 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconPhys: Reconstruct Appearance and Physical Attributes from Single Video
Apr 09, 2026Reconstructing non-rigid objects with physical plausibility remains a significant challenge. Existing approaches leverage differentiable rendering for per-scene optimization, recovering geometry and dynamics but requiring expensive tuning or manual annotation, which limits practicality and generalizability. To address this, we propose ReconPhys, the first feedforward framework that jointly learns physical attribute estimation and 3D Gaussian Splatting reconstruction from a single monocular video. Our method employs a dual-branch architecture trained via a self-supervised strategy, eliminating the need for ground-truth physics labels. Given a video sequence, ReconPhys simultaneously infers geometry, appearance, and physical attributes. Experiments on a large-scale synthetic dataset demonstrate superior performance: our method achieves 21.64 PSNR in future prediction compared to 13.27 by state-of-the-art optimization baselines, while reducing Chamfer Distance from 0.349 to 0.004. Crucially, ReconPhys enables fast inference (<1 second) versus hours required by existing methods, facilitating rapid generation of simulation-ready assets for robotics and graphics.
GigaWorld-Policy: An Efficient Action-Centered World--Action Model
Mar 18, 2026World-Action Models (WAM) initialized from pre-trained video generation backbones have demonstrated remarkable potential for robot policy learning. However, existing approaches face two critical bottlenecks that hinder performance and deployment. First, jointly reasoning over future visual dynamics and corresponding actions incurs substantial inference overhead. Second, joint modeling often entangles visual and motion representations, making motion prediction accuracy heavily dependent on the quality of future video forecasts. To address these issues, we introduce GigaWorld-Policy, an action-centered WAM that learns 2D pixel-action dynamics while enabling efficient action decoding, with optional video generation. Specifically, we formulate policy training into two coupled components: the model predicts future action sequences conditioned on the current observation, and simultaneously generates future videos conditioned on the predicted actions and the same observation. The policy is supervised by both action prediction and video generation, providing richer learning signals and encouraging physically plausible actions through visual-dynamics constraints. With a causal design that prevents future-video tokens from influencing action tokens, explicit future-video generation is optional at inference time, allowing faster action prediction during deployment. To support this paradigm, we curate a diverse, large-scale robot dataset to pre-train an action-centered video generation model, which is then adapted as the backbone for robot policy learning. Experimental results on real-world robotic platforms show that GigaWorld-Policy runs 9x faster than the leading WAM baseline, Motus, while improving task success rates by 7%. Moreover, compared with pi-0.5, GigaWorld-Policy improves performance by 95% on RoboTwin 2.0.
GigaBrain-0.5M*: a VLA That Learns From World Model-Based Reinforcement Learning
Feb 12, 2026Vision-language-action (VLA) models that directly predict multi-step action chunks from current observations face inherent limitations due to constrained scene understanding and weak future anticipation capabilities. In contrast, video world models pre-trained on web-scale video corpora exhibit robust spatiotemporal reasoning and accurate future prediction, making them a natural foundation for enhancing VLA learning. Therefore, we propose \textit{GigaBrain-0.5M*}, a VLA model trained via world model-based reinforcement learning. Built upon \textit{GigaBrain-0.5}, which is pre-trained on over 10,000 hours of robotic manipulation data, whose intermediate version currently ranks first on the international RoboChallenge benchmark. \textit{GigaBrain-0.5M*} further integrates world model-based reinforcement learning via \textit{RAMP} (Reinforcement leArning via world Model-conditioned Policy) to enable robust cross-task adaptation. Empirical results demonstrate that \textit{RAMP} achieves substantial performance gains over the RECAP baseline, yielding improvements of approximately 30\% on challenging tasks including \texttt{Laundry Folding}, \texttt{Box Packing}, and \texttt{Espresso Preparation}. Critically, \textit{GigaBrain-0.5M$^*$} exhibits reliable long-horizon execution, consistently accomplishing complex manipulation tasks without failure as validated by real-world deployment videos on our \href{https://gigabrain05m.github.io}{project page}.
VLA-R1: Enhancing Reasoning in Vision-Language-Action Models
Oct 02, 2025Vision-Language-Action (VLA) models aim to unify perception, language understanding, and action generation, offering strong cross-task and cross-scene generalization with broad impact on embodied AI. However, current VLA models often lack explicit step-by-step reasoning, instead emitting final actions without considering affordance constraints or geometric relations. Their post-training pipelines also rarely reinforce reasoning quality, relying primarily on supervised fine-tuning with weak reward design. To address these challenges, we present VLA-R1, a reasoning-enhanced VLA that integrates Reinforcement Learning from Verifiable Rewards (RLVR) with Group Relative Policy Optimization (GRPO) to systematically optimize both reasoning and execution. Specifically, we design an RLVR-based post-training strategy with verifiable rewards for region alignment, trajectory consistency, and output formatting, thereby strengthening reasoning robustness and execution accuracy. Moreover, we develop VLA-CoT-13K, a high-quality dataset that provides chain-of-thought supervision explicitly aligned with affordance and trajectory annotations. Furthermore, extensive evaluations on in-domain, out-of-domain, simulation, and real-robot platforms demonstrate that VLA-R1 achieves superior generalization and real-world performance compared to prior VLA methods. We plan to release the model, code, and dataset following the publication of this work. Code: https://github.com/GigaAI-research/VLA-R1. Website: https://gigaai-research.github.io/VLA-R1.
MimicDreamer: Aligning Human and Robot Demonstrations for Scalable VLA Training
Sep 26, 2025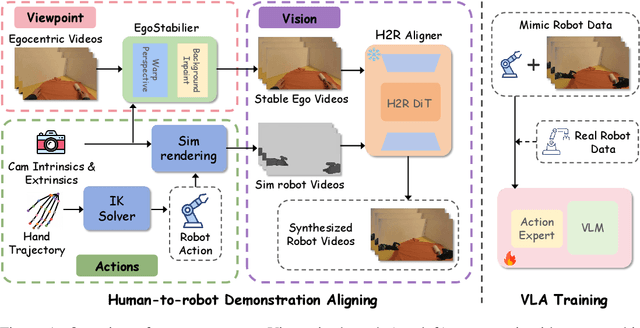

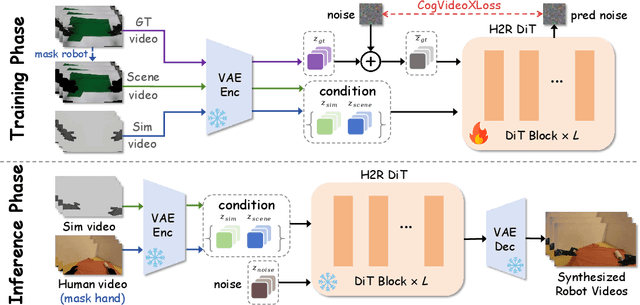
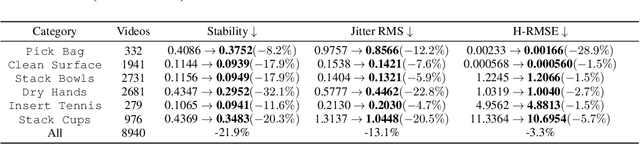
Vision Language Action (VLA) models derive their generalization capability from diverse training data, yet collecting embodied robot interaction data remains prohibitively expensive. In contrast, human demonstration videos are far more scalable and cost-efficient to collect, and recent studies confirm their effectiveness in training VLA models. However, a significant domain gap persists between human videos and robot-executed videos, including unstable camera viewpoints, visual discrepancies between human hands and robotic arms, and differences in motion dynamics. To bridge this gap, we propose MimicDreamer, a framework that turns fast, low-cost human demonstrations into robot-usable supervision by jointly aligning vision, viewpoint, and actions to directly support policy training. For visual alignment, we propose H2R Aligner, a video diffusion model that generates high-fidelity robot demonstration videos by transferring motion from human manipulation footage. For viewpoint stabilization, EgoStabilizer is proposed, which canonicalizes egocentric videos via homography and inpaints occlusions and distortions caused by warping. For action alignment, we map human hand trajectories to the robot frame and apply a constrained inverse kinematics solver to produce feasible, low-jitter joint commands with accurate pose tracking. Empirically, VLA models trained purely on our synthesized human-to-robot videos achieve few-shot execution on real robots. Moreover, scaling training with human data significantly boosts performance compared to models trained solely on real robot data; our approach improves the average success rate by 14.7\% across six representative manipulation tasks.
EMMA: Generalizing Real-World Robot Manipulation via Generative Visual Transfer
Sep 26, 2025
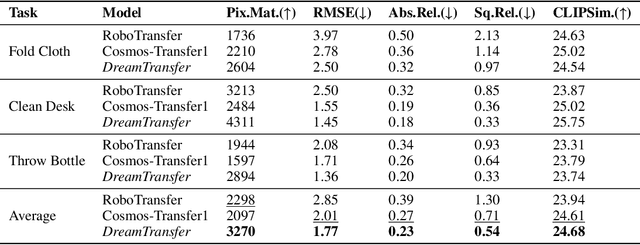
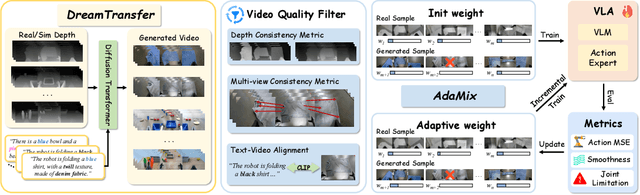
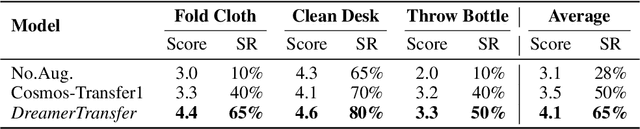
Vision-language-action (VLA) models increasingly rely on diverse training data to achieve robust generalization. However, collecting large-scale real-world robot manipulation data across varied object appearances and environmental conditions remains prohibitively time-consuming and expensive. To overcome this bottleneck, we propose Embodied Manipulation Media Adaptation (EMMA), a VLA policy enhancement framework that integrates a generative data engine with an effective training pipeline. We introduce DreamTransfer, a diffusion Transformer-based framework for generating multi-view consistent, geometrically grounded embodied manipulation videos. DreamTransfer enables text-controlled visual editing of robot videos, transforming foreground, background, and lighting conditions without compromising 3D structure or geometrical plausibility. Furthermore, we explore hybrid training with real and generated data, and introduce AdaMix, a hard-sample-aware training strategy that dynamically reweights training batches to focus optimization on perceptually or kinematically challenging samples. Extensive experiments show that videos generated by DreamTransfer significantly outperform prior video generation methods in multi-view consistency, geometric fidelity, and text-conditioning accuracy. Crucially, VLAs trained with generated data enable robots to generalize to unseen object categories and novel visual domains using only demonstrations from a single appearance. In real-world robotic manipulation tasks with zero-shot visual domains, our approach achieves over a 200% relative performance gain compared to training on real data alone, and further improves by 13% with AdaMix, demonstrating its effectiveness in boosting policy generalization.
WonderFree: Enhancing Novel View Quality and Cross-View Consistency for 3D Scene Exploration
Jun 25, 2025Interactive 3D scene generation from a single image has gained significant attention due to its potential to create immersive virtual worlds. However, a key challenge in current 3D generation methods is the limited explorability, which cannot render high-quality images during larger maneuvers beyond the original viewpoint, particularly when attempting to move forward into unseen areas. To address this challenge, we propose WonderFree, the first model that enables users to interactively generate 3D worlds with the freedom to explore from arbitrary angles and directions. Specifically, we decouple this challenge into two key subproblems: novel view quality, which addresses visual artifacts and floating issues in novel views, and cross-view consistency, which ensures spatial consistency across different viewpoints. To enhance rendering quality in novel views, we introduce WorldRestorer, a data-driven video restoration model designed to eliminate floaters and artifacts. In addition, a data collection pipeline is presented to automatically gather training data for WorldRestorer, ensuring it can handle scenes with varying styles needed for 3D scene generation. Furthermore, to improve cross-view consistency, we propose ConsistView, a multi-view joint restoration mechanism that simultaneously restores multiple perspectives while maintaining spatiotemporal coherence. Experimental results demonstrate that WonderFree not only enhances rendering quality across diverse viewpoints but also significantly improves global coherence and consistency. These improvements are confirmed by CLIP-based metrics and a user study showing a 77.20% preference for WonderFree over WonderWorld enabling a seamless and immersive 3D exploration experience. The code, model, and data will be publicly available.
HumanDreamer-X: Photorealistic Single-image Human Avatars Reconstruction via Gaussian Restoration
Apr 04, 2025
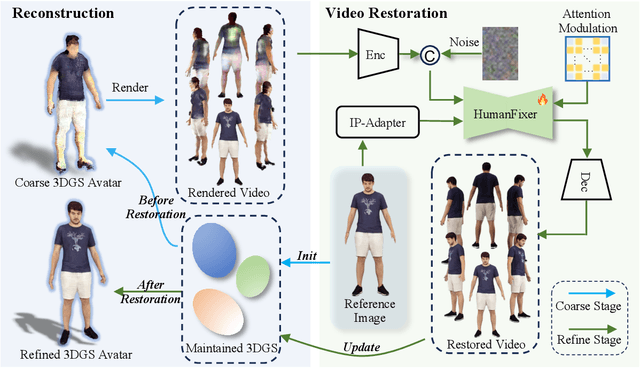

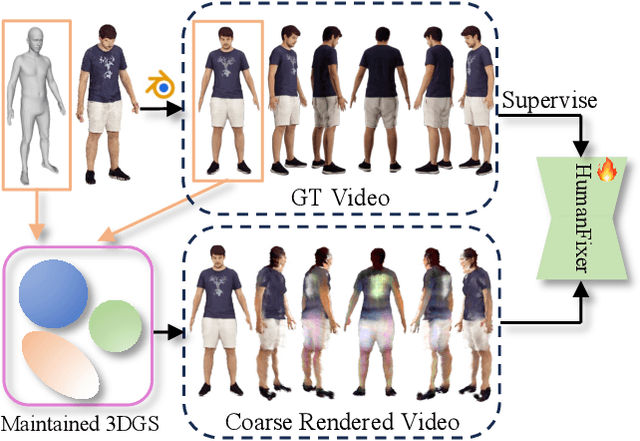
Single-image human reconstruction is vital for digital human modeling applications but remains an extremely challenging task. Current approaches rely on generative models to synthesize multi-view images for subsequent 3D reconstruction and animation. However, directly generating multiple views from a single human image suffers from geometric inconsistencies, resulting in issues like fragmented or blurred limbs in the reconstructed models. To tackle these limitations, we introduce \textbf{HumanDreamer-X}, a novel framework that integrates multi-view human generation and reconstruction into a unified pipeline, which significantly enhances the geometric consistency and visual fidelity of the reconstructed 3D models. In this framework, 3D Gaussian Splatting serves as an explicit 3D representation to provide initial geometry and appearance priority. Building upon this foundation, \textbf{HumanFixer} is trained to restore 3DGS renderings, which guarantee photorealistic results. Furthermore, we delve into the inherent challenges associated with attention mechanisms in multi-view human generation, and propose an attention modulation strategy that effectively enhances geometric details identity consistency across multi-view. Experimental results demonstrate that our approach markedly improves generation and reconstruction PSNR quality metrics by 16.45% and 12.65%, respectively, achieving a PSNR of up to 25.62 dB, while also showing generalization capabilities on in-the-wild data and applicability to various human reconstruction backbone models.
HumanDreamer: Generating Controllable Human-Motion Videos via Decoupled Generation
Apr 01, 2025Human-motion video generation has been a challenging task, primarily due to the difficulty inherent in learning human body movements. While some approaches have attempted to drive human-centric video generation explicitly through pose control, these methods typically rely on poses derived from existing videos, thereby lacking flexibility. To address this, we propose HumanDreamer, a decoupled human video generation framework that first generates diverse poses from text prompts and then leverages these poses to generate human-motion videos. Specifically, we propose MotionVid, the largest dataset for human-motion pose generation. Based on the dataset, we present MotionDiT, which is trained to generate structured human-motion poses from text prompts. Besides, a novel LAMA loss is introduced, which together contribute to a significant improvement in FID by 62.4%, along with respective enhancements in R-precision for top1, top2, and top3 by 41.8%, 26.3%, and 18.3%, thereby advancing both the Text-to-Pose control accuracy and FID metrics. Our experiments across various Pose-to-Video baselines demonstrate that the poses generated by our method can produce diverse and high-quality human-motion videos. Furthermore, our model can facilitate other downstream tasks, such as pose sequence prediction and 2D-3D motion lifting.
Latent Reward: LLM-Empowered Credit Assignment in Episodic Reinforcement Learning
Dec 15, 2024



Reinforcement learning (RL) often encounters delayed and sparse feedback in real-world applications, even with only episodic rewards. Previous approaches have made some progress in reward redistribution for credit assignment but still face challenges, including training difficulties due to redundancy and ambiguous attributions stemming from overlooking the multifaceted nature of mission performance evaluation. Hopefully, Large Language Model (LLM) encompasses fruitful decision-making knowledge and provides a plausible tool for reward redistribution. Even so, deploying LLM in this case is non-trivial due to the misalignment between linguistic knowledge and the symbolic form requirement, together with inherent randomness and hallucinations in inference. To tackle these issues, we introduce LaRe, a novel LLM-empowered symbolic-based decision-making framework, to improve credit assignment. Key to LaRe is the concept of the Latent Reward, which works as a multi-dimensional performance evaluation, enabling more interpretable goal attainment from various perspectives and facilitating more effective reward redistribution. We examine that semantically generated code from LLM can bridge linguistic knowledge and symbolic latent rewards, as it is executable for symbolic objects. Meanwhile, we design latent reward self-verification to increase the stability and reliability of LLM inference. Theoretically, reward-irrelevant redundancy elimination in the latent reward benefits RL performance from more accurate reward estimation. Extensive experimental results witness that LaRe (i) achieves superior temporal credit assignment to SOTA methods, (ii) excels in allocating contributions among multiple agents, and (iii) outperforms policies trained with ground truth rewards for certain tasks.