 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabEmbed: Benchmarking and Learning Generalist Embeddings for Tabular Understanding
May 06, 2026Foundation models have established unified representations for natural language processing, yet this paradigm remains largely unexplored for tabular data. Existing methods face fundamental limitations: LLM-based approaches lack retrieval-compatible vector outputs, whereas text embedding models often fail to capture tabular structure and numerical semantics. To bridge this gap, we first introduce the Tabular Embedding Benchmark (TabBench), a comprehensive suite designed to evaluate the tabular understanding capability of embedding models. We then propose TabEmbed, the first generalist embedding model that unifies tabular classification and retrieval within a shared embedding space. By reformulating diverse tabular tasks as semantic matching problems, TabEmbed leverages large-scale contrastive learning with positive-aware hard negative mining to discern fine-grained structural and numerical nuances. Experimental results on TabBench demonstrate that TabEmbed significantly outperforms state-of-the-art text embedding models, establishing a new baseline for universal tabular representation learning. Code and datasets are publicly available at https://github.com/qiangminjie27/TabEmbed and https://huggingface.co/datasets/qiangminjie27/TabBench.
AG-VAS: Anchor-Guided Zero-Shot Visual Anomaly Segmentation with Large Multimodal Models
Mar 01, 2026Large multimodal models (LMMs) exhibit strong task generalization capabilities, offering new opportunities for zero-shot visual anomaly segmentation (ZSAS). However, existing LMM-based segmentation approaches still face fundamental limitations: anomaly concepts are inherently abstract and context-dependent, lacking stable visual prototypes, and the weak alignment between high-level semantic embeddings and pixel-level spatial features hinders precise anomaly localization. To address these challenges, we present AG-VAS (Anchor-Guided Visual Anomaly Segmentation), a new framework that expands the LMM vocabulary with three learnable semantic anchor tokens-[SEG], [NOR], and [ANO], establishing a unified anchor-guided segmentation paradigm. Specifically, [SEG] serves as an absolute semantic anchor that translates abstract anomaly semantics into explicit, spatially grounded visual entities (e.g., holes or scratches), while [NOR] and [ANO] act as relative anchors that model the contextual contrast between normal and abnormal patterns across categories. To further enhance cross-modal alignment, we introduce a Semantic-Pixel Alignment Module (SPAM) that aligns language-level semantic embeddings with high-resolution visual features, along with an Anchor-Guided Mask Decoder (AGMD) that performs anchor-conditioned mask prediction for precise anomaly localization. In addition, we curate Anomaly-Instruct20K, a large-scale instruction dataset that organizes anomaly knowledge into structured descriptions of appearance, shape, and spatial attributes, facilitating effective learning and integration of the proposed semantic anchors. Extensive experiments on six industrial and medical benchmarks demonstrate that AG-VAS achieves consistent state-of-the-art performance in the zero-shot setting.
ShowTable: Unlocking Creative Table Visualization with Collaborative Reflection and Refinement
Dec 15, 2025While existing generation and unified models excel at general image generation, they struggle with tasks requiring deep reasoning, planning, and precise data-to-visual mapping abilities beyond general scenarios. To push beyond the existing limitations, we introduce a new and challenging task: creative table visualization, requiring the model to generate an infographic that faithfully and aesthetically visualizes the data from a given table. To address this challenge, we propose ShowTable, a pipeline that synergizes MLLMs with diffusion models via a progressive self-correcting process. The MLLM acts as the central orchestrator for reasoning the visual plan and judging visual errors to provide refined instructions, the diffusion execute the commands from MLLM, achieving high-fidelity results. To support this task and our pipeline, we introduce three automated data construction pipelines for training different modules. Furthermore, we introduce TableVisBench, a new benchmark with 800 challenging instances across 5 evaluation dimensions, to assess performance on this task. Experiments demonstrate that our pipeline, instantiated with different models, significantly outperforms baselines, highlighting its effective multi-modal reasoning, generation, and error correction capabilities.
Learning to Look at the Other Side: A Semantic Probing Study of Word Embeddings in LLMs with Enabled Bidirectional Attention
Oct 02, 2025Autoregressive Large Language Models (LLMs) demonstrate exceptional performance in language understanding and generation. However, their application in text embedding tasks has been relatively slow, along with the analysis of their semantic representation in probing tasks, due to the constraints of the unidirectional attention mechanism. This paper aims to explore whether such constraints can be overcome by enabling bidirectional attention in LLMs. We tested different variants of the Llama architecture through additional training steps, progressively enabling bidirectional attention and unsupervised/supervised contrastive learning.
GigaVideo-1: Advancing Video Generation via Automatic Feedback with 4 GPU-Hours Fine-Tuning
Jun 12, 2025
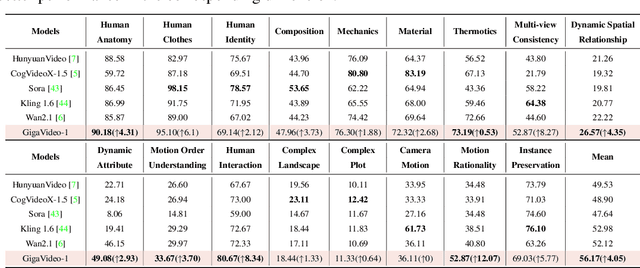
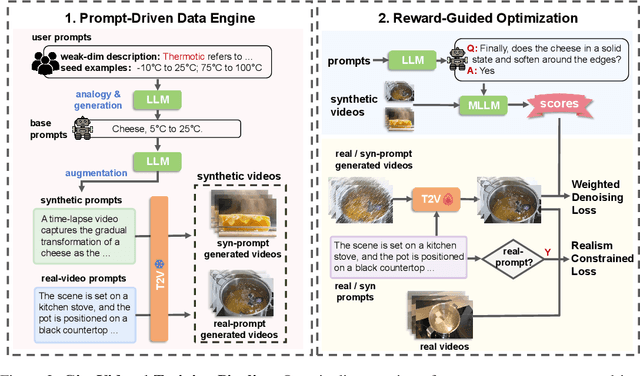

Recent progress in diffusion models has greatly enhanced video generation quality, yet these models still require fine-tuning to improve specific dimensions like instance preservation, motion rationality, composition, and physical plausibility. Existing fine-tuning approaches often rely on human annotations and large-scale computational resources, limiting their practicality. In this work, we propose GigaVideo-1, an efficient fine-tuning framework that advances video generation without additional human supervision. Rather than injecting large volumes of high-quality data from external sources, GigaVideo-1 unlocks the latent potential of pre-trained video diffusion models through automatic feedback. Specifically, we focus on two key aspects of the fine-tuning process: data and optimization. To improve fine-tuning data, we design a prompt-driven data engine that constructs diverse, weakness-oriented training samples. On the optimization side, we introduce a reward-guided training strategy, which adaptively weights samples using feedback from pre-trained vision-language models with a realism constraint. We evaluate GigaVideo-1 on the VBench-2.0 benchmark using Wan2.1 as the baseline across 17 evaluation dimensions. Experiments show that GigaVideo-1 consistently improves performance on almost all the dimensions with an average gain of about 4% using only 4 GPU-hours. Requiring no manual annotations and minimal real data, GigaVideo-1 demonstrates both effectiveness and efficiency. Code, model, and data will be publicly available.
Aligned Better, Listen Better for Audio-Visual Large Language Models
Apr 02, 2025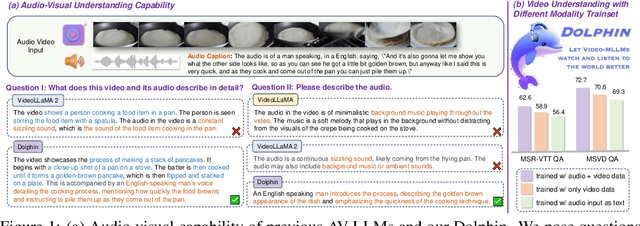

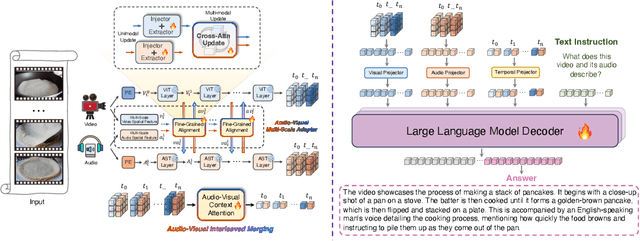
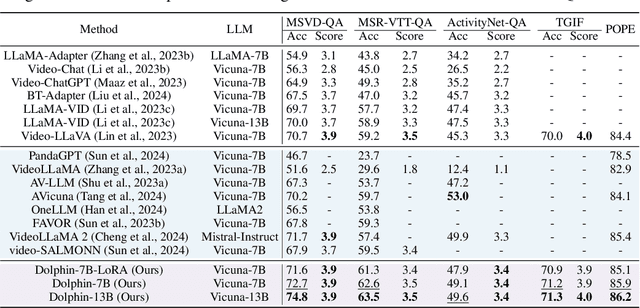
Audio is essential for multimodal video understanding. On the one hand, video inherently contains audio, which supplies complementary information to vision. Besides, video large language models (Video-LLMs) can encounter many audio-centric settings. However, existing Video-LLMs and Audio-Visual Large Language Models (AV-LLMs) exhibit deficiencies in exploiting audio information, leading to weak understanding and hallucinations. To solve the issues, we delve into the model architecture and dataset. (1) From the architectural perspective, we propose a fine-grained AV-LLM, namely Dolphin. The concurrent alignment of audio and visual modalities in both temporal and spatial dimensions ensures a comprehensive and accurate understanding of videos. Specifically, we devise an audio-visual multi-scale adapter for multi-scale information aggregation, which achieves spatial alignment. For temporal alignment, we propose audio-visual interleaved merging. (2) From the dataset perspective, we curate an audio-visual caption and instruction-tuning dataset, called AVU. It comprises 5.2 million diverse, open-ended data tuples (video, audio, question, answer) and introduces a novel data partitioning strategy. Extensive experiments show our model not only achieves remarkable performance in audio-visual understanding, but also mitigates potential hallucinations.
UFO: A Unified Approach to Fine-grained Visual Perception via Open-ended Language Interface
Mar 04, 2025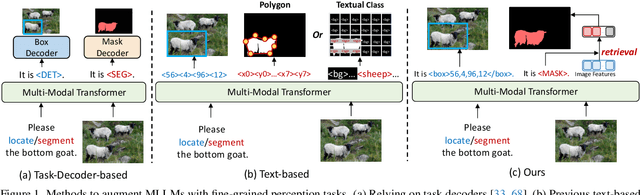
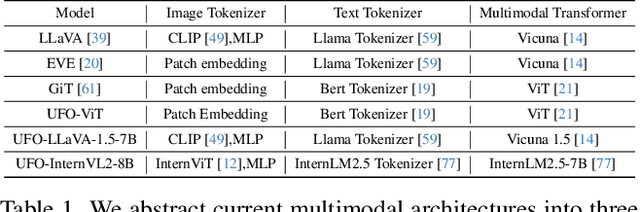
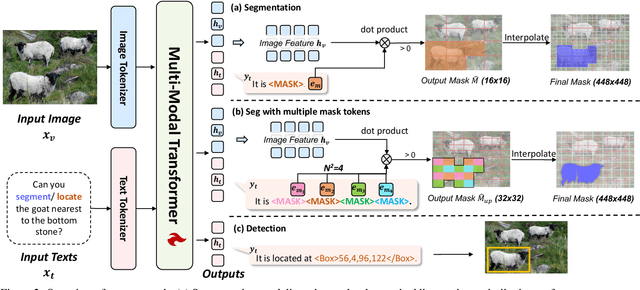
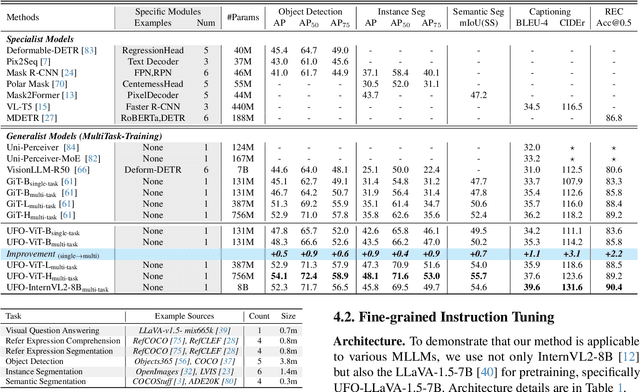
Generalist models have achieved remarkable success in both language and vision-language tasks, showcasing the potential of unified modeling. However, effectively integrating fine-grained perception tasks like detection and segmentation into these models remains a significant challenge. This is primarily because these tasks often rely heavily on task-specific designs and architectures that can complicate the modeling process. To address this challenge, we present \ours, a framework that \textbf{U}nifies \textbf{F}ine-grained visual perception tasks through an \textbf{O}pen-ended language interface. By transforming all perception targets into the language space, \ours unifies object-level detection, pixel-level segmentation, and image-level vision-language tasks into a single model. Additionally, we introduce a novel embedding retrieval approach that relies solely on the language interface to support segmentation tasks. Our framework bridges the gap between fine-grained perception and vision-language tasks, significantly simplifying architectural design and training strategies while achieving comparable or superior performance to methods with intricate task-specific designs. After multi-task training on five standard visual perception datasets, \ours outperforms the previous state-of-the-art generalist models by 12.3 mAP on COCO instance segmentation and 3.3 mIoU on ADE20K semantic segmentation. Furthermore, our method seamlessly integrates with existing MLLMs, effectively combining fine-grained perception capabilities with their advanced language abilities, thereby enabling more challenging tasks such as reasoning segmentation. Code and models are available at https://github.com/nnnth/UFO.
EgoVid-5M: A Large-Scale Video-Action Dataset for Egocentric Video Generation
Nov 13, 2024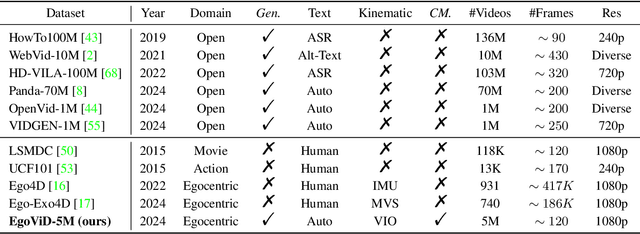
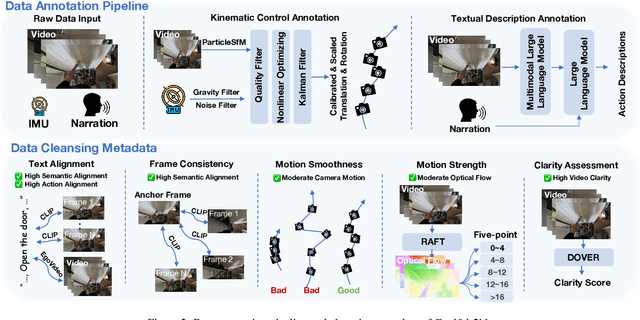
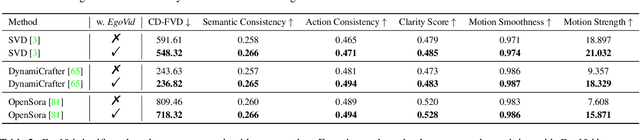
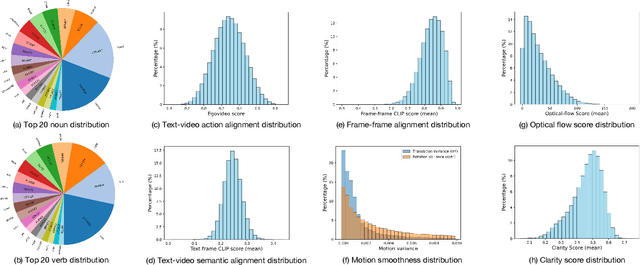
Video generation has emerged as a promising tool for world simulation, leveraging visual data to replicate real-world environments. Within this context, egocentric video generation, which centers on the human perspective, holds significant potential for enhancing applications in virtual reality, augmented reality, and gaming. However, the generation of egocentric videos presents substantial challenges due to the dynamic nature of egocentric viewpoints, the intricate diversity of actions, and the complex variety of scenes encountered. Existing datasets are inadequate for addressing these challenges effectively. To bridge this gap, we present EgoVid-5M, the first high-quality dataset specifically curated for egocentric video generation. EgoVid-5M encompasses 5 million egocentric video clips and is enriched with detailed action annotations, including fine-grained kinematic control and high-level textual descriptions. To ensure the integrity and usability of the dataset, we implement a sophisticated data cleaning pipeline designed to maintain frame consistency, action coherence, and motion smoothness under egocentric conditions. Furthermore, we introduce EgoDreamer, which is capable of generating egocentric videos driven simultaneously by action descriptions and kinematic control signals. The EgoVid-5M dataset, associated action annotations, and all data cleansing metadata will be released for the advancement of research in egocentric video generation.
CoReS: Orchestrating the Dance of Reasoning and Segmentation
Apr 08, 2024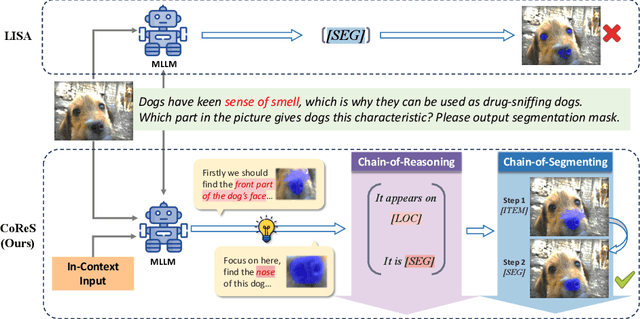
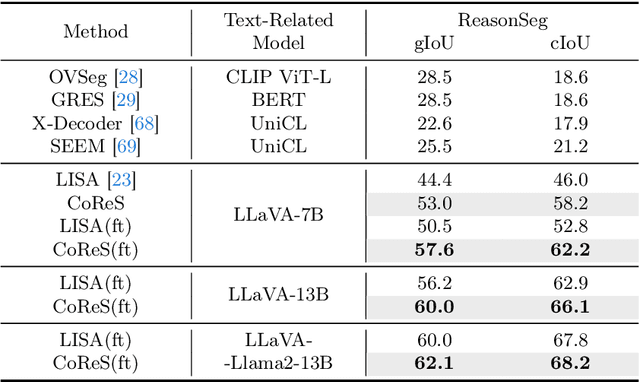
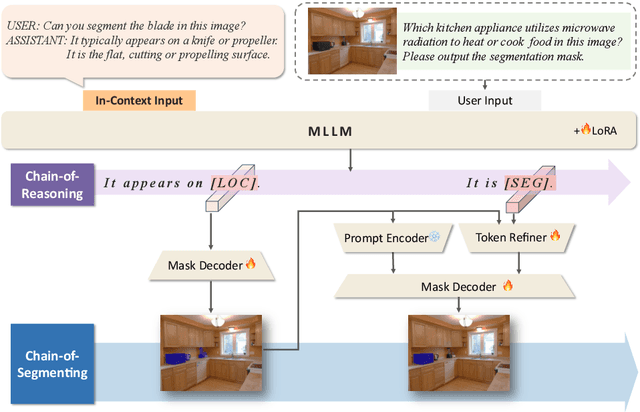
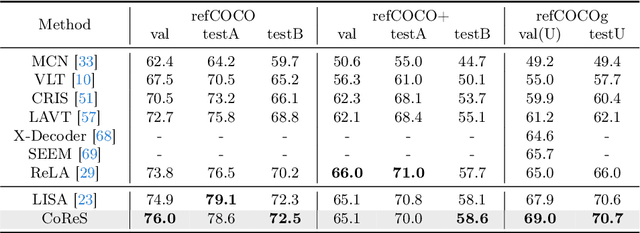
The reasoning segmentation task, which demands a nuanced comprehension of intricate queries to accurately pinpoint object regions, is attracting increasing attention. However, Multi-modal Large Language Models (MLLM) often find it difficult to accurately localize the objects described in complex reasoning contexts. We believe that the act of reasoning segmentation should mirror the cognitive stages of human visual search, where each step is a progressive refinement of thought toward the final object. Thus we introduce the Chains of Reasoning and Segmenting (CoReS) and find this top-down visual hierarchy indeed enhances the visual search process. Specifically, we propose a dual-chain structure that generates multi-modal, chain-like outputs to aid the segmentation process. Furthermore, to steer the MLLM's outputs into this intended hierarchy, we incorporate in-context inputs as guidance. Extensive experiments demonstrate the superior performance of our CoReS, which surpasses the state-of-the-art method by 7.1\% on the ReasonSeg dataset. The code will be released at https://github.com/baoxiaoyi/CoReS.
DriveDreamer-2: LLM-Enhanced World Models for Diverse Driving Video Generation
Mar 11, 2024
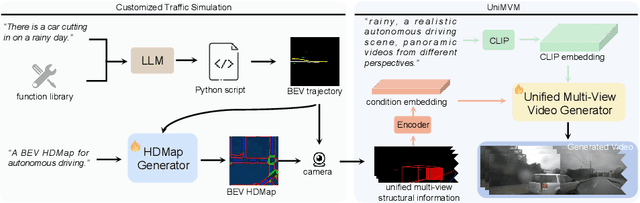


World models have demonstrated superiority in autonomous driving, particularly in the generation of multi-view driving videos. However, significant challenges still exist in generating customized driving videos. In this paper, we propose DriveDreamer-2, which builds upon the framework of DriveDreamer and incorporates a Large Language Model (LLM) to generate user-defined driving videos. Specifically, an LLM interface is initially incorporated to convert a user's query into agent trajectories. Subsequently, a HDMap, adhering to traffic regulations, is generated based on the trajectories. Ultimately, we propose the Unified Multi-View Model to enhance temporal and spatial coherence in the generated driving videos. DriveDreamer-2 is the first world model to generate customized driving videos, it can generate uncommon driving videos (e.g., vehicles abruptly cut in) in a user-friendly manner. Besides, experimental results demonstrate that the generated videos enhance the training of driving perception methods (e.g., 3D detection and tracking). Furthermore, video generation quality of DriveDreamer-2 surpasses other state-of-the-art methods, showcasing FID and FVD scores of 11.2 and 55.7, representing relative improvements of 30% and 50%.