 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient World Models with Context-Aware Tokenization
Jun 27, 2024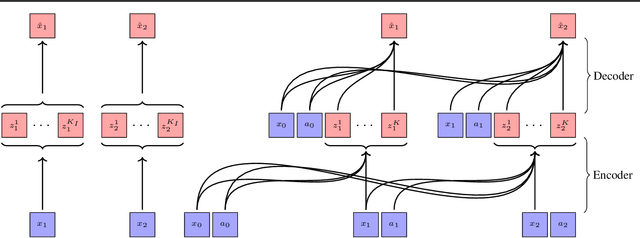
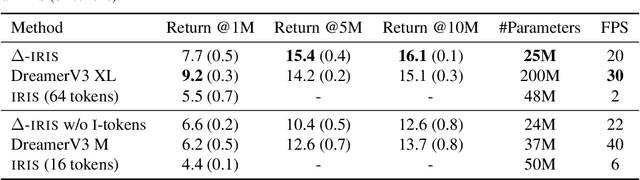
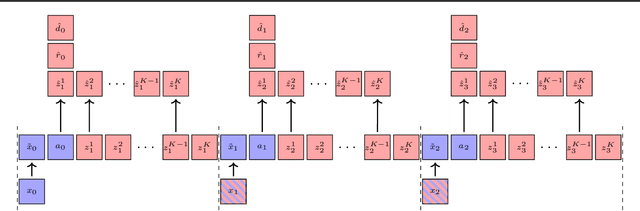

Scaling up deep Reinforcement Learning (RL) methods presents a significant challenge. Following developments in generative modelling, model-based RL positions itself as a strong contender. Recent advances in sequence modelling have led to effective transformer-based world models, albeit at the price of heavy computations due to the long sequences of tokens required to accurately simulate environments. In this work, we propose $\Delta$-IRIS, a new agent with a world model architecture composed of a discrete autoencoder that encodes stochastic deltas between time steps and an autoregressive transformer that predicts future deltas by summarizing the current state of the world with continuous tokens. In the Crafter benchmark, $\Delta$-IRIS sets a new state of the art at multiple frame budgets, while being an order of magnitude faster to train than previous attention-based approaches. We release our code and models at https://github.com/vmicheli/delta-iris.
Diffusion for World Modeling: Visual Details Matter in Atari
May 20, 2024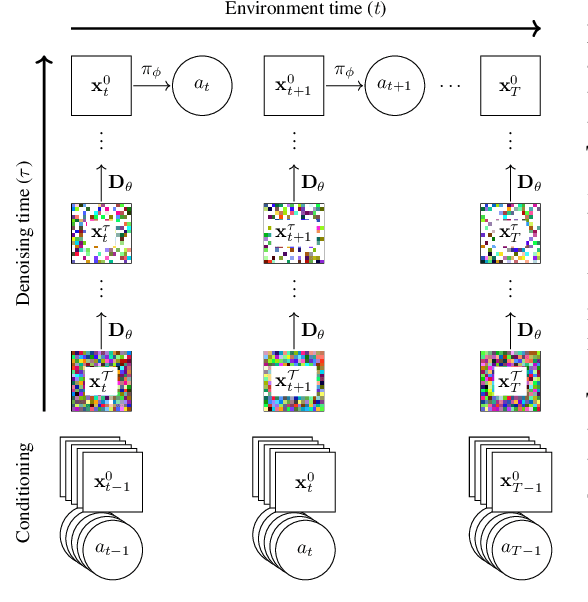
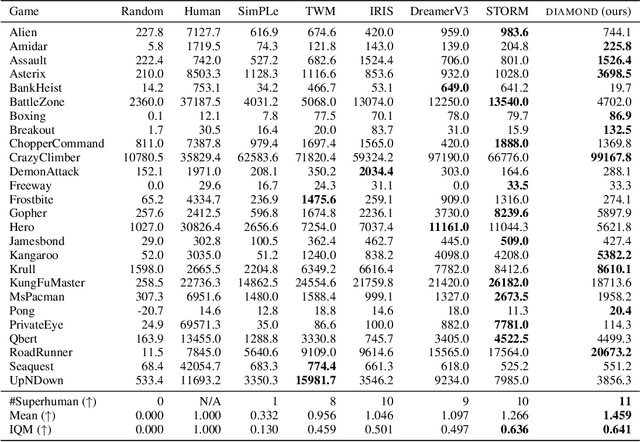
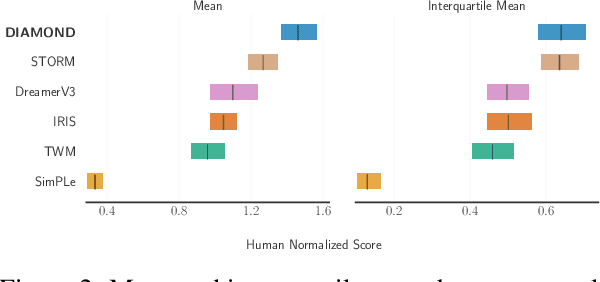
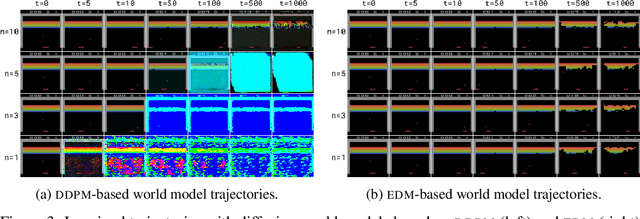
World models constitute a promising approach for training reinforcement learning agents in a safe and sample-efficient manner. Recent world models predominantly operate on sequences of discrete latent variables to model environment dynamics. However, this compression into a compact discrete representation may ignore visual details that are important for reinforcement learning. Concurrently, diffusion models have become a dominant approach for image generation, challenging well-established methods modeling discrete latents. Motivated by this paradigm shift, we introduce DIAMOND (DIffusion As a Model Of eNvironment Dreams), a reinforcement learning agent trained in a diffusion world model. We analyze the key design choices that are required to make diffusion suitable for world modeling, and demonstrate how improved visual details can lead to improved agent performance. DIAMOND achieves a mean human normalized score of 1.46 on the competitive Atari 100k benchmark; a new best for agents trained entirely within a world model. To foster future research on diffusion for world modeling, we release our code, agents and playable world models at https://github.com/eloialonso/diamond.
Transformers are Sample Efficient World Models
Sep 01, 2022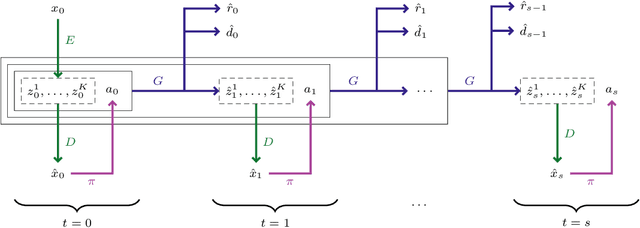
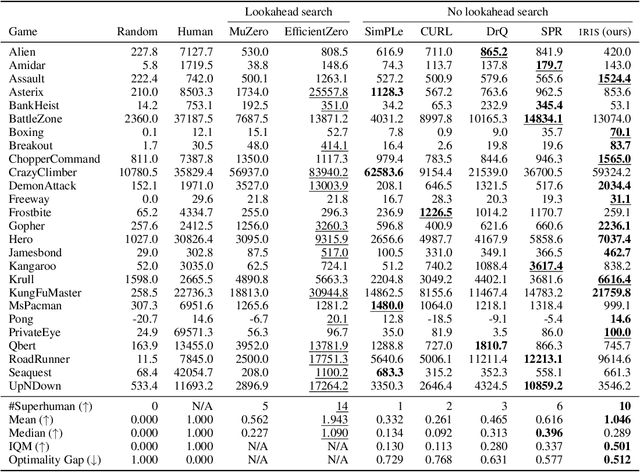


Deep reinforcement learning agents are notoriously sample inefficient, which considerably limits their application to real-world problems. Recently, many model-based methods have been designed to address this issue, with learning in the imagination of a world model being one of the most prominent approaches. However, while virtually unlimited interaction with a simulated environment sounds appealing, the world model has to be accurate over extended periods of time. Motivated by the success of Transformers in sequence modeling tasks, we introduce IRIS, a data-efficient agent that learns in a world model composed of a discrete autoencoder and an autoregressive Transformer. With the equivalent of only two hours of gameplay in the Atari 100k benchmark, IRIS achieves a mean human normalized score of 1.046, and outperforms humans on 10 out of 26 games. Our approach sets a new state of the art for methods without lookahead search, and even surpasses MuZero. To foster future research on Transformers and world models for sample-efficient reinforcement learning, we release our codebase at https://github.com/eloialonso/iris.
MineRL Diamond 2021 Competition: Overview, Results, and Lessons Learned
Feb 17, 2022
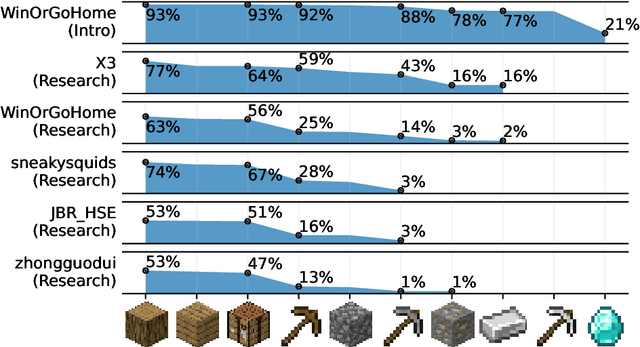
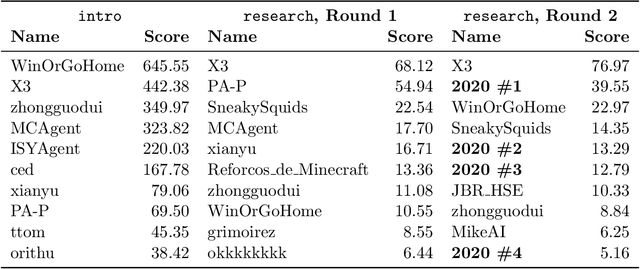
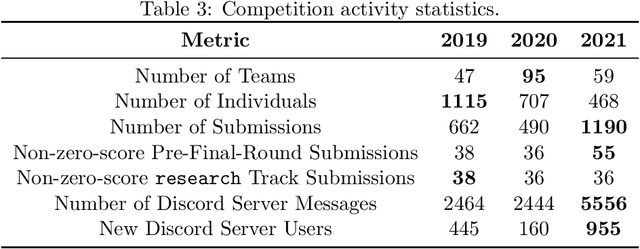
Reinforcement learning competitions advance the field by providing appropriate scope and support to develop solutions toward a specific problem. To promote the development of more broadly applicable methods, organizers need to enforce the use of general techniques, the use of sample-efficient methods, and the reproducibility of the results. While beneficial for the research community, these restrictions come at a cost -- increased difficulty. If the barrier for entry is too high, many potential participants are demoralized. With this in mind, we hosted the third edition of the MineRL ObtainDiamond competition, MineRL Diamond 2021, with a separate track in which we permitted any solution to promote the participation of newcomers. With this track and more extensive tutorials and support, we saw an increased number of submissions. The participants of this easier track were able to obtain a diamond, and the participants of the harder track progressed the generalizable solutions in the same task.
Language Models are Few-Shot Butlers
Apr 16, 2021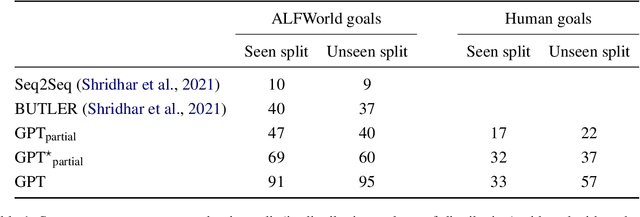
Pretrained language models demonstrate strong performance in most NLP tasks when fine-tuned on small task-specific datasets. Hence, these autoregressive models constitute ideal agents to operate in text-based environments where language understanding and generative capabilities are essential. Nonetheless, collecting expert demonstrations in such environments is a time-consuming endeavour. We introduce a two-stage procedure to learn from a small set of demonstrations and further improve by interacting with an environment. We show that language models fine-tuned with only 1.2% of the expert demonstrations and a simple reinforcement learning algorithm achieve a 51% absolute improvement in success rate over existing methods in the ALFWorld environment.
Structural analysis of an all-purpose question answering model
Apr 13, 2021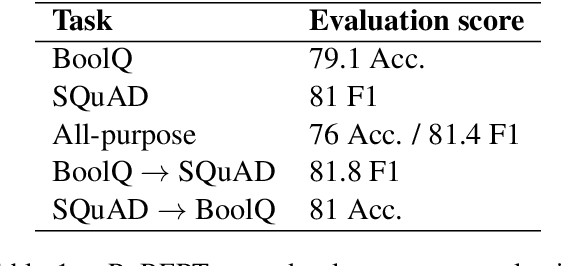
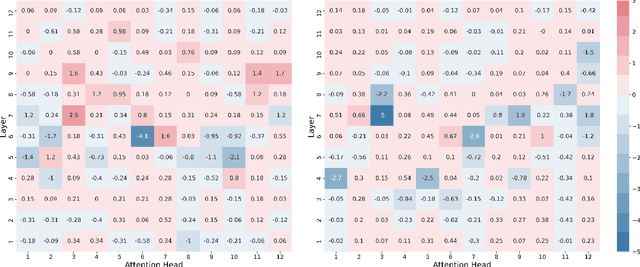
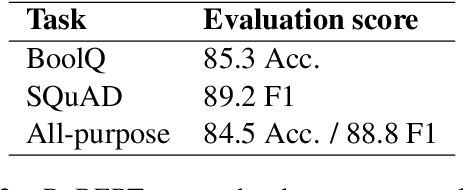
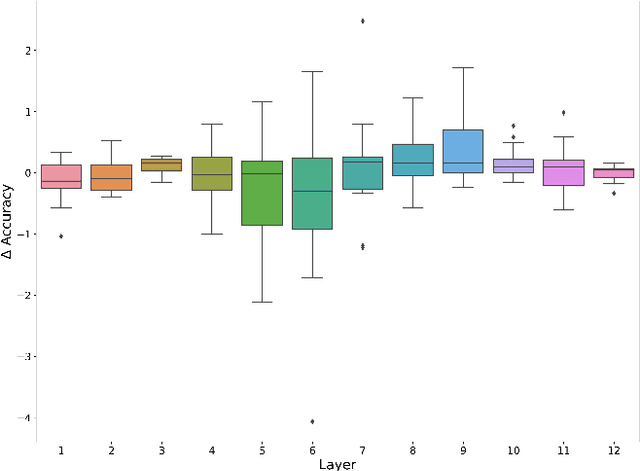
Attention is a key component of the now ubiquitous pre-trained language models. By learning to focus on relevant pieces of information, these Transformer-based architectures have proven capable of tackling several tasks at once and sometimes even surpass their single-task counterparts. To better understand this phenomenon, we conduct a structural analysis of a new all-purpose question answering model that we introduce. Surprisingly, this model retains single-task performance even in the absence of a strong transfer effect between tasks. Through attention head importance scoring, we observe that attention heads specialize in a particular task and that some heads are more conducive to learning than others in both the multi-task and single-task settings.
On the importance of pre-training data volume for compact language models
Oct 09, 2020

Recent advances in language modeling have led to computationally intensive and resource-demanding state-of-the-art models. In an effort towards sustainable practices, we study the impact of pre-training data volume on compact language models. Multiple BERT-based models are trained on gradually increasing amounts of French text. Through fine-tuning on the French Question Answering Dataset (FQuAD), we observe that well-performing models are obtained with as little as 100 MB of text. In addition, we show that past critically low amounts of pre-training data, an intermediate pre-training step on the task-specific corpus does not yield substantial improvements.
Multi-task Reinforcement Learning with a Planning Quasi-Metric
Feb 08, 2020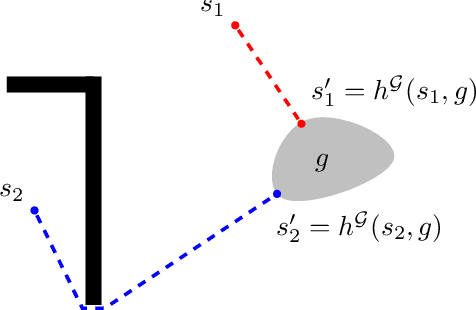
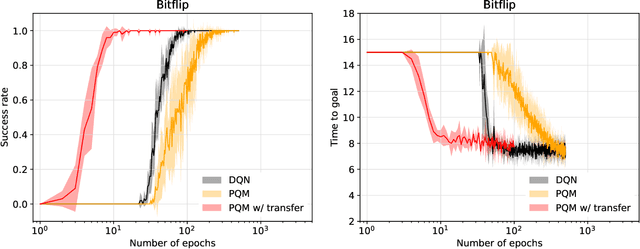
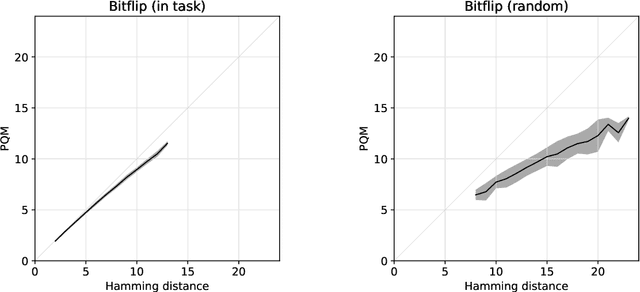

We introduce a new reinforcement learning approach combining a planning quasi-metric (PQM) that estimates the number of actions required to go from a state to another, with task-specific planners that compute a target state to reach a given goal. The main advantage of this decomposition is to allow the sharing across tasks of a task-agnostic model of the quasi-metric that captures the environment's dynamics and can be learned in a dense and unsupervised manner. We demonstrate the usefulness of this approach on the standard bit-flip problem and in the MuJoCo robotic arm simulator.