 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Game-Theoretic Interpretation of Adversarial Robustness
Nov 08, 2021



This paper provides a unified view to explain different adversarial attacks and defense methods, \emph{i.e.} the view of multi-order interactions between input variables of DNNs. Based on the multi-order interaction, we discover that adversarial attacks mainly affect high-order interactions to fool the DNN. Furthermore, we find that the robustness of adversarially trained DNNs comes from category-specific low-order interactions. Our findings provide a potential method to unify adversarial perturbations and robustness, which can explain the existing defense methods in a principle way. Besides, our findings also make a revision of previous inaccurate understanding of the shape bias of adversarially learned features.
Game-theoretic Understanding of Adversarially Learned Features
Mar 12, 2021
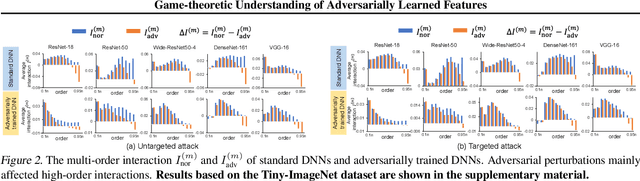

This paper aims to understand adversarial attacks and defense from a new perspecitve, i.e., the signal-processing behavior of DNNs. We novelly define the multi-order interaction in game theory, which satisfies six properties. With the multi-order interaction, we discover that adversarial attacks mainly affect high-order interactions to fool the DNN. Furthermore, we find that the robustness of adversarially trained DNNs comes from category-specific low-order interactions. Our findings provide more insights into and make a revision of previous understanding for the shape bias of adversarially learned features. Besides, the multi-order interaction can also explain the recoverability of adversarial examples.
Interpreting Multivariate Interactions in DNNs
Oct 15, 2020

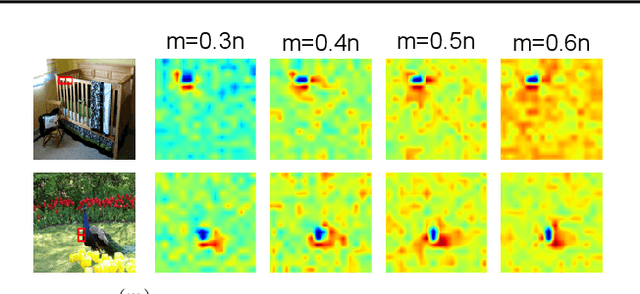
This paper aims to explain deep neural networks (DNNs) from the perspective of multivariate interactions. In this paper, we define and quantify the significance of interactions among multiple input variables of the DNN. Input variables with strong interactions usually form a coalition and reflect prototype features, which are memorized and used by the DNN for inference. We define the significance of interactions based on the Shapley value, which is designed to assign the attribution value of each input variable to the inference. We have conducted experiments with various DNNs. Experimental results have demonstrated the effectiveness of the proposed method.
Interpreting Hierarchical Linguistic Interactions in DNNs
Jun 29, 2020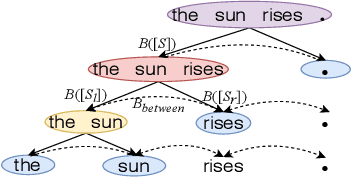
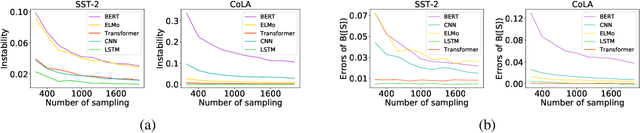

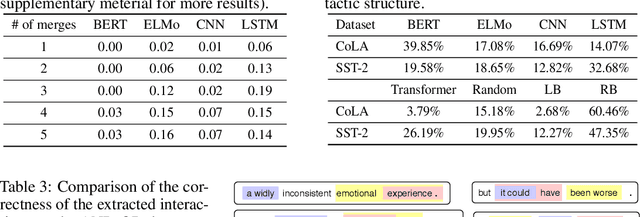
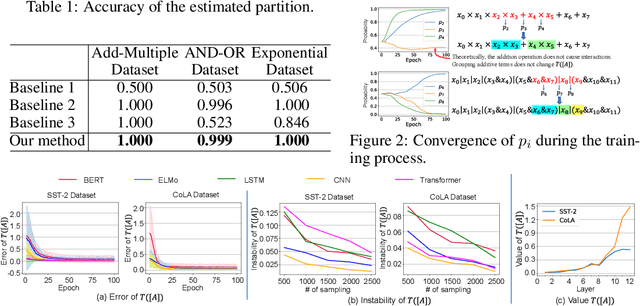
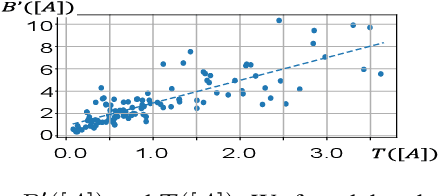
This paper proposes a method to disentangle and quantify interactions among words that are encoded inside a DNN for natural language processing. We construct a tree to encode salient interactions extracted by the DNN. Six metrics are proposed to analyze properties of interactions between constituents in a sentence. The interaction is defined based on Shapley values of words, which are considered as an unbiased estimation of word contributions to the network prediction. Our method is used to quantify word interactions encoded inside the BERT, ELMo, LSTM, CNN, and Transformer networks. Experimental results have provided a new perspective to understand these DNNs, and have demonstrated the effectiveness of our method.