 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenSqueeze: Performance-Preserving Compression for Reasoning LLMs
Nov 17, 2025Emerging reasoning LLMs such as OpenAI-o1 and DeepSeek-R1 have achieved strong performance on complex reasoning tasks by generating long chain-of-thought (CoT) traces. However, these long CoTs result in increased token usage, leading to higher inference latency and memory consumption. As a result, balancing accuracy and reasoning efficiency has become essential for deploying reasoning LLMs in practical applications. Existing long-to-short (Long2Short) methods aim to reduce inference length but often sacrifice accuracy, revealing a need for an approach that maintains performance while lowering token costs. To address this efficiency-accuracy tradeoff, we propose TokenSqueeze, a novel Long2Short method that condenses reasoning paths while preserving performance and relying exclusively on self-generated data. First, to prevent performance degradation caused by excessive compression of reasoning depth, we propose to select self-generated samples whose reasoning depth is adaptively matched to the complexity of the problem. To further optimize the linguistic expression without altering the underlying reasoning paths, we introduce a distribution-aligned linguistic refinement method that enhances the clarity and conciseness of the reasoning path while preserving its logical integrity. Comprehensive experimental results demonstrate the effectiveness of TokenSqueeze in reducing token usage while maintaining accuracy. Notably, DeepSeek-R1-Distill-Qwen-7B fine-tuned using our proposed method achieved a 50\% average token reduction while preserving accuracy on the MATH500 benchmark. TokenSqueeze exclusively utilizes the model's self-generated data, enabling efficient and high-fidelity reasoning without relying on manually curated short-answer datasets across diverse applications. Our code is available at https://github.com/zhangyx1122/TokenSqueeze.
Deep (Predictive) Discounted Counterfactual Regret Minimization
Nov 11, 2025Counterfactual regret minimization (CFR) is a family of algorithms for effectively solving imperfect-information games. To enhance CFR's applicability in large games, researchers use neural networks to approximate its behavior. However, existing methods are mainly based on vanilla CFR and struggle to effectively integrate more advanced CFR variants. In this work, we propose an efficient model-free neural CFR algorithm, overcoming the limitations of existing methods in approximating advanced CFR variants. At each iteration, it collects variance-reduced sampled advantages based on a value network, fits cumulative advantages by bootstrapping, and applies discounting and clipping operations to simulate the update mechanisms of advanced CFR variants. Experimental results show that, compared with model-free neural algorithms, it exhibits faster convergence in typical imperfect-information games and demonstrates stronger adversarial performance in a large poker game.
Yan: Foundational Interactive Video Generation
Aug 13, 2025We present Yan, a foundational framework for interactive video generation, covering the entire pipeline from simulation and generation to editing. Specifically, Yan comprises three core modules. AAA-level Simulation: We design a highly-compressed, low-latency 3D-VAE coupled with a KV-cache-based shift-window denoising inference process, achieving real-time 1080P/60FPS interactive simulation. Multi-Modal Generation: We introduce a hierarchical autoregressive caption method that injects game-specific knowledge into open-domain multi-modal video diffusion models (VDMs), then transforming the VDM into a frame-wise, action-controllable, real-time infinite interactive video generator. Notably, when the textual and visual prompts are sourced from different domains, the model demonstrates strong generalization, allowing it to blend and compose the style and mechanics across domains flexibly according to user prompts. Multi-Granularity Editing: We propose a hybrid model that explicitly disentangles interactive mechanics simulation from visual rendering, enabling multi-granularity video content editing during interaction through text. Collectively, Yan offers an integration of these modules, pushing interactive video generation beyond isolated capabilities toward a comprehensive AI-driven interactive creation paradigm, paving the way for the next generation of creative tools, media, and entertainment. The project page is: https://greatx3.github.io/Yan/.
Learned Off-aperture Encoding for Wide Field-of-view RGBD Imaging
Jul 30, 2025End-to-end (E2E) designed imaging systems integrate coded optical designs with decoding algorithms to enhance imaging fidelity for diverse visual tasks. However, existing E2E designs encounter significant challenges in maintaining high image fidelity at wide fields of view, due to high computational complexity, as well as difficulties in modeling off-axis wave propagation while accounting for off-axis aberrations. In particular, the common approach of placing the encoding element into the aperture or pupil plane results in only a global control of the wavefront. To overcome these limitations, this work explores an additional design choice by positioning a DOE off-aperture, enabling a spatial unmixing of the degrees of freedom and providing local control over the wavefront over the image plane. Our approach further leverages hybrid refractive-diffractive optical systems by linking differentiable ray and wave optics modeling, thereby optimizing depth imaging quality and demonstrating system versatility. Experimental results reveal that the off-aperture DOE enhances the imaging quality by over 5 dB in PSNR at a FoV of approximately $45^\circ$ when paired with a simple thin lens, outperforming traditional on-aperture systems. Furthermore, we successfully recover color and depth information at nearly $28^\circ$ FoV using off-aperture DOE configurations with compound optics. Physical prototypes for both applications validate the effectiveness and versatility of the proposed method.
Goal-Oriented Skill Abstraction for Offline Multi-Task Reinforcement Learning
Jul 09, 2025Offline multi-task reinforcement learning aims to learn a unified policy capable of solving multiple tasks using only pre-collected task-mixed datasets, without requiring any online interaction with the environment. However, it faces significant challenges in effectively sharing knowledge across tasks. Inspired by the efficient knowledge abstraction observed in human learning, we propose Goal-Oriented Skill Abstraction (GO-Skill), a novel approach designed to extract and utilize reusable skills to enhance knowledge transfer and task performance. Our approach uncovers reusable skills through a goal-oriented skill extraction process and leverages vector quantization to construct a discrete skill library. To mitigate class imbalances between broadly applicable and task-specific skills, we introduce a skill enhancement phase to refine the extracted skills. Furthermore, we integrate these skills using hierarchical policy learning, enabling the construction of a high-level policy that dynamically orchestrates discrete skills to accomplish specific tasks. Extensive experiments on diverse robotic manipulation tasks within the MetaWorld benchmark demonstrate the effectiveness and versatility of GO-Skill.
* ICML2025
Large-Area Fabrication-aware Computational Diffractive Optics
May 28, 2025Differentiable optics, as an emerging paradigm that jointly optimizes optics and (optional) image processing algorithms, has made innovative optical designs possible across a broad range of applications. Many of these systems utilize diffractive optical components (DOEs) for holography, PSF engineering, or wavefront shaping. Existing approaches have, however, mostly remained limited to laboratory prototypes, owing to a large quality gap between simulation and manufactured devices. We aim at lifting the fundamental technical barriers to the practical use of learned diffractive optical systems. To this end, we propose a fabrication-aware design pipeline for diffractive optics fabricated by direct-write grayscale lithography followed by nano-imprinting replication, which is directly suited for inexpensive mass production of large area designs. We propose a super-resolved neural lithography model that can accurately predict the 3D geometry generated by the fabrication process. This model can be seamlessly integrated into existing differentiable optics frameworks, enabling fabrication-aware, end-to-end optimization of computational optical systems. To tackle the computational challenges, we also devise tensor-parallel compute framework centered on distributing large-scale FFT computation across many GPUs. As such, we demonstrate large scale diffractive optics designs up to 32.16 mm $\times$ 21.44 mm, simulated on grids of up to 128,640 by 85,760 feature points. We find adequate agreement between simulation and fabricated prototypes for applications such as holography and PSF engineering. We also achieve high image quality from an imaging system comprised only of a single DOE, with images processed only by a Wiener filter utilizing the simulation PSF. We believe our findings lift the fabrication limitations for real-world applications of diffractive optics and differentiable optical design.
Hamiltonian Descent Algorithms for Optimization: Accelerated Rates via Randomized Integration Time
May 18, 2025We study the Hamiltonian flow for optimization (HF-opt), which simulates the Hamiltonian dynamics for some integration time and resets the velocity to $0$ to decrease the objective function; this is the optimization analogue of the Hamiltonian Monte Carlo algorithm for sampling. For short integration time, HF-opt has the same convergence rates as gradient descent for minimizing strongly and weakly convex functions. We show that by randomizing the integration time in HF-opt, the resulting randomized Hamiltonian flow (RHF) achieves accelerated convergence rates in continuous time, similar to the rates for the accelerated gradient flow. We study a discrete-time implementation of RHF as the randomized Hamiltonian gradient descent (RHGD) algorithm. We prove that RHGD achieves the same accelerated convergence rates as Nesterov's accelerated gradient descent (AGD) for minimizing smooth strongly and weakly convex functions. We provide numerical experiments to demonstrate that RHGD is competitive with classical accelerated methods such as AGD across all settings and outperforms them in certain regimes.
Transforming Future Data Center Operations and Management via Physical AI
Apr 07, 2025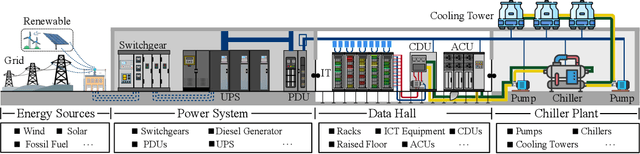
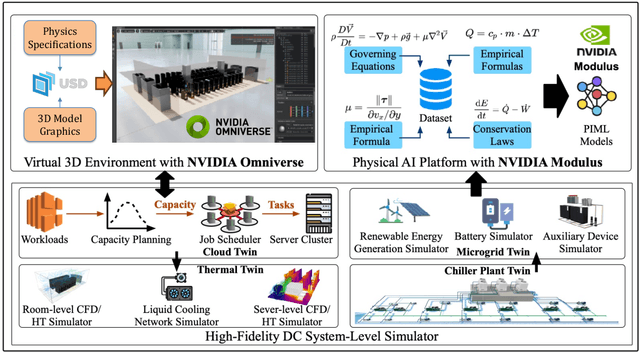
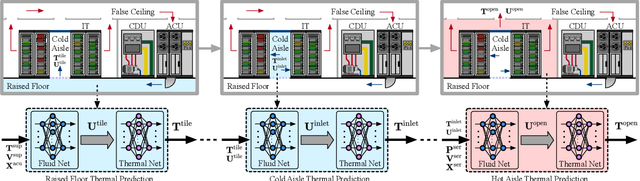
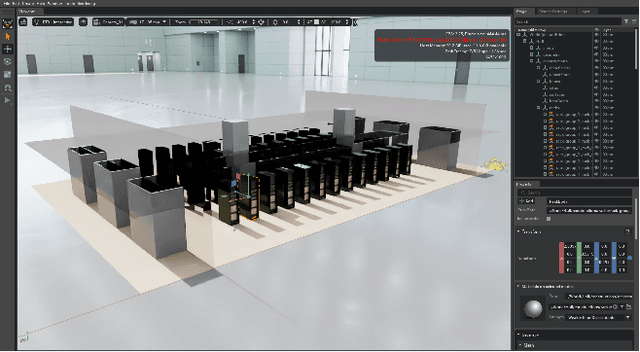
Data centers (DCs) as mission-critical infrastructures are pivotal in powering the growth of artificial intelligence (AI) and the digital economy. The evolution from Internet DC to AI DC has introduced new challenges in operating and managing data centers for improved business resilience and reduced total cost of ownership. As a result, new paradigms, beyond the traditional approaches based on best practices, must be in order for future data centers. In this research, we propose and develop a novel Physical AI (PhyAI) framework for advancing DC operations and management. Our system leverages the emerging capabilities of state-of-the-art industrial products and our in-house research and development. Specifically, it presents three core modules, namely: 1) an industry-grade in-house simulation engine to simulate DC operations in a highly accurate manner, 2) an AI engine built upon NVIDIA PhysicsNemo for the training and evaluation of physics-informed machine learning (PIML) models, and 3) a digital twin platform built upon NVIDIA Omniverse for our proposed 5-tier digital twin framework. This system presents a scalable and adaptable solution to digitalize, optimize, and automate future data center operations and management, by enabling real-time digital twins for future data centers. To illustrate its effectiveness, we present a compelling case study on building a surrogate model for predicting the thermal and airflow profiles of a large-scale DC in a real-time manner. Our results demonstrate its superior performance over traditional time-consuming Computational Fluid Dynamics/Heat Transfer (CFD/HT) simulation, with a median absolute temperature prediction error of 0.18 {\deg}C. This emerging approach would open doors to several potential research directions for advancing Physical AI in future DC operations.
Agents Play Thousands of 3D Video Games
Mar 17, 2025We present PORTAL, a novel framework for developing artificial intelligence agents capable of playing thousands of 3D video games through language-guided policy generation. By transforming decision-making problems into language modeling tasks, our approach leverages large language models (LLMs) to generate behavior trees represented in domain-specific language (DSL). This method eliminates the computational burden associated with traditional reinforcement learning approaches while preserving strategic depth and rapid adaptability. Our framework introduces a hybrid policy structure that combines rule-based nodes with neural network components, enabling both high-level strategic reasoning and precise low-level control. A dual-feedback mechanism incorporating quantitative game metrics and vision-language model analysis facilitates iterative policy improvement at both tactical and strategic levels. The resulting policies are instantaneously deployable, human-interpretable, and capable of generalizing across diverse gaming environments. Experimental results demonstrate PORTAL's effectiveness across thousands of first-person shooter (FPS) games, showcasing significant improvements in development efficiency, policy generalization, and behavior diversity compared to traditional approaches. PORTAL represents a significant advancement in game AI development, offering a practical solution for creating sophisticated agents that can operate across thousands of commercial video games with minimal development overhead. Experiment results on the 3D video games are best viewed on https://zhongwen.one/projects/portal .
Optimizing Latent Goal by Learning from Trajectory Preference
Dec 03, 2024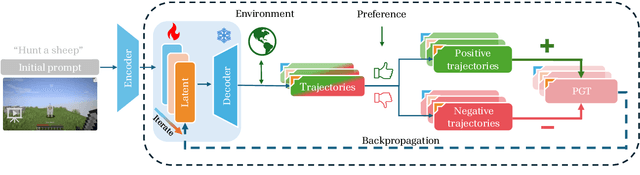
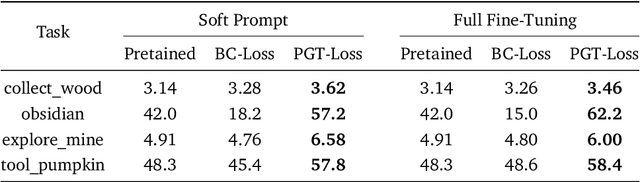
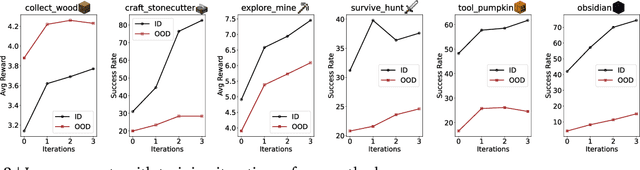
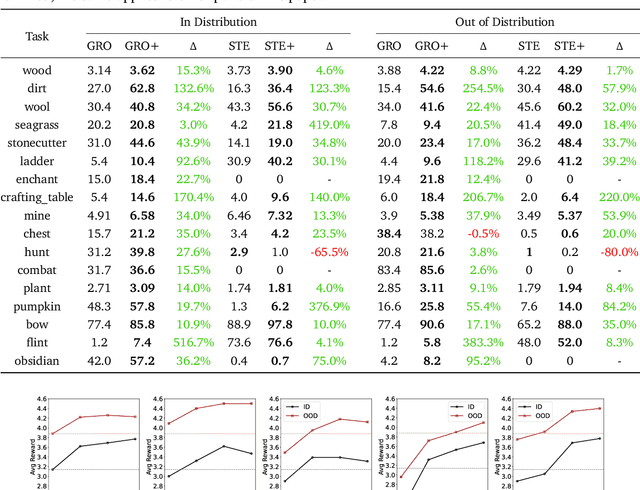
A glowing body of work has emerged focusing on instruction-following policies for open-world agents, aiming to better align the agent's behavior with human intentions. However, the performance of these policies is highly susceptible to the initial prompt, which leads to extra efforts in selecting the best instructions. We propose a framework named Preference Goal Tuning (PGT). PGT allows an instruction following policy to interact with the environment to collect several trajectories, which will be categorized into positive and negative samples based on preference. Then we use preference learning to fine-tune the initial goal latent representation with the categorized trajectories while keeping the policy backbone frozen. The experiment result shows that with minimal data and training, PGT achieves an average relative improvement of 72.0% and 81.6% over 17 tasks in 2 different foundation policies respectively, and outperforms the best human-selected instructions. Moreover, PGT surpasses full fine-tuning in the out-of-distribution (OOD) task-execution environments by 13.4%, indicating that our approach retains strong generalization capabilities. Since our approach stores a single latent representation for each task independently, it can be viewed as an efficient method for continual learning, without the risk of catastrophic forgetting or task interference. In short, PGT enhances the performance of agents across nearly all tasks in the Minecraft Skillforge benchmark and demonstrates robustness to the execution environment.