 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity-Guided Collaborative Learning for Cloth-Changing Person Reidentification
Apr 10, 2023



Cloth-changing person reidentification (ReID) is a newly emerging research topic that is aimed at addressing the issues of large feature variations due to cloth-changing and pedestrian view/pose changes. Although significant progress has been achieved by introducing extra information (e.g., human contour sketching information, human body keypoints, and 3D human information), cloth-changing person ReID is still challenging due to impressionable pedestrian representations. Moreover, human semantic information and pedestrian identity information are not fully explored. To solve these issues, we propose a novel identity-guided collaborative learning scheme (IGCL) for cloth-changing person ReID, where the human semantic is fully utilized and the identity is unchangeable to guide collaborative learning. First, we design a novel clothing attention degradation stream to reasonably reduce the interference caused by clothing information where clothing attention and mid-level collaborative learning are employed. Second, we propose a human semantic attention and body jigsaw stream to highlight the human semantic information and simulate different poses of the same identity. In this way, the extraction features not only focus on human semantic information that is unrelated to the background but also are suitable for pedestrian pose variations. Moreover, a pedestrian identity enhancement stream is further proposed to enhance the identity importance and extract more favorable identity robust features. Most importantly, all these streams are jointly explored in an end-to-end unified framework, and the identity is utilized to guide the optimization. Extensive experiments on five public clothing person ReID datasets demonstrate that the proposed IGCL significantly outperforms SOTA methods and that the extracted feature is more robust, discriminative, and clothing-irrelevant.
Temporal Action Localization with Multi-temporal Scales
Aug 16, 2022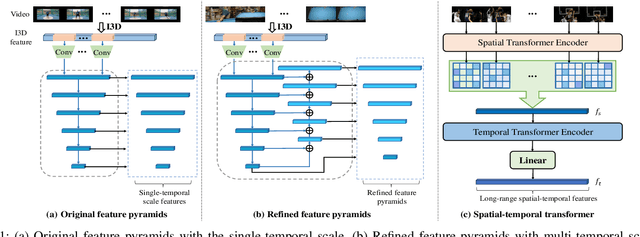
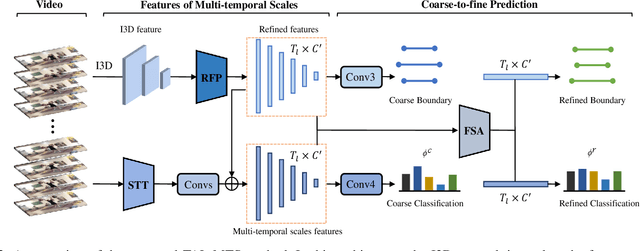
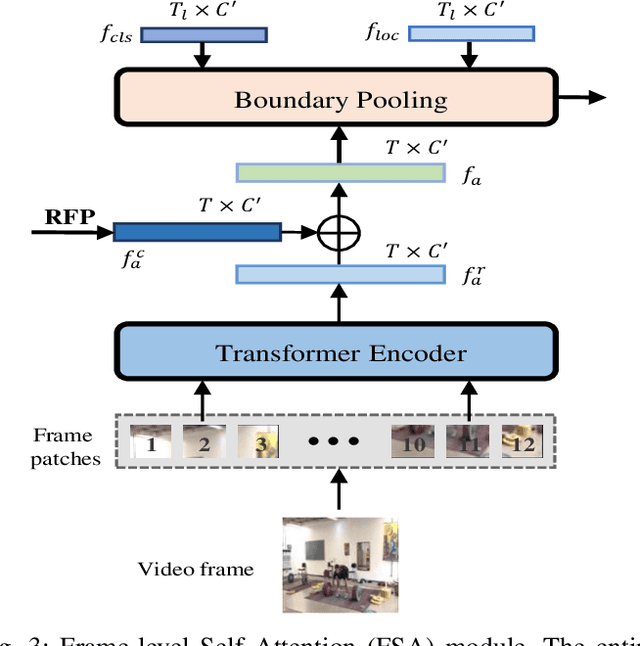
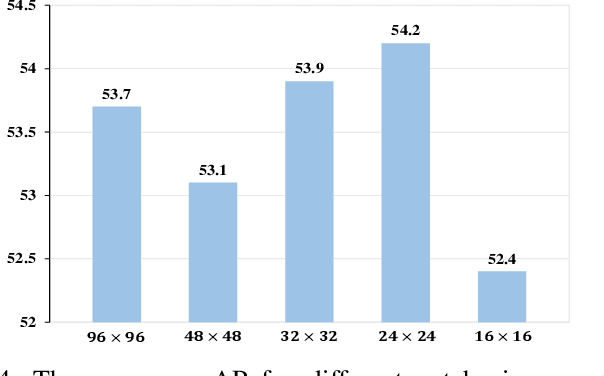
Temporal action localization plays an important role in video analysis, which aims to localize and classify actions in untrimmed videos. The previous methods often predict actions on a feature space of a single-temporal scale. However, the temporal features of a low-level scale lack enough semantics for action classification while a high-level scale cannot provide rich details of the action boundaries. To address this issue, we propose to predict actions on a feature space of multi-temporal scales. Specifically, we use refined feature pyramids of different scales to pass semantics from high-level scales to low-level scales. Besides, to establish the long temporal scale of the entire video, we use a spatial-temporal transformer encoder to capture the long-range dependencies of video frames. Then the refined features with long-range dependencies are fed into a classifier for the coarse action prediction. Finally, to further improve the prediction accuracy, we propose to use a frame-level self attention module to refine the classification and boundaries of each action instance. Extensive experiments show that the proposed method can outperform state-of-the-art approaches on the THUMOS14 dataset and achieves comparable performance on the ActivityNet1.3 dataset. Compared with A2Net (TIP20, Avg\{0.3:0.7\}), Sub-Action (CSVT2022, Avg\{0.1:0.5\}), and AFSD (CVPR21, Avg\{0.3:0.7\}) on the THUMOS14 dataset, the proposed method can achieve improvements of 12.6\%, 17.4\% and 2.2\%, respectively
A Semantic-aware Attention and Visual Shielding Network for Cloth-changing Person Re-identification
Jul 18, 2022

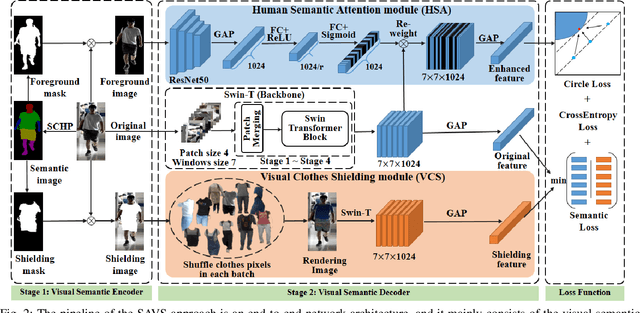

Cloth-changing person reidentification (ReID) is a newly emerging research topic that aims to retrieve pedestrians whose clothes are changed. Since the human appearance with different clothes exhibits large variations, it is very difficult for existing approaches to extract discriminative and robust feature representations. Current works mainly focus on body shape or contour sketches, but the human semantic information and the potential consistency of pedestrian features before and after changing clothes are not fully explored or are ignored. To solve these issues, in this work, a novel semantic-aware attention and visual shielding network for cloth-changing person ReID (abbreviated as SAVS) is proposed where the key idea is to shield clues related to the appearance of clothes and only focus on visual semantic information that is not sensitive to view/posture changes. Specifically, a visual semantic encoder is first employed to locate the human body and clothing regions based on human semantic segmentation information. Then, a human semantic attention module (HSA) is proposed to highlight the human semantic information and reweight the visual feature map. In addition, a visual clothes shielding module (VCS) is also designed to extract a more robust feature representation for the cloth-changing task by covering the clothing regions and focusing the model on the visual semantic information unrelated to the clothes. Most importantly, these two modules are jointly explored in an end-to-end unified framework. Extensive experiments demonstrate that the proposed method can significantly outperform state-of-the-art methods, and more robust features can be extracted for cloth-changing persons. Compared with FSAM (published in CVPR 2021), this method can achieve improvements of 32.7% (16.5%) and 14.9% (-) on the LTCC and PRCC datasets in terms of mAP (rank-1), respectively.