 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGazeCLIP: Gaze-Guided CLIP with Adaptive-Enhanced Fine-Grained Language Prompt for Deepfake Attribution and Detection
Mar 31, 2026Current deepfake attribution or deepfake detection works tend to exhibit poor generalization to novel generative methods due to the limited exploration in visual modalities alone. They tend to assess the attribution or detection performance of models on unseen advanced generators, coarsely, and fail to consider the synergy of the two tasks. To this end, we propose a novel gaze-guided CLIP with adaptive-enhanced fine-grained language prompts for fine-grained deepfake attribution and detection (DFAD). Specifically, we conduct a novel and fine-grained benchmark to evaluate the DFAD performance of networks on novel generators like diffusion and flow models. Additionally, we introduce a gaze-aware model based on CLIP, which is devised to enhance the generalization to unseen face forgery attacks. Built upon the novel observation that there are significant distribution differences between pristine and forged gaze vectors, and the preservation of the target gaze in facial images generated by GAN and diffusion varies significantly, we design a visual perception encoder to employ the inherent gaze differences to mine global forgery embeddings across appearance and gaze domains. We propose a gaze-aware image encoder (GIE) that fuses forgery gaze prompts extracted via a gaze encoder with common forged image embeddings to capture general attribution patterns, allowing features to be transformed into a more stable and common DFAD feature space. We build a language refinement encoder (LRE) to generate dynamically enhanced language embeddings via an adaptive-enhanced word selector for precise vision-language matching. Extensive experiments on our benchmark show that our model outperforms the state-of-the-art by 6.56% ACC and 5.32% AUC in average performance under the attribution and detection settings, respectively. Codes will be available on GitHub.
BMRL: Bi-Modal Guided Multi-Perspective Representation Learning for Zero-Shot Deepfake Attribution
Apr 19, 2025The challenge of tracing the source attribution of forged faces has gained significant attention due to the rapid advancement of generative models. However, existing deepfake attribution (DFA) works primarily focus on the interaction among various domains in vision modality, and other modalities such as texts and face parsing are not fully explored. Besides, they tend to fail to assess the generalization performance of deepfake attributors to unseen generators in a fine-grained manner. In this paper, we propose a novel bi-modal guided multi-perspective representation learning (BMRL) framework for zero-shot deepfake attribution (ZS-DFA), which facilitates effective traceability to unseen generators. Specifically, we design a multi-perspective visual encoder (MPVE) to explore general deepfake attribution visual characteristics across three views (i.e., image, noise, and edge). We devise a novel parsing encoder to focus on global face attribute embeddings, enabling parsing-guided DFA representation learning via vision-parsing matching. A language encoder is proposed to capture fine-grained language embeddings, facilitating language-guided general visual forgery representation learning through vision-language alignment. Additionally, we present a novel deepfake attribution contrastive center (DFACC) loss, to pull relevant generators closer and push irrelevant ones away, which can be introduced into DFA models to enhance traceability. Experimental results demonstrate that our method outperforms the state-of-the-art on the ZS-DFA task through various protocols evaluation.
Multiple Information Prompt Learning for Cloth-Changing Person Re-Identification
Nov 01, 2024
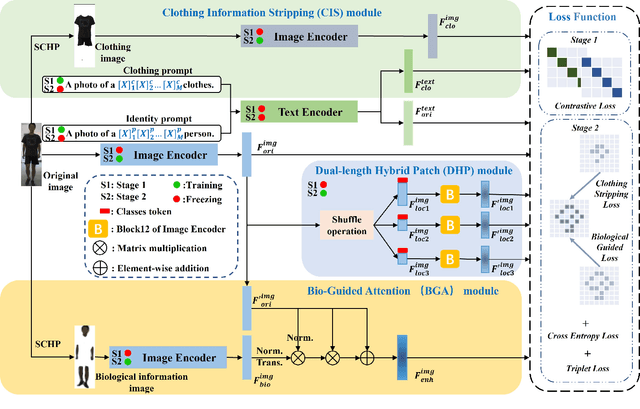


Cloth-changing person re-identification is a subject closer to the real world, which focuses on solving the problem of person re-identification after pedestrians change clothes. The primary challenge in this field is to overcome the complex interplay between intra-class and inter-class variations and to identify features that remain unaffected by changes in appearance. Sufficient data collection for model training would significantly aid in addressing this problem. However, it is challenging to gather diverse datasets in practice. Current methods focus on implicitly learning identity information from the original image or introducing additional auxiliary models, which are largely limited by the quality of the image and the performance of the additional model. To address these issues, inspired by prompt learning, we propose a novel multiple information prompt learning (MIPL) scheme for cloth-changing person ReID, which learns identity robust features through the common prompt guidance of multiple messages. Specifically, the clothing information stripping (CIS) module is designed to decouple the clothing information from the original RGB image features to counteract the influence of clothing appearance. The Bio-guided attention (BGA) module is proposed to increase the learning intensity of the model for key information. A dual-length hybrid patch (DHP) module is employed to make the features have diverse coverage to minimize the impact of feature bias. Extensive experiments demonstrate that the proposed method outperforms all state-of-the-art methods on the LTCC, Celeb-reID, Celeb-reID-light, and CSCC datasets, achieving rank-1 scores of 74.8%, 73.3%, 66.0%, and 88.1%, respectively. When compared to AIM (CVPR23), ACID (TIP23), and SCNet (MM23), MIPL achieves rank-1 improvements of 11.3%, 13.8%, and 7.9%, respectively, on the PRCC dataset.
MFCLIP: Multi-modal Fine-grained CLIP for Generalizable Diffusion Face Forgery Detection
Sep 15, 2024The rapid development of photo-realistic face generation methods has raised significant concerns in society and academia, highlighting the urgent need for robust and generalizable face forgery detection (FFD) techniques. Although existing approaches mainly capture face forgery patterns using image modality, other modalities like fine-grained noises and texts are not fully explored, which limits the generalization capability of the model. In addition, most FFD methods tend to identify facial images generated by GAN, but struggle to detect unseen diffusion-synthesized ones. To address the limitations, we aim to leverage the cutting-edge foundation model, contrastive language-image pre-training (CLIP), to achieve generalizable diffusion face forgery detection (DFFD). In this paper, we propose a novel multi-modal fine-grained CLIP (MFCLIP) model, which mines comprehensive and fine-grained forgery traces across image-noise modalities via language-guided face forgery representation learning, to facilitate the advancement of DFFD. Specifically, we devise a fine-grained language encoder (FLE) that extracts fine global language features from hierarchical text prompts. We design a multi-modal vision encoder (MVE) to capture global image forgery embeddings as well as fine-grained noise forgery patterns extracted from the richest patch, and integrate them to mine general visual forgery traces. Moreover, we build an innovative plug-and-play sample pair attention (SPA) method to emphasize relevant negative pairs and suppress irrelevant ones, allowing cross-modality sample pairs to conduct more flexible alignment. Extensive experiments and visualizations show that our model outperforms the state of the arts on different settings like cross-generator, cross-forgery, and cross-dataset evaluations.
Continual Learning with Strong Experience Replay
May 23, 2023



Continual Learning (CL) aims at incrementally learning new tasks without forgetting the knowledge acquired from old ones. Experience Replay (ER) is a simple and effective rehearsal-based strategy, which optimizes the model with current training data and a subset of old samples stored in a memory buffer. To further reduce forgetting, recent approaches extend ER with various techniques, such as model regularization and memory sampling. However, the prediction consistency between the new model and the old one on current training data has been seldom explored, resulting in less knowledge preserved when few previous samples are available. To address this issue, we propose a CL method with Strong Experience Replay (SER), which additionally utilizes future experiences mimicked on the current training data, besides distilling past experience from the memory buffer. In our method, the updated model will produce approximate outputs as its original ones, which can effectively preserve the acquired knowledge. Experimental results on multiple image classification datasets show that our SER method surpasses the state-of-the-art methods by a noticeable margin.
Identity-Guided Collaborative Learning for Cloth-Changing Person Reidentification
Apr 10, 2023



Cloth-changing person reidentification (ReID) is a newly emerging research topic that is aimed at addressing the issues of large feature variations due to cloth-changing and pedestrian view/pose changes. Although significant progress has been achieved by introducing extra information (e.g., human contour sketching information, human body keypoints, and 3D human information), cloth-changing person ReID is still challenging due to impressionable pedestrian representations. Moreover, human semantic information and pedestrian identity information are not fully explored. To solve these issues, we propose a novel identity-guided collaborative learning scheme (IGCL) for cloth-changing person ReID, where the human semantic is fully utilized and the identity is unchangeable to guide collaborative learning. First, we design a novel clothing attention degradation stream to reasonably reduce the interference caused by clothing information where clothing attention and mid-level collaborative learning are employed. Second, we propose a human semantic attention and body jigsaw stream to highlight the human semantic information and simulate different poses of the same identity. In this way, the extraction features not only focus on human semantic information that is unrelated to the background but also are suitable for pedestrian pose variations. Moreover, a pedestrian identity enhancement stream is further proposed to enhance the identity importance and extract more favorable identity robust features. Most importantly, all these streams are jointly explored in an end-to-end unified framework, and the identity is utilized to guide the optimization. Extensive experiments on five public clothing person ReID datasets demonstrate that the proposed IGCL significantly outperforms SOTA methods and that the extracted feature is more robust, discriminative, and clothing-irrelevant.
Multi-Behavior Recommendation with Cascading Graph Convolution Networks
Mar 28, 2023



Multi-behavior recommendation, which exploits auxiliary behaviors (e.g., click and cart) to help predict users' potential interactions on the target behavior (e.g., buy), is regarded as an effective way to alleviate the data sparsity or cold-start issues in recommendation. Multi-behaviors are often taken in certain orders in real-world applications (e.g., click>cart>buy). In a behavior chain, a latter behavior usually exhibits a stronger signal of user preference than the former one does. Most existing multi-behavior models fail to capture such dependencies in a behavior chain for embedding learning. In this work, we propose a novel multi-behavior recommendation model with cascading graph convolution networks (named MB-CGCN). In MB-CGCN, the embeddings learned from one behavior are used as the input features for the next behavior's embedding learning after a feature transformation operation. In this way, our model explicitly utilizes the behavior dependencies in embedding learning. Experiments on two benchmark datasets demonstrate the effectiveness of our model on exploiting multi-behavior data. It outperforms the best baseline by 33.7% and 35.9% on average over the two datasets in terms of Recall@10 and NDCG@10, respectively.
Temporal Action Localization with Multi-temporal Scales
Aug 16, 2022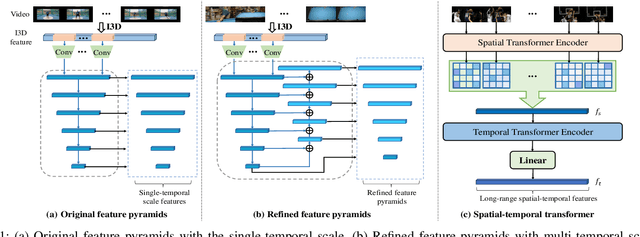
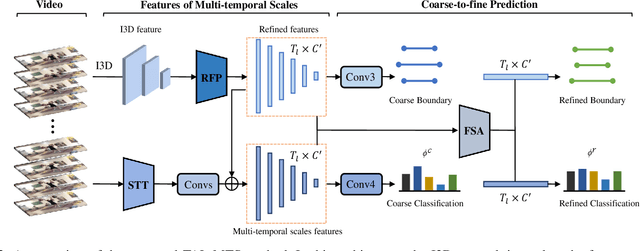
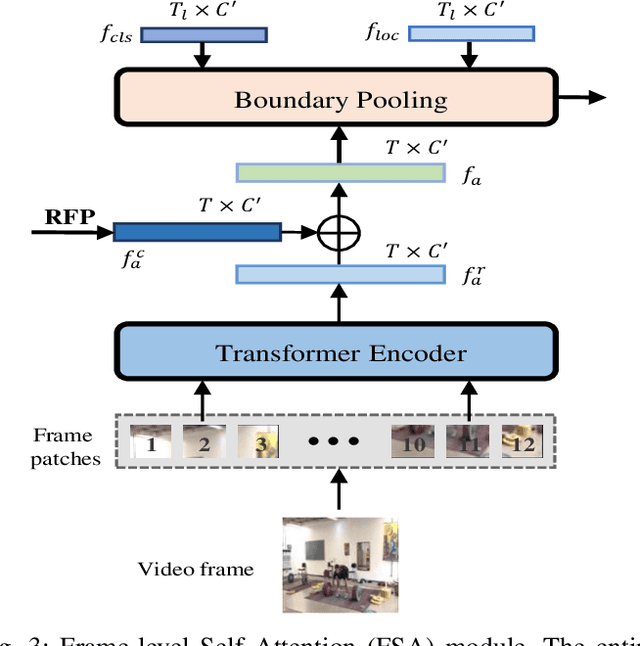
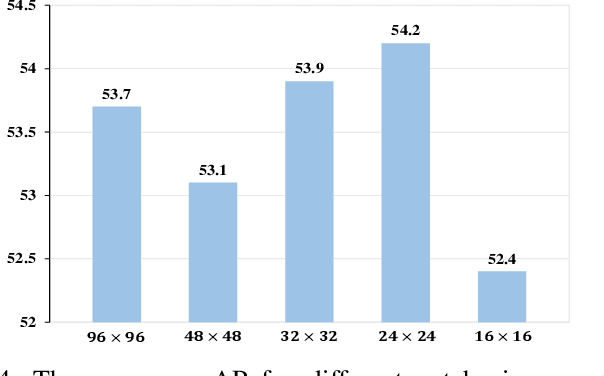
Temporal action localization plays an important role in video analysis, which aims to localize and classify actions in untrimmed videos. The previous methods often predict actions on a feature space of a single-temporal scale. However, the temporal features of a low-level scale lack enough semantics for action classification while a high-level scale cannot provide rich details of the action boundaries. To address this issue, we propose to predict actions on a feature space of multi-temporal scales. Specifically, we use refined feature pyramids of different scales to pass semantics from high-level scales to low-level scales. Besides, to establish the long temporal scale of the entire video, we use a spatial-temporal transformer encoder to capture the long-range dependencies of video frames. Then the refined features with long-range dependencies are fed into a classifier for the coarse action prediction. Finally, to further improve the prediction accuracy, we propose to use a frame-level self attention module to refine the classification and boundaries of each action instance. Extensive experiments show that the proposed method can outperform state-of-the-art approaches on the THUMOS14 dataset and achieves comparable performance on the ActivityNet1.3 dataset. Compared with A2Net (TIP20, Avg\{0.3:0.7\}), Sub-Action (CSVT2022, Avg\{0.1:0.5\}), and AFSD (CVPR21, Avg\{0.3:0.7\}) on the THUMOS14 dataset, the proposed method can achieve improvements of 12.6\%, 17.4\% and 2.2\%, respectively
A Semantic-aware Attention and Visual Shielding Network for Cloth-changing Person Re-identification
Jul 18, 2022

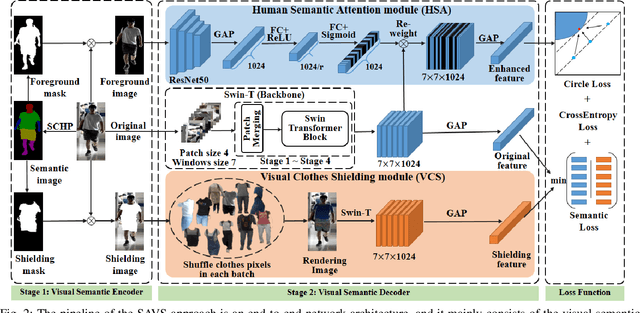

Cloth-changing person reidentification (ReID) is a newly emerging research topic that aims to retrieve pedestrians whose clothes are changed. Since the human appearance with different clothes exhibits large variations, it is very difficult for existing approaches to extract discriminative and robust feature representations. Current works mainly focus on body shape or contour sketches, but the human semantic information and the potential consistency of pedestrian features before and after changing clothes are not fully explored or are ignored. To solve these issues, in this work, a novel semantic-aware attention and visual shielding network for cloth-changing person ReID (abbreviated as SAVS) is proposed where the key idea is to shield clues related to the appearance of clothes and only focus on visual semantic information that is not sensitive to view/posture changes. Specifically, a visual semantic encoder is first employed to locate the human body and clothing regions based on human semantic segmentation information. Then, a human semantic attention module (HSA) is proposed to highlight the human semantic information and reweight the visual feature map. In addition, a visual clothes shielding module (VCS) is also designed to extract a more robust feature representation for the cloth-changing task by covering the clothing regions and focusing the model on the visual semantic information unrelated to the clothes. Most importantly, these two modules are jointly explored in an end-to-end unified framework. Extensive experiments demonstrate that the proposed method can significantly outperform state-of-the-art methods, and more robust features can be extracted for cloth-changing persons. Compared with FSAM (published in CVPR 2021), this method can achieve improvements of 32.7% (16.5%) and 14.9% (-) on the LTCC and PRCC datasets in terms of mAP (rank-1), respectively.
Disentangled Graph Neural Networks for Session-based Recommendation
Jan 11, 2022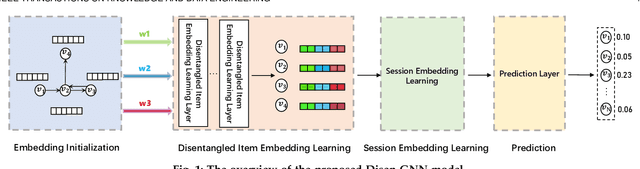
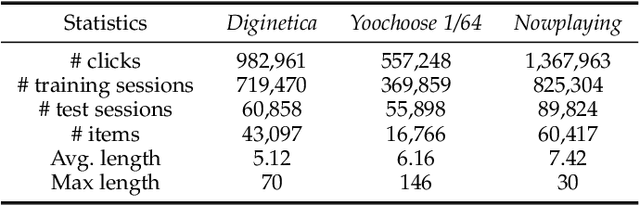


Session-based recommendation (SBR) has drawn increasingly research attention in recent years, due to its great practical value by only exploiting the limited user behavior history in the current session. Existing methods typically learn the session embedding at the item level, namely, aggregating the embeddings of items with or without the attention weights assigned to items. However, they ignore the fact that a user's intent on adopting an item is driven by certain factors of the item (e.g., the leading actors of an movie). In other words, they have not explored finer-granularity interests of users at the factor level to generate the session embedding, leading to sub-optimal performance. To address the problem, we propose a novel method called Disentangled Graph Neural Network (Disen-GNN) to capture the session purpose with the consideration of factor-level attention on each item. Specifically, we first employ the disentangled learning technique to cast item embeddings into the embedding of multiple factors, and then use the gated graph neural network (GGNN) to learn the embedding factor-wisely based on the item adjacent similarity matrix computed for each factor. Moreover, the distance correlation is adopted to enhance the independence between each pair of factors. After representing each item with independent factors, an attention mechanism is designed to learn user intent to different factors of each item in the session. The session embedding is then generated by aggregating the item embeddings with attention weights of each item's factors. To this end, our model takes user intents at the factor level into account to infer the user purpose in a session. Extensive experiments on three benchmark datasets demonstrate the superiority of our method over existing methods.