 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Action Localization with Multi-temporal Scales
Paper and Code
Aug 16, 2022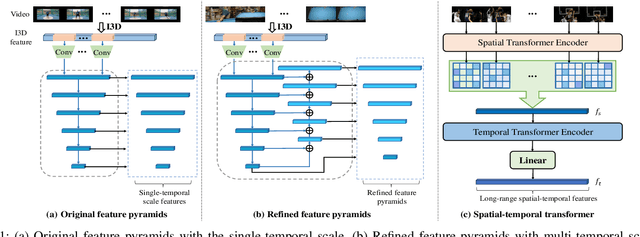
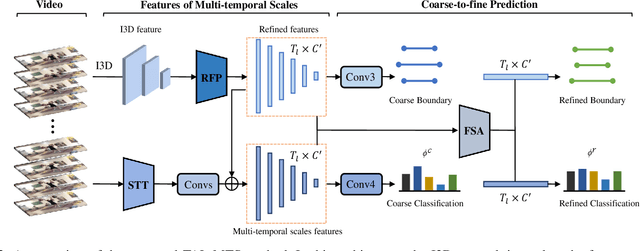
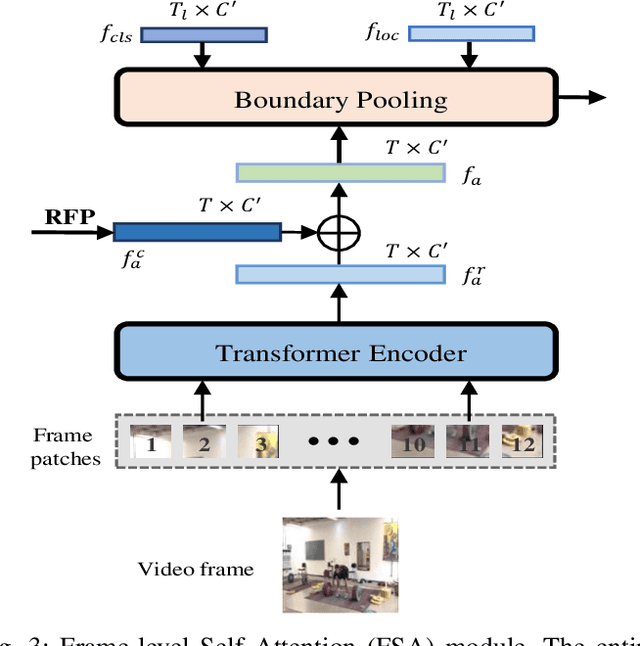
Temporal action localization plays an important role in video analysis, which aims to localize and classify actions in untrimmed videos. The previous methods often predict actions on a feature space of a single-temporal scale. However, the temporal features of a low-level scale lack enough semantics for action classification while a high-level scale cannot provide rich details of the action boundaries. To address this issue, we propose to predict actions on a feature space of multi-temporal scales. Specifically, we use refined feature pyramids of different scales to pass semantics from high-level scales to low-level scales. Besides, to establish the long temporal scale of the entire video, we use a spatial-temporal transformer encoder to capture the long-range dependencies of video frames. Then the refined features with long-range dependencies are fed into a classifier for the coarse action prediction. Finally, to further improve the prediction accuracy, we propose to use a frame-level self attention module to refine the classification and boundaries of each action instance. Extensive experiments show that the proposed method can outperform state-of-the-art approaches on the THUMOS14 dataset and achieves comparable performance on the ActivityNet1.3 dataset. Compared with A2Net (TIP20, Avg\{0.3:0.7\}), Sub-Action (CSVT2022, Avg\{0.1:0.5\}), and AFSD (CVPR21, Avg\{0.3:0.7\}) on the THUMOS14 dataset, the proposed method can achieve improvements of 12.6\%, 17.4\% and 2.2\%, respectively