 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDriveDreamer: A Single-Stage Multimodal World Model for Autonomous Driving
Feb 02, 2026World models have demonstrated significant promise for data synthesis in autonomous driving. However, existing methods predominantly concentrate on single-modality generation, typically focusing on either multi-camera video or LiDAR sequence synthesis. In this paper, we propose UniDriveDreamer, a single-stage unified multimodal world model for autonomous driving, which directly generates multimodal future observations without relying on intermediate representations or cascaded modules. Our framework introduces a LiDAR-specific variational autoencoder (VAE) designed to encode input LiDAR sequences, alongside a video VAE for multi-camera images. To ensure cross-modal compatibility and training stability, we propose Unified Latent Anchoring (ULA), which explicitly aligns the latent distributions of the two modalities. The aligned features are fused and processed by a diffusion transformer that jointly models their geometric correspondence and temporal evolution. Additionally, structured scene layout information is projected per modality as a conditioning signal to guide the synthesis. Extensive experiments demonstrate that UniDriveDreamer outperforms previous state-of-the-art methods in both video and LiDAR generation, while also yielding measurable improvements in downstream
ReconDreamer-RL: Enhancing Reinforcement Learning via Diffusion-based Scene Reconstruction
Aug 11, 2025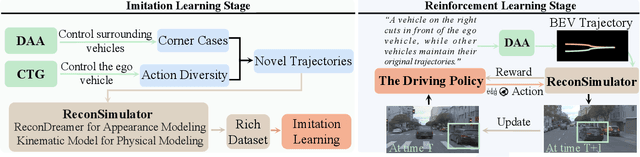


Reinforcement learning for training end-to-end autonomous driving models in closed-loop simulations is gaining growing attention. However, most simulation environments differ significantly from real-world conditions, creating a substantial simulation-to-reality (sim2real) gap. To bridge this gap, some approaches utilize scene reconstruction techniques to create photorealistic environments as a simulator. While this improves realistic sensor simulation, these methods are inherently constrained by the distribution of the training data, making it difficult to render high-quality sensor data for novel trajectories or corner case scenarios. Therefore, we propose ReconDreamer-RL, a framework designed to integrate video diffusion priors into scene reconstruction to aid reinforcement learning, thereby enhancing end-to-end autonomous driving training. Specifically, in ReconDreamer-RL, we introduce ReconSimulator, which combines the video diffusion prior for appearance modeling and incorporates a kinematic model for physical modeling, thereby reconstructing driving scenarios from real-world data. This narrows the sim2real gap for closed-loop evaluation and reinforcement learning. To cover more corner-case scenarios, we introduce the Dynamic Adversary Agent (DAA), which adjusts the trajectories of surrounding vehicles relative to the ego vehicle, autonomously generating corner-case traffic scenarios (e.g., cut-in). Finally, the Cousin Trajectory Generator (CTG) is proposed to address the issue of training data distribution, which is often biased toward simple straight-line movements. Experiments show that ReconDreamer-RL improves end-to-end autonomous driving training, outperforming imitation learning methods with a 5x reduction in the Collision Ratio.
WonderFree: Enhancing Novel View Quality and Cross-View Consistency for 3D Scene Exploration
Jun 25, 2025Interactive 3D scene generation from a single image has gained significant attention due to its potential to create immersive virtual worlds. However, a key challenge in current 3D generation methods is the limited explorability, which cannot render high-quality images during larger maneuvers beyond the original viewpoint, particularly when attempting to move forward into unseen areas. To address this challenge, we propose WonderFree, the first model that enables users to interactively generate 3D worlds with the freedom to explore from arbitrary angles and directions. Specifically, we decouple this challenge into two key subproblems: novel view quality, which addresses visual artifacts and floating issues in novel views, and cross-view consistency, which ensures spatial consistency across different viewpoints. To enhance rendering quality in novel views, we introduce WorldRestorer, a data-driven video restoration model designed to eliminate floaters and artifacts. In addition, a data collection pipeline is presented to automatically gather training data for WorldRestorer, ensuring it can handle scenes with varying styles needed for 3D scene generation. Furthermore, to improve cross-view consistency, we propose ConsistView, a multi-view joint restoration mechanism that simultaneously restores multiple perspectives while maintaining spatiotemporal coherence. Experimental results demonstrate that WonderFree not only enhances rendering quality across diverse viewpoints but also significantly improves global coherence and consistency. These improvements are confirmed by CLIP-based metrics and a user study showing a 77.20% preference for WonderFree over WonderWorld enabling a seamless and immersive 3D exploration experience. The code, model, and data will be publicly available.
RoboTransfer: Geometry-Consistent Video Diffusion for Robotic Visual Policy Transfer
May 29, 2025Imitation Learning has become a fundamental approach in robotic manipulation. However, collecting large-scale real-world robot demonstrations is prohibitively expensive. Simulators offer a cost-effective alternative, but the sim-to-real gap make it extremely challenging to scale. Therefore, we introduce RoboTransfer, a diffusion-based video generation framework for robotic data synthesis. Unlike previous methods, RoboTransfer integrates multi-view geometry with explicit control over scene components, such as background and object attributes. By incorporating cross-view feature interactions and global depth/normal conditions, RoboTransfer ensures geometry consistency across views. This framework allows fine-grained control, including background edits and object swaps. Experiments demonstrate that RoboTransfer is capable of generating multi-view videos with enhanced geometric consistency and visual fidelity. In addition, policies trained on the data generated by RoboTransfer achieve a 33.3% relative improvement in the success rate in the DIFF-OBJ setting and a substantial 251% relative improvement in the more challenging DIFF-ALL scenario. Explore more demos on our project page: https://horizonrobotics.github.io/robot_lab/robotransfer
HumanDreamer-X: Photorealistic Single-image Human Avatars Reconstruction via Gaussian Restoration
Apr 04, 2025
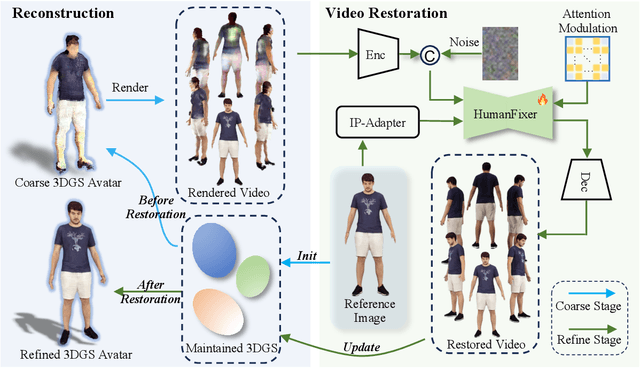

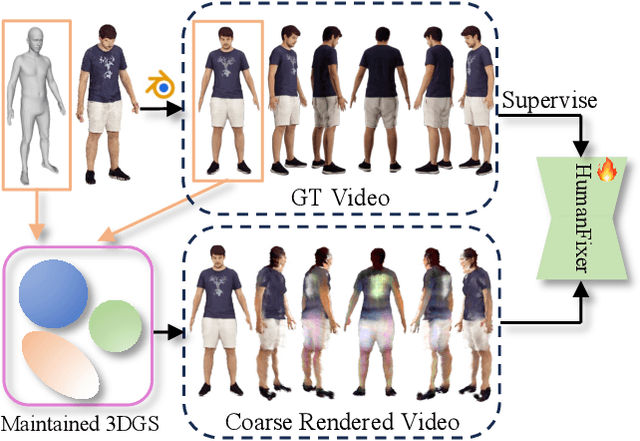
Single-image human reconstruction is vital for digital human modeling applications but remains an extremely challenging task. Current approaches rely on generative models to synthesize multi-view images for subsequent 3D reconstruction and animation. However, directly generating multiple views from a single human image suffers from geometric inconsistencies, resulting in issues like fragmented or blurred limbs in the reconstructed models. To tackle these limitations, we introduce \textbf{HumanDreamer-X}, a novel framework that integrates multi-view human generation and reconstruction into a unified pipeline, which significantly enhances the geometric consistency and visual fidelity of the reconstructed 3D models. In this framework, 3D Gaussian Splatting serves as an explicit 3D representation to provide initial geometry and appearance priority. Building upon this foundation, \textbf{HumanFixer} is trained to restore 3DGS renderings, which guarantee photorealistic results. Furthermore, we delve into the inherent challenges associated with attention mechanisms in multi-view human generation, and propose an attention modulation strategy that effectively enhances geometric details identity consistency across multi-view. Experimental results demonstrate that our approach markedly improves generation and reconstruction PSNR quality metrics by 16.45% and 12.65%, respectively, achieving a PSNR of up to 25.62 dB, while also showing generalization capabilities on in-the-wild data and applicability to various human reconstruction backbone models.
WonderTurbo: Generating Interactive 3D World in 0.72 Seconds
Apr 03, 2025



Interactive 3D generation is gaining momentum and capturing extensive attention for its potential to create immersive virtual experiences. However, a critical challenge in current 3D generation technologies lies in achieving real-time interactivity. To address this issue, we introduce WonderTurbo, the first real-time interactive 3D scene generation framework capable of generating novel perspectives of 3D scenes within 0.72 seconds. Specifically, WonderTurbo accelerates both geometric and appearance modeling in 3D scene generation. In terms of geometry, we propose StepSplat, an innovative method that constructs efficient 3D geometric representations through dynamic updates, each taking only 0.26 seconds. Additionally, we design QuickDepth, a lightweight depth completion module that provides consistent depth input for StepSplat, further enhancing geometric accuracy. For appearance modeling, we develop FastPaint, a 2-steps diffusion model tailored for instant inpainting, which focuses on maintaining spatial appearance consistency. Experimental results demonstrate that WonderTurbo achieves a remarkable 15X speedup compared to baseline methods, while preserving excellent spatial consistency and delivering high-quality output.
HumanDreamer: Generating Controllable Human-Motion Videos via Decoupled Generation
Apr 01, 2025Human-motion video generation has been a challenging task, primarily due to the difficulty inherent in learning human body movements. While some approaches have attempted to drive human-centric video generation explicitly through pose control, these methods typically rely on poses derived from existing videos, thereby lacking flexibility. To address this, we propose HumanDreamer, a decoupled human video generation framework that first generates diverse poses from text prompts and then leverages these poses to generate human-motion videos. Specifically, we propose MotionVid, the largest dataset for human-motion pose generation. Based on the dataset, we present MotionDiT, which is trained to generate structured human-motion poses from text prompts. Besides, a novel LAMA loss is introduced, which together contribute to a significant improvement in FID by 62.4%, along with respective enhancements in R-precision for top1, top2, and top3 by 41.8%, 26.3%, and 18.3%, thereby advancing both the Text-to-Pose control accuracy and FID metrics. Our experiments across various Pose-to-Video baselines demonstrate that the poses generated by our method can produce diverse and high-quality human-motion videos. Furthermore, our model can facilitate other downstream tasks, such as pose sequence prediction and 2D-3D motion lifting.
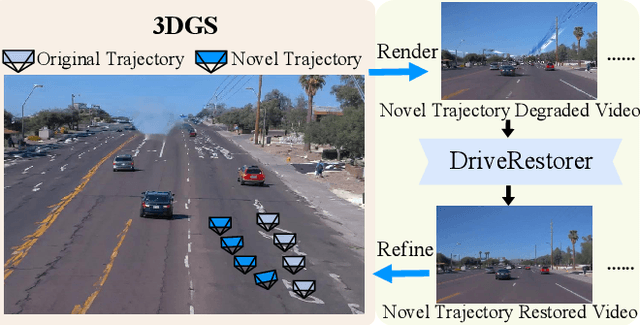
ReconDreamer: Crafting World Models for Driving Scene Reconstruction via Online Restoration
Nov 29, 2024



Closed-loop simulation is crucial for end-to-end autonomous driving. Existing sensor simulation methods (e.g., NeRF and 3DGS) reconstruct driving scenes based on conditions that closely mirror training data distributions. However, these methods struggle with rendering novel trajectories, such as lane changes. Recent works have demonstrated that integrating world model knowledge alleviates these issues. Despite their efficiency, these approaches still encounter difficulties in the accurate representation of more complex maneuvers, with multi-lane shifts being a notable example. Therefore, we introduce ReconDreamer, which enhances driving scene reconstruction through incremental integration of world model knowledge. Specifically, DriveRestorer is proposed to mitigate artifacts via online restoration. This is complemented by a progressive data update strategy designed to ensure high-quality rendering for more complex maneuvers. To the best of our knowledge, ReconDreamer is the first method to effectively render in large maneuvers. Experimental results demonstrate that ReconDreamer outperforms Street Gaussians in the NTA-IoU, NTL-IoU, and FID, with relative improvements by 24.87%, 6.72%, and 29.97%. Furthermore, ReconDreamer surpasses DriveDreamer4D with PVG during large maneuver rendering, as verified by a relative improvement of 195.87% in the NTA-IoU metric and a comprehensive user study.
EgoVid-5M: A Large-Scale Video-Action Dataset for Egocentric Video Generation
Nov 13, 2024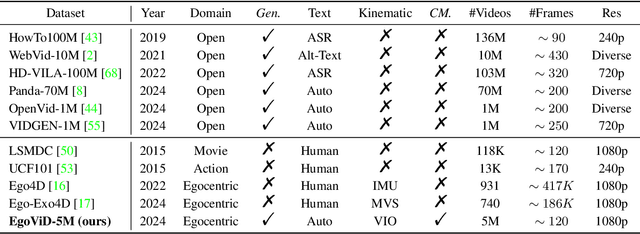
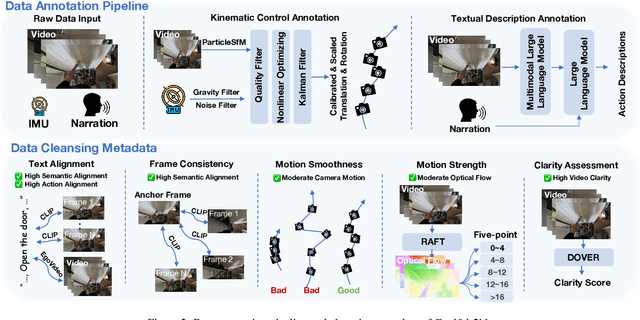
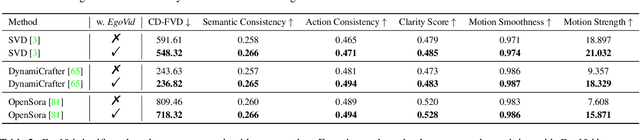
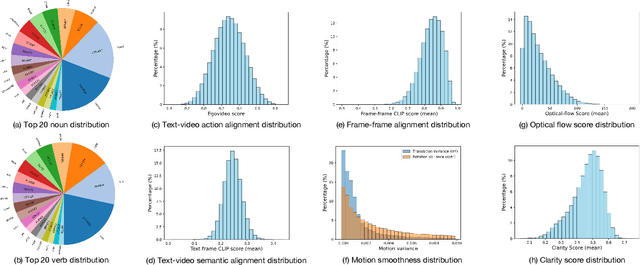
Video generation has emerged as a promising tool for world simulation, leveraging visual data to replicate real-world environments. Within this context, egocentric video generation, which centers on the human perspective, holds significant potential for enhancing applications in virtual reality, augmented reality, and gaming. However, the generation of egocentric videos presents substantial challenges due to the dynamic nature of egocentric viewpoints, the intricate diversity of actions, and the complex variety of scenes encountered. Existing datasets are inadequate for addressing these challenges effectively. To bridge this gap, we present EgoVid-5M, the first high-quality dataset specifically curated for egocentric video generation. EgoVid-5M encompasses 5 million egocentric video clips and is enriched with detailed action annotations, including fine-grained kinematic control and high-level textual descriptions. To ensure the integrity and usability of the dataset, we implement a sophisticated data cleaning pipeline designed to maintain frame consistency, action coherence, and motion smoothness under egocentric conditions. Furthermore, we introduce EgoDreamer, which is capable of generating egocentric videos driven simultaneously by action descriptions and kinematic control signals. The EgoVid-5M dataset, associated action annotations, and all data cleansing metadata will be released for the advancement of research in egocentric video generation.
DriveDreamer4D: World Models Are Effective Data Machines for 4D Driving Scene Representation
Oct 17, 2024



Closed-loop simulation is essential for advancing end-to-end autonomous driving systems. Contemporary sensor simulation methods, such as NeRF and 3DGS, rely predominantly on conditions closely aligned with training data distributions, which are largely confined to forward-driving scenarios. Consequently, these methods face limitations when rendering complex maneuvers (e.g., lane change, acceleration, deceleration). Recent advancements in autonomous-driving world models have demonstrated the potential to generate diverse driving videos. However, these approaches remain constrained to 2D video generation, inherently lacking the spatiotemporal coherence required to capture intricacies of dynamic driving environments. In this paper, we introduce \textit{DriveDreamer4D}, which enhances 4D driving scene representation leveraging world model priors. Specifically, we utilize the world model as a data machine to synthesize novel trajectory videos based on real-world driving data. Notably, we explicitly leverage structured conditions to control the spatial-temporal consistency of foreground and background elements, thus the generated data adheres closely to traffic constraints. To our knowledge, \textit{DriveDreamer4D} is the first to utilize video generation models for improving 4D reconstruction in driving scenarios. Experimental results reveal that \textit{DriveDreamer4D} significantly enhances generation quality under novel trajectory views, achieving a relative improvement in FID by 24.5\%, 39.0\%, and 10.5\% compared to PVG, $\text{S}^3$Gaussian, and Deformable-GS. Moreover, \textit{DriveDreamer4D} markedly enhances the spatiotemporal coherence of driving agents, which is verified by a comprehensive user study and the relative increases of 20.3\%, 42.0\%, and 13.7\% in the NTA-IoU metric.