 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo All Individual Layers Help? An Empirical Study of Task-Interfering Layers in Vision-Language Models
Feb 01, 2026Current VLMs have demonstrated capabilities across a wide range of multimodal tasks. Typically, in a pretrained VLM, all layers are engaged by default to make predictions on downstream tasks. We find that intervening on a single layer, such as by zeroing its parameters, can improve the performance on certain tasks, indicating that some layers hinder rather than help downstream tasks. We systematically investigate how individual layers influence different tasks via layer intervention. Specifically, we measure the change in performance relative to the base model after intervening on each layer and observe improvements when bypassing specific layers. This improvement can be generalizable across models and datasets, indicating the presence of Task-Interfering Layers that harm downstream tasks' performance. We introduce Task-Layer Interaction Vector, which quantifies the effect of intervening on each layer of a VLM given a task. These task-interfering layers exhibit task-specific sensitivity patterns: tasks requiring similar capabilities show consistent response trends under layer interventions, as evidenced by the high similarity in their task-layer interaction vectors. Inspired by these findings, we propose TaLo (Task-Adaptive Layer Knockout), a training-free, test-time adaptation method that dynamically identifies and bypasses the most interfering layer for a given task. Without parameter updates, TaLo improves performance across various models and datasets, including boosting Qwen-VL's accuracy on the Maps task in ScienceQA by up to 16.6%. Our work reveals an unexpected form of modularity in pretrained VLMs and provides a plug-and-play, training-free mechanism to unlock hidden capabilities at inference time. The source code will be publicly available.
ConLA: Contrastive Latent Action Learning from Human Videos for Robotic Manipulation
Jan 31, 2026Vision-Language-Action (VLA) models achieve preliminary generalization through pretraining on large scale robot teleoperation datasets. However, acquiring datasets that comprehensively cover diverse tasks and environments is extremely costly and difficult to scale. In contrast, human demonstration videos offer a rich and scalable source of diverse scenes and manipulation behaviors, yet their lack of explicit action supervision hinders direct utilization. Prior work leverages VQ-VAE based frameworks to learn latent actions from human videos in an unsupervised manner. Nevertheless, since the training objective primarily focuses on reconstructing visual appearances rather than capturing inter-frame dynamics, the learned representations tend to rely on spurious visual cues, leading to shortcut learning and entangled latent representations that hinder transferability. To address this, we propose ConLA, an unsupervised pretraining framework for learning robotic policies from human videos. ConLA introduces a contrastive disentanglement mechanism that leverages action category priors and temporal cues to isolate motion dynamics from visual content, effectively mitigating shortcut learning. Extensive experiments show that ConLA achieves strong performance across diverse benchmarks. Notably, by pretraining solely on human videos, our method for the first time surpasses the performance obtained with real robot trajectory pretraining, highlighting its ability to extract pure and semantically consistent latent action representations for scalable robot learning.
CVeDRL: An Efficient Code Verifier via Difficulty-aware Reinforcement Learning
Jan 30, 2026Code verifiers play a critical role in post-verification for LLM-based code generation, yet existing supervised fine-tuning methods suffer from data scarcity, high failure rates, and poor inference efficiency. While reinforcement learning (RL) offers a promising alternative by optimizing models through execution-driven rewards without labeled supervision, our preliminary results show that naive RL with only functionality rewards fails to generate effective unit tests for difficult branches and samples. We first theoretically analyze showing that branch coverage, sample difficulty, syntactic and functional correctness can be jointly modeled as RL rewards, where optimizing these signals can improve the reliability of unit-test-based verification. Guided by this analysis, we design syntax- and functionality-aware rewards and further propose branch- and sample-difficulty--aware RL using exponential reward shaping and static analysis metrics. With this formulation, CVeDRL achieves state-of-the-art performance with only 0.6B parameters, yielding up to 28.97% higher pass rate and 15.08% higher branch coverage than GPT-3.5, while delivering over $20\times$ faster inference than competitive baselines. Code is available at https://github.com/LIGHTCHASER1/CVeDRL.git
StructAlign: Structured Cross-Modal Alignment for Continual Text-to-Video Retrieval
Jan 28, 2026Continual Text-to-Video Retrieval (CTVR) is a challenging multimodal continual learning setting, where models must incrementally learn new semantic categories while maintaining accurate text-video alignment for previously learned ones, thus making it particularly prone to catastrophic forgetting. A key challenge in CTVR is feature drift, which manifests in two forms: intra-modal feature drift caused by continual learning within each modality, and non-cooperative feature drift across modalities that leads to modality misalignment. To mitigate these issues, we propose StructAlign, a structured cross-modal alignment method for CTVR. First, StructAlign introduces a simplex Equiangular Tight Frame (ETF) geometry as a unified geometric prior to mitigate modality misalignment. Building upon this geometric prior, we design a cross-modal ETF alignment loss that aligns text and video features with category-level ETF prototypes, encouraging the learned representations to form an approximate simplex ETF geometry. In addition, to suppress intra-modal feature drift, we design a Cross-modal Relation Preserving loss, which leverages complementary modalities to preserve cross-modal similarity relations, providing stable relational supervision for feature updates. By jointly addressing non-cooperative feature drift across modalities and intra-modal feature drift, StructAlign effectively alleviates catastrophic forgetting in CTVR. Extensive experiments on benchmark datasets demonstrate that our method consistently outperforms state-of-the-art continual retrieval approaches.
IOTA: Corrective Knowledge-Guided Prompt Learning via Black-White Box Framework
Jan 28, 2026Recently, adapting pre-trained models to downstream tasks has attracted increasing interest. Previous Parameter-Efficient-Tuning (PET) methods regard the pre-trained model as an opaque Black Box model, relying purely on data-driven optimization and underutilizing their inherent prior knowledge. This oversight limits the models' potential for effective downstream task adaptation. To address these issues, we propose a novel black-whIte bOx prompT leArning framework (IOTA), which integrates a data-driven Black Box module with a knowledge-driven White Box module for downstream task adaptation. Specifically, the White Box module derives corrective knowledge by contrasting the wrong predictions with the right cognition. This knowledge is verbalized into interpretable human prompts and leveraged through a corrective knowledge-guided prompt selection strategy to guide the Black Box module toward more accurate predictions. By jointly leveraging knowledge- and data-driven learning signals, IOTA achieves effective downstream task adaptation. Experimental results on 12 image classification benchmarks under few-shot and easy-to-hard adaptation settings demonstrate the effectiveness of corrective knowledge and the superiority of our method over state-of-the-art methods.
PersonalAlign: Hierarchical Implicit Intent Alignment for Personalized GUI Agent with Long-Term User-Centric Records
Jan 14, 2026While GUI agents have shown strong performance under explicit and completion instructions, real-world deployment requires aligning with users' more complex implicit intents. In this work, we highlight Hierarchical Implicit Intent Alignment for Personalized GUI Agent (PersonalAlign), a new agent task that requires agents to leverage long-term user records as persistent context to resolve omitted preferences in vague instructions and anticipate latent routines by user state for proactive assistance. To facilitate this study, we introduce AndroidIntent, a benchmark designed to evaluate agents' ability in resolving vague instructions and providing proactive suggestions through reasoning over long-term user records. We annotated 775 user-specific preferences and 215 routines from 20k long-term records across different users for evaluation. Furthermore, we introduce Hierarchical Intent Memory Agent (HIM-Agent), which maintains a continuously updating personal memory and hierarchically organizes user preferences and routines for personalization. Finally, we evaluate a range of GUI agents on AndroidIntent, including GPT-5, Qwen3-VL, and UI-TARS, further results show that HIM-Agent significantly improves both execution and proactive performance by 15.7% and 7.3%.
From Bias to Balance: Exploring and Mitigating Spatial Bias in LVLMs
Sep 26, 2025
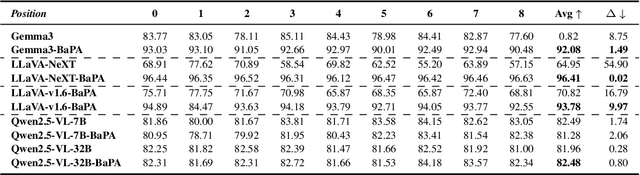
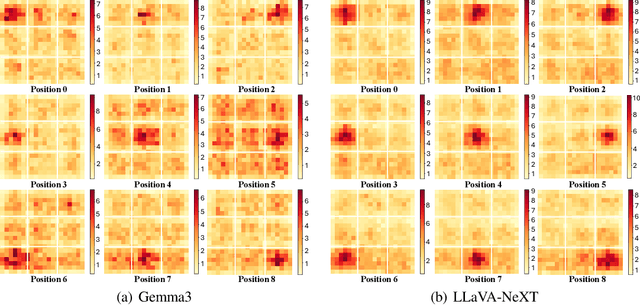
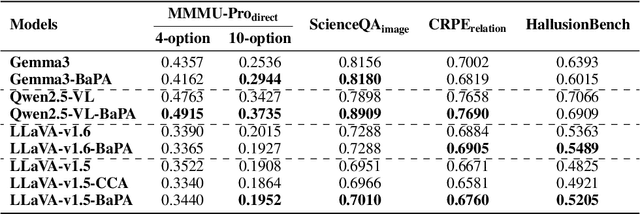
Large Vision-Language Models (LVLMs) have achieved remarkable success across a wide range of multimodal tasks, yet their robustness to spatial variations remains insufficiently understood. In this work, we present a systematic study of the spatial bias of LVLMs, focusing on how models respond when identical key visual information is placed at different locations within an image. Through a carefully designed probing dataset, we demonstrate that current LVLMs often produce inconsistent outputs under such spatial shifts, revealing a fundamental limitation in their spatial-semantic understanding. Further analysis shows that this phenomenon originates not from the vision encoder, which reliably perceives and interprets visual content across positions, but from the unbalanced design of position embeddings in the language model component. In particular, the widely adopted position embedding strategies, such as RoPE, introduce imbalance during cross-modal interaction, leading image tokens at different positions to exert unequal influence on semantic understanding. To mitigate this issue, we introduce Balanced Position Assignment (BaPA), a simple yet effective mechanism that assigns identical position embeddings to all image tokens, promoting a more balanced integration of visual information. Extensive experiments show that BaPA enhances the spatial robustness of LVLMs without retraining and further boosts their performance across diverse multimodal benchmarks when combined with lightweight fine-tuning. Further analysis of information flow reveals that BaPA yields balanced attention, enabling more holistic visual understanding.
Dual Knowledge-Enhanced Two-Stage Reasoner for Multimodal Dialog Systems
Sep 09, 2025


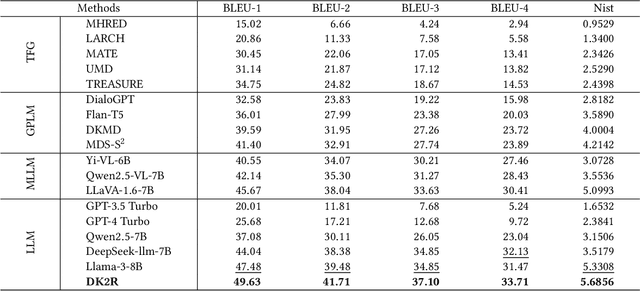
Textual response generation is pivotal for multimodal \mbox{task-oriented} dialog systems, which aims to generate proper textual responses based on the multimodal context. While existing efforts have demonstrated remarkable progress, there still exist the following limitations: 1) \textit{neglect of unstructured review knowledge} and 2) \textit{underutilization of large language models (LLMs)}. Inspired by this, we aim to fully utilize dual knowledge (\textit{i.e., } structured attribute and unstructured review knowledge) with LLMs to promote textual response generation in multimodal task-oriented dialog systems. However, this task is non-trivial due to two key challenges: 1) \textit{dynamic knowledge type selection} and 2) \textit{intention-response decoupling}. To address these challenges, we propose a novel dual knowledge-enhanced two-stage reasoner by adapting LLMs for multimodal dialog systems (named DK2R). To be specific, DK2R first extracts both structured attribute and unstructured review knowledge from external knowledge base given the dialog context. Thereafter, DK2R uses an LLM to evaluate each knowledge type's utility by analyzing LLM-generated provisional probe responses. Moreover, DK2R separately summarizes the intention-oriented key clues via dedicated reasoning, which are further used as auxiliary signals to enhance LLM-based textual response generation. Extensive experiments conducted on a public dataset verify the superiority of DK2R. We have released the codes and parameters.
Optimus-3: Towards Generalist Multimodal Minecraft Agents with Scalable Task Experts
Jun 12, 2025



Recently, agents based on multimodal large language models (MLLMs) have achieved remarkable progress across various domains. However, building a generalist agent with capabilities such as perception, planning, action, grounding, and reflection in open-world environments like Minecraft remains challenges: insufficient domain-specific data, interference among heterogeneous tasks, and visual diversity in open-world settings. In this paper, we address these challenges through three key contributions. 1) We propose a knowledge-enhanced data generation pipeline to provide scalable and high-quality training data for agent development. 2) To mitigate interference among heterogeneous tasks, we introduce a Mixture-of-Experts (MoE) architecture with task-level routing. 3) We develop a Multimodal Reasoning-Augmented Reinforcement Learning approach to enhance the agent's reasoning ability for visual diversity in Minecraft. Built upon these innovations, we present Optimus-3, a general-purpose agent for Minecraft. Extensive experimental results demonstrate that Optimus-3 surpasses both generalist multimodal large language models and existing state-of-the-art agents across a wide range of tasks in the Minecraft environment. Project page: https://cybertronagent.github.io/Optimus-3.github.io/
SplitLoRA: Balancing Stability and Plasticity in Continual Learning Through Gradient Space Splitting
May 29, 2025Continual Learning requires a model to learn multiple tasks in sequence while maintaining both stability:preserving knowledge from previously learned tasks, and plasticity:effectively learning new tasks. Gradient projection has emerged as an effective and popular paradigm in CL, where it partitions the gradient space of previously learned tasks into two orthogonal subspaces: a primary subspace and a minor subspace. New tasks are learned effectively within the minor subspace, thereby reducing interference with previously acquired knowledge. However, existing Gradient Projection methods struggle to achieve an optimal balance between plasticity and stability, as it is hard to appropriately partition the gradient space. In this work, we consider a continual learning paradigm based on Low-Rank Adaptation, which has gained considerable attention due to its efficiency and wide applicability, and propose a novel approach for continual learning, called SplitLoRA. We first provide a theoretical analysis of how subspace partitioning affects model stability and plasticity. Informed by this analysis, we then introduce an effective method that derives the optimal partition of the gradient space for previously learned tasks. This approach effectively balances stability and plasticity in continual learning. Experimental results on multiple datasets demonstrate that the proposed method achieves state-of-the-art performance.