 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIEG-Youpu Solution for NeurIPS 2022 WikiKG90Mv2-LSC
Mar 30, 2026WikiKG90Mv2 in NeurIPS 2022 is a large encyclopedic knowledge graph. Embedding knowledge graphs into continuous vector spaces is important for many practical applications, such as knowledge acquisition, question answering, and recommendation systems. Compared to existing knowledge graphs, WikiKG90Mv2 is a large scale knowledge graph, which is composed of more than 90 millions of entities. Both efficiency and accuracy should be considered when building graph embedding models for knowledge graph at scale. To this end, we follow the retrieve then re-rank pipeline, and make novel modifications in both retrieval and re-ranking stage. Specifically, we propose a priority infilling retrieval model to obtain candidates that are structurally and semantically similar. Then we propose an ensemble based re-ranking model with neighbor enhanced representations to produce final link prediction results among retrieved candidates. Experimental results show that our proposed method outperforms existing baseline methods and improves MRR of validation set from 0.2342 to 0.2839.
Dual-Teacher Distillation with Subnetwork Rectification for Black-Box Domain Adaptation
Mar 25, 2026Assuming that neither source data nor the source model is accessible, black box domain adaptation represents a highly practical yet extremely challenging setting, as transferable information is restricted to the predictions of the black box source model, which can only be queried using target samples. Existing approaches attempt to extract transferable knowledge through pseudo label refinement or by leveraging external vision language models (ViLs), but they often suffer from noisy supervision or insufficient utilization of the semantic priors provided by ViLs, which ultimately hinder adaptation performance. To overcome these limitations, we propose a dual teacher distillation with subnetwork rectification (DDSR) model that jointly exploits the specific knowledge embedded in black box source models and the general semantic information of a ViL. DDSR adaptively integrates their complementary predictions to generate reliable pseudo labels for the target domain and introduces a subnetwork driven regularization strategy to mitigate overfitting caused by noisy supervision. Furthermore, the refined target predictions iteratively enhance both the pseudo labels and ViL prompts, enabling more accurate and semantically consistent adaptation. Finally, the target model is further optimized through self training with classwise prototypes. Extensive experiments on multiple benchmark datasets validate the effectiveness of our approach, demonstrating consistent improvements over state of the art methods, including those using source data or models.
MVRD-Bench: Multi-View Learning and Benchmarking for Dynamic Remote Photoplethysmography under Occlusion
Mar 24, 2026Remote photoplethysmography (rPPG) is a non-contact technique that estimates physiological signals by analyzing subtle skin color changes in facial videos. Existing rPPG methods often encounter performance degradation under facial motion and occlusion scenarios due to their reliance on static and single-view facial videos. Thus, this work focuses on tackling the motion-induced occlusion problem for rPPG measurement in unconstrained multi-view facial videos. Specifically, we introduce a Multi-View rPPG Dataset (MVRD), a high-quality benchmark dataset featuring synchronized facial videos from three viewpoints under stationary, speaking, and head movement scenarios to better match real-world conditions. We also propose MVRD-rPPG, a unified multi-view rPPG learning framework that fuses complementary visual cues to maintain robust facial skin coverage, especially under motion conditions. Our method integrates an Adaptive Temporal Optical Compensation (ATOC) module for motion artifact suppression, a Rhythm-Visual Dual-Stream Network to disentangle rhythmic and appearance-related features, and a Multi-View Correlation-Aware Attention (MVCA) for adaptive view-wise signal aggregation. Furthermore, we introduce a Correlation Frequency Adversarial (CFA) learning strategy, which jointly enforces temporal accuracy, spectral consistency, and perceptual realism in the predicted signals. Extensive experiments and ablation studies on the MVRD dataset demonstrate the superiority of our approach. In the MVRD movement scenario, MVRD-rPPG achieves an MAE of 0.90 and a Pearson correlation coefficient (R) of 0.99. The source code and dataset will be made available.
Radar-APLANC: Unsupervised Radar-based Heartbeat Sensing via Augmented Pseudo-Label and Noise Contrast
Nov 11, 2025Frequency Modulated Continuous Wave (FMCW) radars can measure subtle chest wall oscillations to enable non-contact heartbeat sensing. However, traditional radar-based heartbeat sensing methods face performance degradation due to noise. Learning-based radar methods achieve better noise robustness but require costly labeled signals for supervised training. To overcome these limitations, we propose the first unsupervised framework for radar-based heartbeat sensing via Augmented Pseudo-Label and Noise Contrast (Radar-APLANC). We propose to use both the heartbeat range and noise range within the radar range matrix to construct the positive and negative samples, respectively, for improved noise robustness. Our Noise-Contrastive Triplet (NCT) loss only utilizes positive samples, negative samples, and pseudo-label signals generated by the traditional radar method, thereby avoiding dependence on expensive ground-truth physiological signals. We further design a pseudo-label augmentation approach featuring adaptive noise-aware label selection to improve pseudo-label signal quality. Extensive experiments on the Equipleth dataset and our collected radar dataset demonstrate that our unsupervised method achieves performance comparable to state-of-the-art supervised methods. Our code, dataset, and supplementary materials can be accessed from https://github.com/RadarHRSensing/Radar-APLANC.
LIDAR: Lightweight Adaptive Cue-Aware Fusion Vision Mamba for Multimodal Segmentation of Structural Cracks
Jul 30, 2025Achieving pixel-level segmentation with low computational cost using multimodal data remains a key challenge in crack segmentation tasks. Existing methods lack the capability for adaptive perception and efficient interactive fusion of cross-modal features. To address these challenges, we propose a Lightweight Adaptive Cue-Aware Vision Mamba network (LIDAR), which efficiently perceives and integrates morphological and textural cues from different modalities under multimodal crack scenarios, generating clear pixel-level crack segmentation maps. Specifically, LIDAR is composed of a Lightweight Adaptive Cue-Aware Visual State Space module (LacaVSS) and a Lightweight Dual Domain Dynamic Collaborative Fusion module (LD3CF). LacaVSS adaptively models crack cues through the proposed mask-guided Efficient Dynamic Guided Scanning Strategy (EDG-SS), while LD3CF leverages an Adaptive Frequency Domain Perceptron (AFDP) and a dual-pooling fusion strategy to effectively capture spatial and frequency-domain cues across modalities. Moreover, we design a Lightweight Dynamically Modulated Multi-Kernel convolution (LDMK) to perceive complex morphological structures with minimal computational overhead, replacing most convolutional operations in LIDAR. Experiments on three datasets demonstrate that our method outperforms other state-of-the-art (SOTA) methods. On the light-field depth dataset, our method achieves 0.8204 in F1 and 0.8465 in mIoU with only 5.35M parameters. Code and datasets are available at https://github.com/Karl1109/LIDAR-Mamba.
Dynamic Graph-Like Learning with Contrastive Clustering on Temporally-Factored Ship Motion Data for Imbalanced Sea State Estimation in Autonomous Vessel
Apr 21, 2025



Accurate sea state estimation is crucial for the real-time control and future state prediction of autonomous vessels. However, traditional methods struggle with challenges such as data imbalance and feature redundancy in ship motion data, limiting their effectiveness. To address these challenges, we propose the Temporal-Graph Contrastive Clustering Sea State Estimator (TGC-SSE), a novel deep learning model that combines three key components: a time dimension factorization module to reduce data redundancy, a dynamic graph-like learning module to capture complex variable interactions, and a contrastive clustering loss function to effectively manage class imbalance. Our experiments demonstrate that TGC-SSE significantly outperforms existing methods across 14 public datasets, achieving the highest accuracy in 9 datasets, with a 20.79% improvement over EDI. Furthermore, in the field of sea state estimation, TGC-SSE surpasses five benchmark methods and seven deep learning models. Ablation studies confirm the effectiveness of each module, demonstrating their respective roles in enhancing overall model performance. Overall, TGC-SSE not only improves the accuracy of sea state estimation but also exhibits strong generalization capabilities, providing reliable support for autonomous vessel operations.
From Laboratory to Real World: A New Benchmark Towards Privacy-Preserved Visible-Infrared Person Re-Identification
Mar 15, 2025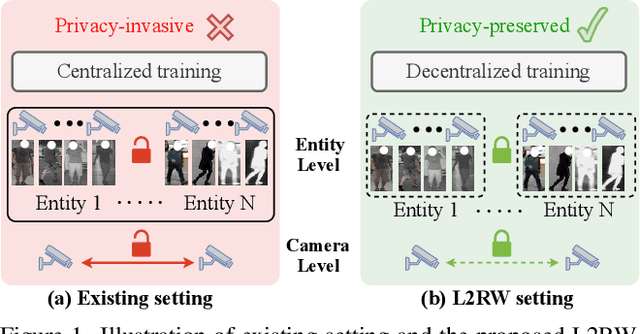
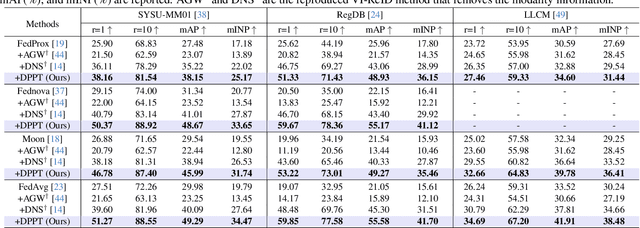
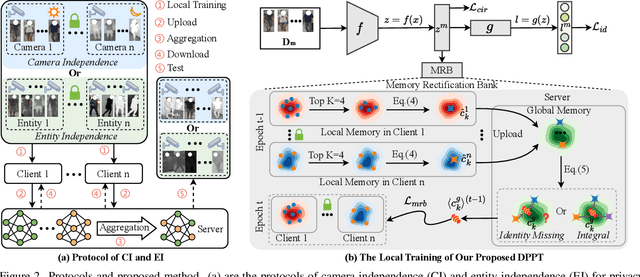
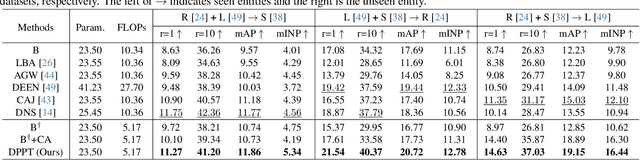
Aiming to match pedestrian images captured under varying lighting conditions, visible-infrared person re-identification (VI-ReID) has drawn intensive research attention and achieved promising results. However, in real-world surveillance contexts, data is distributed across multiple devices/entities, raising privacy and ownership concerns that make existing centralized training impractical for VI-ReID. To tackle these challenges, we propose L2RW, a benchmark that brings VI-ReID closer to real-world applications. The rationale of L2RW is that integrating decentralized training into VI-ReID can address privacy concerns in scenarios with limited data-sharing regulation. Specifically, we design protocols and corresponding algorithms for different privacy sensitivity levels. In our new benchmark, we ensure the model training is done in the conditions that: 1) data from each camera remains completely isolated, or 2) different data entities (e.g., data controllers of a certain region) can selectively share the data. In this way, we simulate scenarios with strict privacy constraints which is closer to real-world conditions. Intensive experiments with various server-side federated algorithms are conducted, showing the feasibility of decentralized VI-ReID training. Notably, when evaluated in unseen domains (i.e., new data entities), our L2RW, trained with isolated data (privacy-preserved), achieves performance comparable to SOTAs trained with shared data (privacy-unrestricted). We hope this work offers a novel research entry for deploying VI-ReID that fits real-world scenarios and can benefit the community.
Prototype-based Heterogeneous Federated Learning for Blade Icing Detection in Wind Turbines with Class Imbalanced Data
Mar 11, 2025Wind farms, typically in high-latitude regions, face a high risk of blade icing. Traditional centralized training methods raise serious privacy concerns. To enhance data privacy in detecting wind turbine blade icing, traditional federated learning (FL) is employed. However, data heterogeneity, resulting from collections across wind farms in varying environmental conditions, impacts the model's optimization capabilities. Moreover, imbalances in wind turbine data lead to models that tend to favor recognizing majority classes, thus neglecting critical icing anomalies. To tackle these challenges, we propose a federated prototype learning model for class-imbalanced data in heterogeneous environments to detect wind turbine blade icing. We also propose a contrastive supervised loss function to address the class imbalance problem. Experiments on real data from 20 turbines across two wind farms show our method outperforms five FL models and five class imbalance methods, with an average improvement of 19.64\% in \( mF_{\beta} \) and 5.73\% in \( m \)BA compared to the second-best method, BiFL.
SCSegamba: Lightweight Structure-Aware Vision Mamba for Crack Segmentation in Structures
Mar 03, 2025Pixel-level segmentation of structural cracks across various scenarios remains a considerable challenge. Current methods encounter challenges in effectively modeling crack morphology and texture, facing challenges in balancing segmentation quality with low computational resource usage. To overcome these limitations, we propose a lightweight Structure-Aware Vision Mamba Network (SCSegamba), capable of generating high-quality pixel-level segmentation maps by leveraging both the morphological information and texture cues of crack pixels with minimal computational cost. Specifically, we developed a Structure-Aware Visual State Space module (SAVSS), which incorporates a lightweight Gated Bottleneck Convolution (GBC) and a Structure-Aware Scanning Strategy (SASS). The key insight of GBC lies in its effectiveness in modeling the morphological information of cracks, while the SASS enhances the perception of crack topology and texture by strengthening the continuity of semantic information between crack pixels. Experiments on crack benchmark datasets demonstrate that our method outperforms other state-of-the-art (SOTA) methods, achieving the highest performance with only 2.8M parameters. On the multi-scenario dataset, our method reached 0.8390 in F1 score and 0.8479 in mIoU. The code is available at https://github.com/Karl1109/SCSegamba.
Can Students Beyond The Teacher? Distilling Knowledge from Teacher's Bias
Dec 13, 2024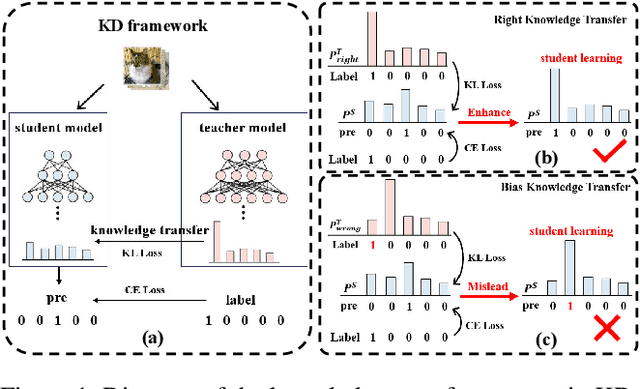
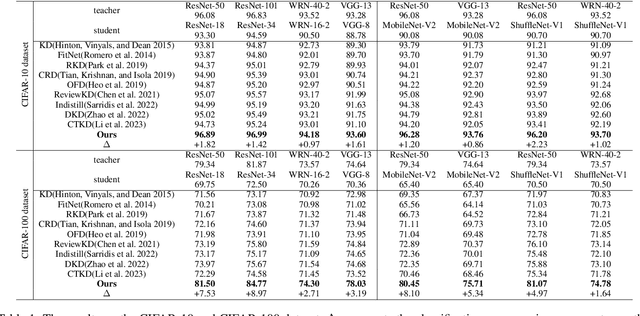
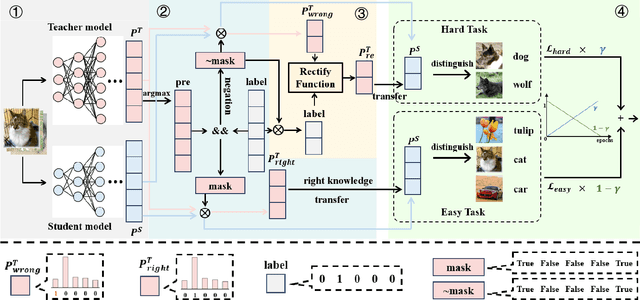
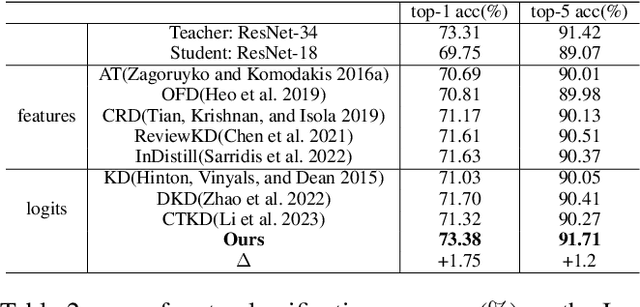
Knowledge distillation (KD) is a model compression technique that transfers knowledge from a large teacher model to a smaller student model to enhance its performance. Existing methods often assume that the student model is inherently inferior to the teacher model. However, we identify that the fundamental issue affecting student performance is the bias transferred by the teacher. Current KD frameworks transmit both right and wrong knowledge, introducing bias that misleads the student model. To address this issue, we propose a novel strategy to rectify bias and greatly improve the student model's performance. Our strategy involves three steps: First, we differentiate knowledge and design a bias elimination method to filter out biases, retaining only the right knowledge for the student model to learn. Next, we propose a bias rectification method to rectify the teacher model's wrong predictions, fundamentally addressing bias interference. The student model learns from both the right knowledge and the rectified biases, greatly improving its prediction accuracy. Additionally, we introduce a dynamic learning approach with a loss function that updates weights dynamically, allowing the student model to quickly learn right knowledge-based easy tasks initially and tackle hard tasks corresponding to biases later, greatly enhancing the student model's learning efficiency. To the best of our knowledge, this is the first strategy enabling the student model to surpass the teacher model. Experiments demonstrate that our strategy, as a plug-and-play module, is versatile across various mainstream KD frameworks. We will release our code after the paper is accepted.