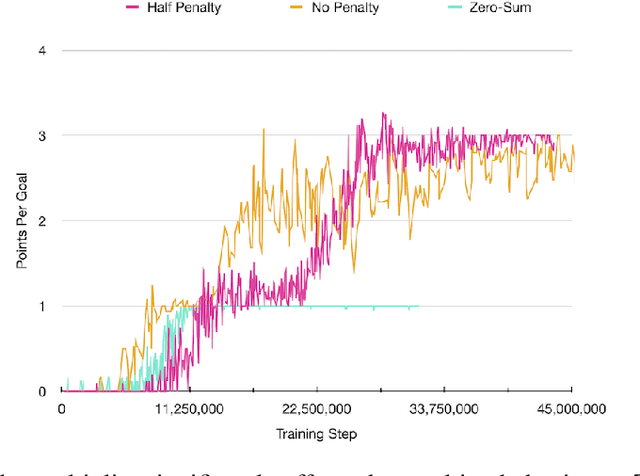
In video games, non-player characters (NPCs) are used to enhance the players' experience in a variety of ways, e.g., as enemies, allies, or innocent bystanders. A crucial component of NPCs is navigation, which allows them to move from one point to another on the map. The most popular approach for NPC navigation in the video game industry is to use a navigation mesh (NavMesh), which is a graph representation of the map, with nodes and edges indicating traversable areas. Unfortunately, complex navigation abilities that extend the character's capacity for movement, e.g., grappling hooks, jetpacks, teleportation, or double-jumps, increases the complexity of the NavMesh, making it intractable in many practical scenarios. Game designers are thus constrained to only add abilities that can be handled by a NavMesh if they want to have NPC navigation. As an alternative, we propose to use Deep Reinforcement Learning (Deep RL) to learn how to navigate 3D maps using any navigation ability. We test our approach on complex 3D environments in the Unity game engine that are notably an order of magnitude larger than maps typically used in the Deep RL literature. One of these maps is directly modeled after a Ubisoft AAA game. We find that our approach performs surprisingly well, achieving at least $90\%$ success rate on all tested scenarios. A video of our results is available at https://youtu.be/WFIf9Wwlq8M.
Discrete and Continuous Action Representation for Practical RL in Video Games
Dec 23, 2019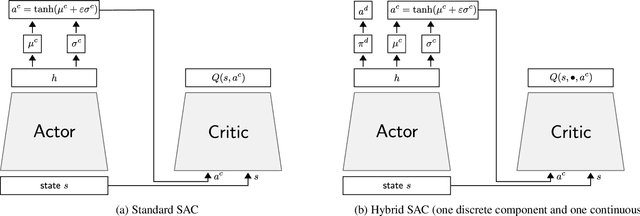
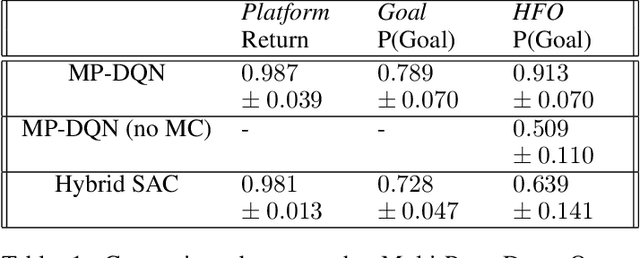
While most current research in Reinforcement Learning (RL) focuses on improving the performance of the algorithms in controlled environments, the use of RL under constraints like those met in the video game industry is rarely studied. Operating under such constraints, we propose Hybrid SAC, an extension of the Soft Actor-Critic algorithm able to handle discrete, continuous and parameterized actions in a principled way. We show that Hybrid SAC can successfully solve a highspeed driving task in one of our games, and is competitive with the state-of-the-art on parameterized actions benchmark tasks. We also explore the impact of using normalizing flows to enrich the expressiveness of the policy at minimal computational cost, and identify a potential undesired effect of SAC when used with normalizing flows, that may be addressed by optimizing a different objective.
Adversarial Generation of Handwritten Text Images Conditioned on Sequences
Mar 01, 2019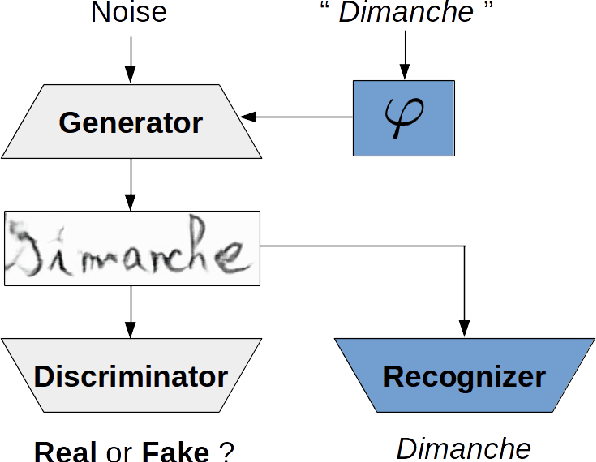
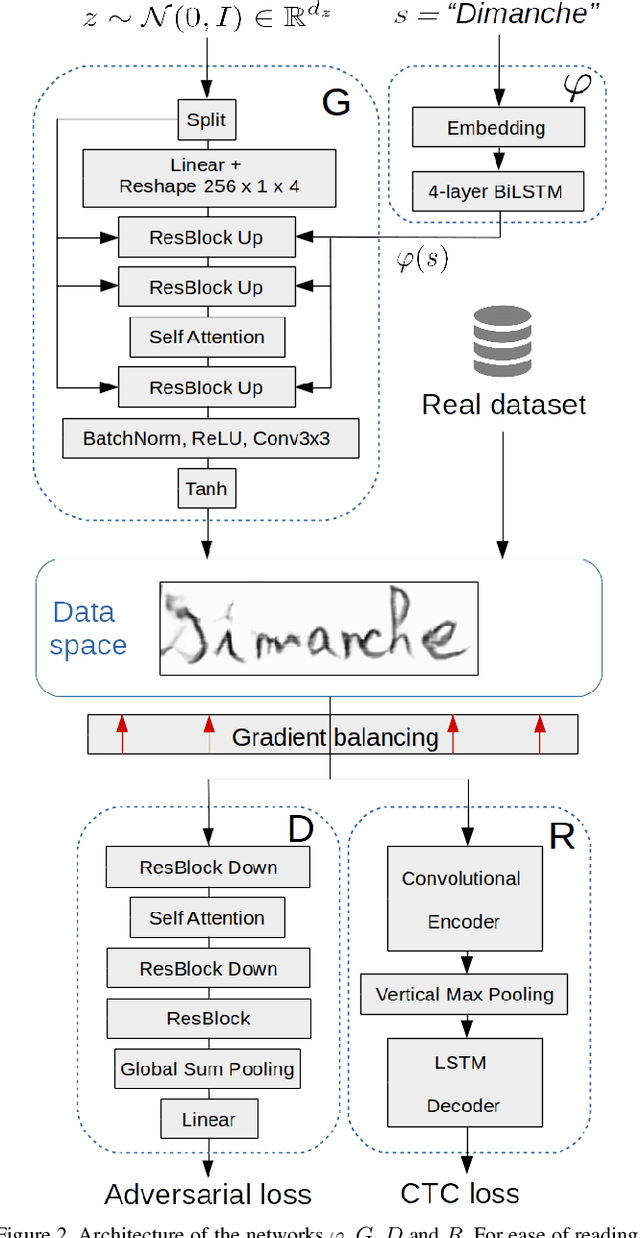
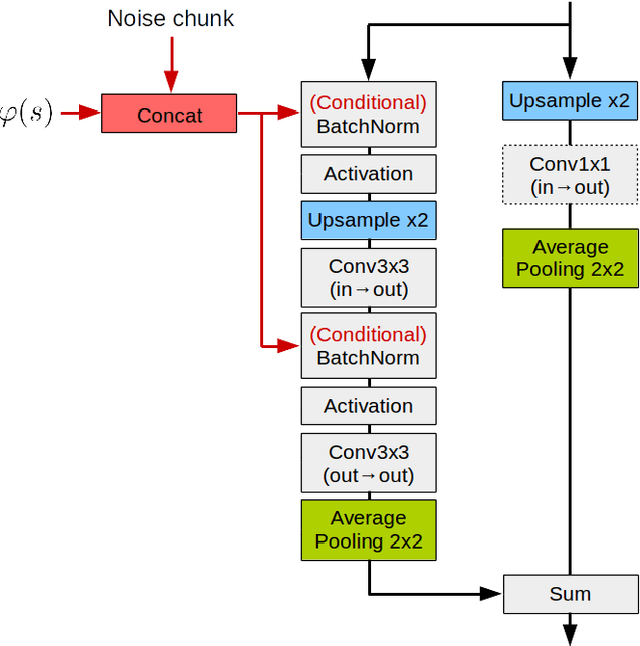
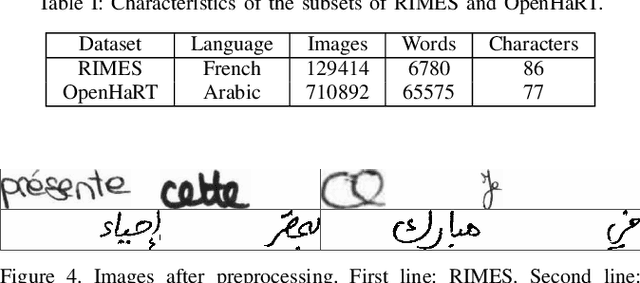
State-of-the-art offline handwriting text recognition systems tend to use neural networks and therefore require a large amount of annotated data to be trained. In order to partially satisfy this requirement, we propose a system based on Generative Adversarial Networks (GAN) to produce synthetic images of handwritten words. We use bidirectional LSTM recurrent layers to get an embedding of the word to be rendered, and we feed it to the generator network. We also modify the standard GAN by adding an auxiliary network for text recognition. The system is then trained with a balanced combination of an adversarial loss and a CTC loss. Together, these extensions to GAN enable to control the textual content of the generated word images. We obtain realistic images on both French and Arabic datasets, and we show that integrating these synthetic images into the existing training data of a text recognition system can slightly enhance its performance.