 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnification of Closed-Open Industrial Detection Scenarios: New Large-Scale Benchmarks,Challenges and Baselines
Jun 06, 2026Large-scale Visual-Language Models (LVLMs) have achieved remarkable success in natural visual tasks, yet their application to industrial defect detection remains challenging due to two fundamental limitations: (i) the scarcity of large-scale industrial datasets that cover diverse defect categories across multiple domains, and (ii) the reliance on manual prompts (points, boxes, masks) that introduce subjective noise and lack text-visual interaction for fine-grained understanding. To address these challenges, we introduce a Large-Scale Multi-Modal Industrial Open-Closed benchmark (MMIOC-1M) containing over one million samples across $14$ super-categories, $29$ industrial scenes, and $351$ defect subcategories. To our knowledge, MMIOC-1M is the first unified largest benchmark supporting both open-vocabulary and closed-set industrial detection, providing valuable pre-training data for LVLMs in industrial scenarios. Furthermore, we propose a Refined Text-Visual Prompt Network (RTVPNet) that incorporates three key innovations: (1) an expert-assisted domain projection mechanism that enables rapid adaptation of general vision models to industrial domains, (2) an energy-based sparse sampling strategy that automatically generates refined visual prompts without manual intervention, and (3) a bidirectional text-visual interaction module that enhances cross-modal semantic alignment and understanding. Extensive experiments demonstrate that RTVPNet achieves state-of-the-art performance on MMIOC-1M, LVIS, and COCO benchmarks while maintaining computational efficiency. The dataset and code are available at https://github.com/hellozzk/MMIO.
SCRWKV: Ultra-Compact Structure-Calibrated Vision-RWKV for Topological Crack Segmentation
May 14, 2026Achieving pixel-level accurate segmentation of structural cracks across diverse scenarios remains a formidable challenge. Existing methods face significant bottlenecks in balancing crack topology modeling with computational efficiency, often failing to reconcile high segmentation quality with low resource demands. To address these limitations, we propose the Ultra-Compact Structure-Calibrated Vision RWKV (SCRWKV), a network that achieves high-precision modeling via a novel Structure-Field Encoder (SFE) backbone while maintaining linear complexity. The SFE integrates the Adaptive Multi-scale Cascaded Modulator (AMCM) to enhance texture representation and utilizes the Structure-Calibrated Insight Unit (SCIU) as its core engine. Specifically, the SCIU employs the Geometry-guided Bidirectional Structure Transformation (GBST) to capture topological correlations and integrates the Dynamic Self-Calibrating Decay (DSCD) into Dy-WKV to suppress noise propagation. Furthermore, we introduce a lightweight Cross-Scale Harmonic Fusion (CSHF) decoder to achieve precise feature aggregation. Systematic evaluations on multiple benchmarks characterized by complex textures and severe interference demonstrate that SCRWKV, with only 1.22M parameters, significantly outperforms SOTA methods. Achieving an F1 score of 0.8428 and mIoU of 0.8512 on the TUT dataset, the model confirms its robust potential for efficient real-world deployment. The code is available at https://github.com/zhxhzy/SCRWKV.
Dual-Teacher Distillation with Subnetwork Rectification for Black-Box Domain Adaptation
Mar 25, 2026Assuming that neither source data nor the source model is accessible, black box domain adaptation represents a highly practical yet extremely challenging setting, as transferable information is restricted to the predictions of the black box source model, which can only be queried using target samples. Existing approaches attempt to extract transferable knowledge through pseudo label refinement or by leveraging external vision language models (ViLs), but they often suffer from noisy supervision or insufficient utilization of the semantic priors provided by ViLs, which ultimately hinder adaptation performance. To overcome these limitations, we propose a dual teacher distillation with subnetwork rectification (DDSR) model that jointly exploits the specific knowledge embedded in black box source models and the general semantic information of a ViL. DDSR adaptively integrates their complementary predictions to generate reliable pseudo labels for the target domain and introduces a subnetwork driven regularization strategy to mitigate overfitting caused by noisy supervision. Furthermore, the refined target predictions iteratively enhance both the pseudo labels and ViL prompts, enabling more accurate and semantically consistent adaptation. Finally, the target model is further optimized through self training with classwise prototypes. Extensive experiments on multiple benchmark datasets validate the effectiveness of our approach, demonstrating consistent improvements over state of the art methods, including those using source data or models.
LIDAR: Lightweight Adaptive Cue-Aware Fusion Vision Mamba for Multimodal Segmentation of Structural Cracks
Jul 30, 2025Achieving pixel-level segmentation with low computational cost using multimodal data remains a key challenge in crack segmentation tasks. Existing methods lack the capability for adaptive perception and efficient interactive fusion of cross-modal features. To address these challenges, we propose a Lightweight Adaptive Cue-Aware Vision Mamba network (LIDAR), which efficiently perceives and integrates morphological and textural cues from different modalities under multimodal crack scenarios, generating clear pixel-level crack segmentation maps. Specifically, LIDAR is composed of a Lightweight Adaptive Cue-Aware Visual State Space module (LacaVSS) and a Lightweight Dual Domain Dynamic Collaborative Fusion module (LD3CF). LacaVSS adaptively models crack cues through the proposed mask-guided Efficient Dynamic Guided Scanning Strategy (EDG-SS), while LD3CF leverages an Adaptive Frequency Domain Perceptron (AFDP) and a dual-pooling fusion strategy to effectively capture spatial and frequency-domain cues across modalities. Moreover, we design a Lightweight Dynamically Modulated Multi-Kernel convolution (LDMK) to perceive complex morphological structures with minimal computational overhead, replacing most convolutional operations in LIDAR. Experiments on three datasets demonstrate that our method outperforms other state-of-the-art (SOTA) methods. On the light-field depth dataset, our method achieves 0.8204 in F1 and 0.8465 in mIoU with only 5.35M parameters. Code and datasets are available at https://github.com/Karl1109/LIDAR-Mamba.
Dynamic Graph-Like Learning with Contrastive Clustering on Temporally-Factored Ship Motion Data for Imbalanced Sea State Estimation in Autonomous Vessel
Apr 21, 2025



Accurate sea state estimation is crucial for the real-time control and future state prediction of autonomous vessels. However, traditional methods struggle with challenges such as data imbalance and feature redundancy in ship motion data, limiting their effectiveness. To address these challenges, we propose the Temporal-Graph Contrastive Clustering Sea State Estimator (TGC-SSE), a novel deep learning model that combines three key components: a time dimension factorization module to reduce data redundancy, a dynamic graph-like learning module to capture complex variable interactions, and a contrastive clustering loss function to effectively manage class imbalance. Our experiments demonstrate that TGC-SSE significantly outperforms existing methods across 14 public datasets, achieving the highest accuracy in 9 datasets, with a 20.79% improvement over EDI. Furthermore, in the field of sea state estimation, TGC-SSE surpasses five benchmark methods and seven deep learning models. Ablation studies confirm the effectiveness of each module, demonstrating their respective roles in enhancing overall model performance. Overall, TGC-SSE not only improves the accuracy of sea state estimation but also exhibits strong generalization capabilities, providing reliable support for autonomous vessel operations.
Prototype-based Heterogeneous Federated Learning for Blade Icing Detection in Wind Turbines with Class Imbalanced Data
Mar 11, 2025Wind farms, typically in high-latitude regions, face a high risk of blade icing. Traditional centralized training methods raise serious privacy concerns. To enhance data privacy in detecting wind turbine blade icing, traditional federated learning (FL) is employed. However, data heterogeneity, resulting from collections across wind farms in varying environmental conditions, impacts the model's optimization capabilities. Moreover, imbalances in wind turbine data lead to models that tend to favor recognizing majority classes, thus neglecting critical icing anomalies. To tackle these challenges, we propose a federated prototype learning model for class-imbalanced data in heterogeneous environments to detect wind turbine blade icing. We also propose a contrastive supervised loss function to address the class imbalance problem. Experiments on real data from 20 turbines across two wind farms show our method outperforms five FL models and five class imbalance methods, with an average improvement of 19.64\% in \( mF_{\beta} \) and 5.73\% in \( m \)BA compared to the second-best method, BiFL.
SCSegamba: Lightweight Structure-Aware Vision Mamba for Crack Segmentation in Structures
Mar 03, 2025Pixel-level segmentation of structural cracks across various scenarios remains a considerable challenge. Current methods encounter challenges in effectively modeling crack morphology and texture, facing challenges in balancing segmentation quality with low computational resource usage. To overcome these limitations, we propose a lightweight Structure-Aware Vision Mamba Network (SCSegamba), capable of generating high-quality pixel-level segmentation maps by leveraging both the morphological information and texture cues of crack pixels with minimal computational cost. Specifically, we developed a Structure-Aware Visual State Space module (SAVSS), which incorporates a lightweight Gated Bottleneck Convolution (GBC) and a Structure-Aware Scanning Strategy (SASS). The key insight of GBC lies in its effectiveness in modeling the morphological information of cracks, while the SASS enhances the perception of crack topology and texture by strengthening the continuity of semantic information between crack pixels. Experiments on crack benchmark datasets demonstrate that our method outperforms other state-of-the-art (SOTA) methods, achieving the highest performance with only 2.8M parameters. On the multi-scenario dataset, our method reached 0.8390 in F1 score and 0.8479 in mIoU. The code is available at https://github.com/Karl1109/SCSegamba.
Can Students Beyond The Teacher? Distilling Knowledge from Teacher's Bias
Dec 13, 2024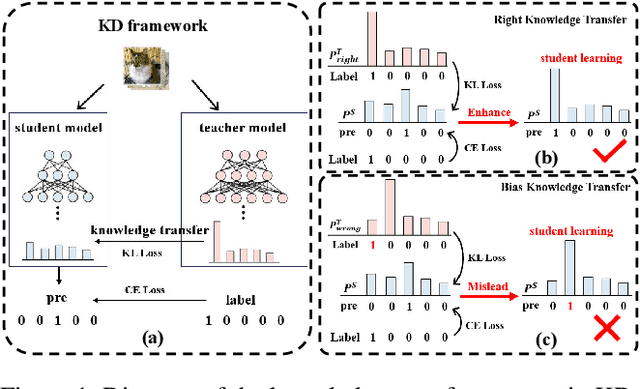
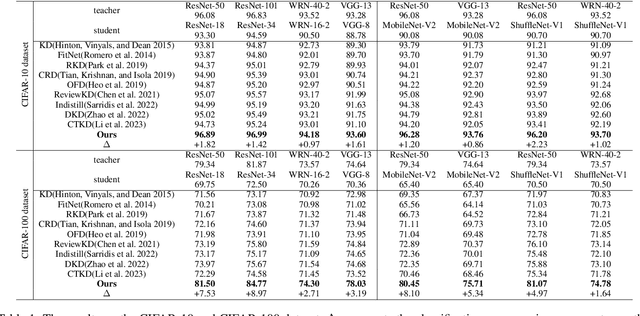
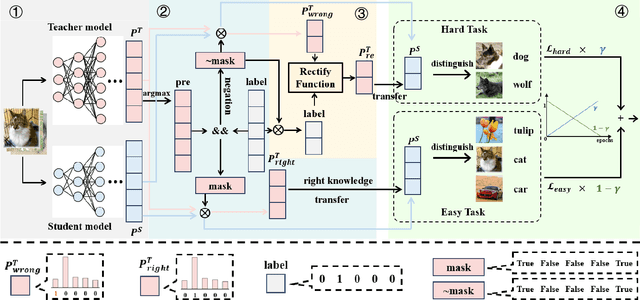
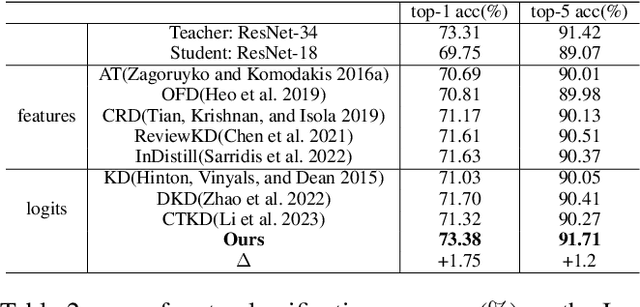
Knowledge distillation (KD) is a model compression technique that transfers knowledge from a large teacher model to a smaller student model to enhance its performance. Existing methods often assume that the student model is inherently inferior to the teacher model. However, we identify that the fundamental issue affecting student performance is the bias transferred by the teacher. Current KD frameworks transmit both right and wrong knowledge, introducing bias that misleads the student model. To address this issue, we propose a novel strategy to rectify bias and greatly improve the student model's performance. Our strategy involves three steps: First, we differentiate knowledge and design a bias elimination method to filter out biases, retaining only the right knowledge for the student model to learn. Next, we propose a bias rectification method to rectify the teacher model's wrong predictions, fundamentally addressing bias interference. The student model learns from both the right knowledge and the rectified biases, greatly improving its prediction accuracy. Additionally, we introduce a dynamic learning approach with a loss function that updates weights dynamically, allowing the student model to quickly learn right knowledge-based easy tasks initially and tackle hard tasks corresponding to biases later, greatly enhancing the student model's learning efficiency. To the best of our knowledge, this is the first strategy enabling the student model to surpass the teacher model. Experiments demonstrate that our strategy, as a plug-and-play module, is versatile across various mainstream KD frameworks. We will release our code after the paper is accepted.
MFCLIP: Multi-modal Fine-grained CLIP for Generalizable Diffusion Face Forgery Detection
Sep 15, 2024The rapid development of photo-realistic face generation methods has raised significant concerns in society and academia, highlighting the urgent need for robust and generalizable face forgery detection (FFD) techniques. Although existing approaches mainly capture face forgery patterns using image modality, other modalities like fine-grained noises and texts are not fully explored, which limits the generalization capability of the model. In addition, most FFD methods tend to identify facial images generated by GAN, but struggle to detect unseen diffusion-synthesized ones. To address the limitations, we aim to leverage the cutting-edge foundation model, contrastive language-image pre-training (CLIP), to achieve generalizable diffusion face forgery detection (DFFD). In this paper, we propose a novel multi-modal fine-grained CLIP (MFCLIP) model, which mines comprehensive and fine-grained forgery traces across image-noise modalities via language-guided face forgery representation learning, to facilitate the advancement of DFFD. Specifically, we devise a fine-grained language encoder (FLE) that extracts fine global language features from hierarchical text prompts. We design a multi-modal vision encoder (MVE) to capture global image forgery embeddings as well as fine-grained noise forgery patterns extracted from the richest patch, and integrate them to mine general visual forgery traces. Moreover, we build an innovative plug-and-play sample pair attention (SPA) method to emphasize relevant negative pairs and suppress irrelevant ones, allowing cross-modality sample pairs to conduct more flexible alignment. Extensive experiments and visualizations show that our model outperforms the state of the arts on different settings like cross-generator, cross-forgery, and cross-dataset evaluations.
Staircase Cascaded Fusion of Lightweight Local Pattern Recognition and Long-Range Dependencies for Structural Crack Segmentation
Aug 23, 2024



Detecting cracks with pixel-level precision for key structures is a significant challenge, as existing methods struggle to effectively integrate local textures and pixel dependencies of cracks. Furthermore, these methods often possess numerous parameters and substantial computational requirements, complicating deployment on edge devices. In this paper, we propose a staircase cascaded fusion crack segmentation network (CrackSCF) that generates high-quality crack segmentation maps using minimal computational resources. We constructed a staircase cascaded fusion module that effectively captures local patterns of cracks and long-range dependencies of pixels, and it can suppress background noise well. To reduce the computational resources required by the model, we introduced a lightweight convolution block, which replaces all convolution operations in the network, significantly reducing the required computation and parameters without affecting the network's performance. To evaluate our method, we created a challenging benchmark dataset called TUT and conducted experiments on this dataset and five other public datasets. The experimental results indicate that our method offers significant advantages over existing methods, especially in handling background noise interference and detailed crack segmentation. The F1 and mIoU scores on the TUT dataset are 0.8382 and 0.8473, respectively, achieving state-of-the-art (SOTA) performance while requiring the least computational resources. The code and dataset is available at https://github.com/Karl1109/CrackSCF.