 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Point-to-Mask Optimization with Reinforced Point Selection for Crowd Instance Segmentation
Apr 02, 2026Crowd instance segmentation is a crucial task with a wide range of applications, including surveillance and transportation. Currently, point labels are common in crowd datasets, while region labels (e.g., boxes) are rare and inaccurate. The masks obtained through segmentation help to improve the accuracy of region labels and resolve the correspondence between individual location coordinates and crowd density maps. However, directly applying currently popular large foundation models such as SAM does not yield ideal results in dense crowds. To this end, we first propose Dense Point-to-Mask Optimization (DPMO), which integrates SAM with the Nearest Neighbor Exclusive Circle (NNEC) constraint to generate dense instance segmentation from point annotations. With DPMO and manual correction, we obtain mask annotations from the existing point annotations for traditional crowd datasets. Then, to predict instance segmentation in dense crowds, we propose a Reinforced Point Selection (RPS) framework trained with Group Relative Policy Optimization (GRPO), which selects the best predicted point from a sampling of the initial point prediction. Through extensive experiments, we achieve state-of-the-art crowd instance segmentation performance on ShanghaiTech, UCF-QNRF, JHU-CROWD++, and NWPU-Crowd datasets. Furthermore, we design new loss functions supervised by masks that boost counting performance across different models, demonstrating the significant role of mask annotations in enhancing counting accuracy.
FocusVLA: Focused Visual Utilization for Vision-Language-Action Models
Mar 30, 2026Vision-Language-Action (VLA) models improve action generation by conditioning policies on rich vision-language information. However, current auto-regressive policies are constrained by three bottlenecks: (1) architectural bias drives models to overlook visual details, (2) an excessive number of visual tokens makes attention difficult to focus on the correct regions, and (3) task-irrelevant visual information introduces substantial noise - together severely impairing the quality of action. In this paper, we investigate how to effectively utilize different visual representations for action generation. To this end, we first empirically validate the above issues and show that VLA performance is primarily limited by how visual information is utilized, rather than by the quality of visual representations. Based on these insights, we introduce FocusVLA, a novel paradigm that directs the model's attention to task-relevant visual regions to effectively bridge vision to action. Specifically, we first propose Modality Cascaded Attention to eliminate shortcut pathways, thereby compelling VLA models to rely on task-relevant visual details for action generation. Furthermore, we propose Focus Attention, which dynamically selects task-relevant visual patches to control information quantity while explicitly modulating their influence to suppress task-irrelevant noise. Extensive experiments on both simulated and real-world robotic benchmarks demonstrate that FocusVLA not only effectively leverages visual details to perform dexterous manipulations, but also substantially improves performance and accelerates convergence across a variety of tasks.
M2P: Improving Visual Foundation Models with Mask-to-Point Weakly-Supervised Learning for Dense Point Tracking
Mar 18, 2026Tracking Any Point (TAP) has emerged as a fundamental tool for video understanding. Current approaches adapt Vision Foundation Models (VFMs) like DINOv2 via offline finetuning or test-time optimization. However, these VFMs rely on static image pre-training, which is inherently sub-optimal for capturing dense temporal correspondence in videos. To address this, we propose Mask-to-Point (M2P) learning, which leverages rich video object segmentation (VOS) mask annotations to improve VFMs for dense point tracking. Our M2P introduces three new mask-based constraints for weakly-supervised representation learning. First, we propose a local structure consistency loss, which leverages Procrustes analysis to model the cohesive motion of points lying within a local structure, achieving more reliable point-to-point matching learning. Second, we propose a mask label consistency (MLC) loss, which enforces that sampled foreground points strictly match foreground regions across frames. The proposed MLC loss can be regarded as a regularization, which stabilizes training and prevents convergence to trivial solutions. Finally, mask boundary constrain is applied to explicitly supervise boundary points. We show that our weaklysupervised M2P models significantly outperform baseline VFMs with efficient training by using only 3.6K VOS training videos. Notably, M2P achieves 12.8% and 14.6% performance gains over DINOv2-B/14 and DINOv3-B/16 on the TAP-Vid-DAVIS benchmark, respectively. Moreover, the proposed M2P models are used as pre-trained backbones for both test-time optimized and offline fine-tuned TAP tasks, demonstrating its potential to serve as general pre-trained models for point tracking. Code will be made publicly available upon acceptance.
Exclusivity-Guided Mask Learning for Semi-Supervised Crowd Instance Segmentation and Counting
Mar 17, 2026Semi-supervised crowd analysis is a prominent area of research, as unlabeled data are typically abundant and inexpensive to obtain. However, traditional point-based annotations constrain performance because individual regions are inherently ambiguous, and consequently, learning fine-grained structural semantics from sparse anno tations remains an unresolved challenge. In this paper, we first propose an Exclusion-Constrained Dual-Prompt SAM (EDP-SAM), based on our Nearest Neighbor Exclusion Circle (NNEC) constraint, to generate mask supervision for current datasets. With the aim of segmenting individuals in dense scenes, we then propose Exclusivity-Guided Mask Learning (XMask), which enforces spatial separation through a discriminative mask objective. Gaussian smoothing and a differentiable center sampling strategy are utilized to improve feature continuity and training stability. Building on XMask, we present a semi-supervised crowd counting framework that uses instance mask priors as pseudo-labels, which contain richer shape information than traditional point cues. Extensive experiments on the ShanghaiTech A, UCF-QNRF, and JHU++ datasets (using 5%, 10%, and 40% labeled data) verify that our end-to-end model achieves state-of-the-art semi-supervised segmentation and counting performance, effectively bridging the gap between counting and instance segmentation within a unified framework.
UNICBench: UNIfied Counting Benchmark for MLLM
Feb 28, 2026Counting is a core capability for multimodal large language models (MLLMs), yet there is no unified counting dataset to rigorously evaluate this ability across image, text, and audio. We present UNICBench, a unified multimodal, multi level counting benchmark and evaluation toolkit with accurate ground truth, deterministic numeric parsing, and stratified reporting. The corpus comprises 5,300 images (5,508 QA), 872 documents (5,888 QA), and 2,069 audio clips (2,905 QA), annotated with a three level capability taxonomy and difficulty tags. Under a standardized protocol with fixed splits/prompts/seeds and modality specific matching rules, we evaluate 45 state-of-the-art MLLMs across modalities. Results show strong performance on some basic counting tasks but significant gaps on reasoning and the hardest partitions, highlighting long-tail errors and substantial headroom for improving general counting. UNICBench offers a rigorous and comparable basis for measurement and a public toolkit to accelerate progress.
Video Individual Counting and Tracking from Moving Drones: A Benchmark and Methods
Jan 18, 2026Counting and tracking dense crowds in large-scale scenes is highly challenging, yet existing methods mainly rely on datasets captured by fixed cameras, which provide limited spatial coverage and are inadequate for large-scale dense crowd analysis. To address this limitation, we propose a flexible solution using moving drones to capture videos and perform video-level crowd counting and tracking of unique pedestrians across entire scenes. We introduce MovingDroneCrowd++, the largest video-level dataset for dense crowd counting and tracking captured by moving drones, covering diverse and complex conditions with varying flight altitudes, camera angles, and illumination. Existing methods fail to achieve satisfactory performance on this dataset. To this end, we propose GD3A (Global Density Map Decomposition via Descriptor Association), a density map-based video individual counting method that avoids explicit localization. GD3A establishes pixel-level correspondences between pedestrian descriptors across consecutive frames via optimal transport with an adaptive dustbin score, enabling the decomposition of global density maps into shared, inflow, and outflow components. Building on this framework, we further introduce DVTrack, which converts descriptor-level matching into instance-level associations through a descriptor voting mechanism for pedestrian tracking. Experimental results show that our methods significantly outperform existing approaches under dense crowds and complex motion, reducing counting error by 47.4 percent and improving tracking performance by 39.2 percent.
Temporal Unlearnable Examples: Preventing Personal Video Data from Unauthorized Exploitation by Object Tracking
Jul 10, 2025With the rise of social media, vast amounts of user-uploaded videos (e.g., YouTube) are utilized as training data for Visual Object Tracking (VOT). However, the VOT community has largely overlooked video data-privacy issues, as many private videos have been collected and used for training commercial models without authorization. To alleviate these issues, this paper presents the first investigation on preventing personal video data from unauthorized exploitation by deep trackers. Existing methods for preventing unauthorized data use primarily focus on image-based tasks (e.g., image classification), directly applying them to videos reveals several limitations, including inefficiency, limited effectiveness, and poor generalizability. To address these issues, we propose a novel generative framework for generating Temporal Unlearnable Examples (TUEs), and whose efficient computation makes it scalable for usage on large-scale video datasets. The trackers trained w/ TUEs heavily rely on unlearnable noises for temporal matching, ignoring the original data structure and thus ensuring training video data-privacy. To enhance the effectiveness of TUEs, we introduce a temporal contrastive loss, which further corrupts the learning of existing trackers when using our TUEs for training. Extensive experiments demonstrate that our approach achieves state-of-the-art performance in video data-privacy protection, with strong transferability across VOT models, datasets, and temporal matching tasks.
D2AF: A Dual-Driven Annotation and Filtering Framework for Visual Grounding
May 30, 2025
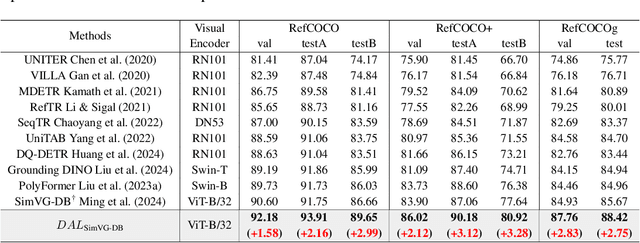
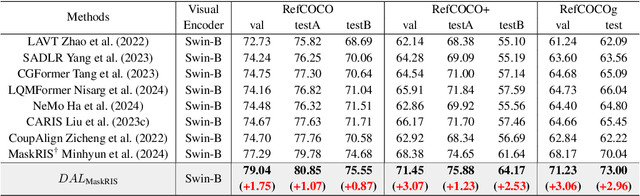
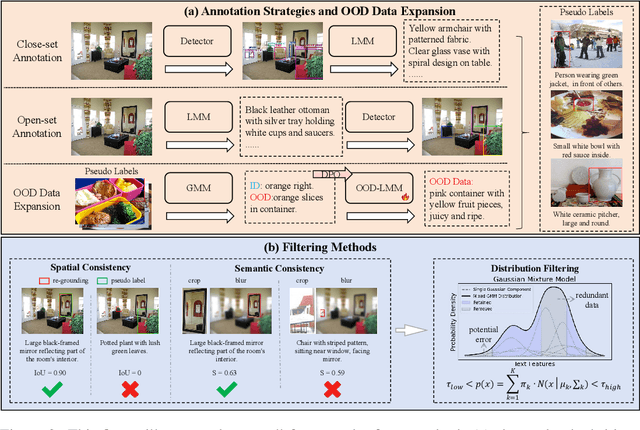
Visual Grounding is a task that aims to localize a target region in an image based on a free-form natural language description. With the rise of Transformer architectures, there is an increasing need for larger datasets to boost performance. However, the high cost of manual annotation poses a challenge, hindering the scale of data and the ability of large models to enhance their effectiveness. Previous pseudo label generation methods heavily rely on human-labeled captions of the original dataset, limiting scalability and diversity. To address this, we propose D2AF, a robust annotation framework for visual grounding using only input images. This approach overcomes dataset size limitations and enriches both the quantity and diversity of referring expressions. Our approach leverages multimodal large models and object detection models. By implementing dual-driven annotation strategies, we effectively generate detailed region-text pairs using both closed-set and open-set approaches. We further conduct an in-depth analysis of data quantity and data distribution. Our findings demonstrate that increasing data volume enhances model performance. However, the degree of improvement depends on how well the pseudo labels broaden the original data distribution. Based on these insights, we propose a consistency and distribution aware filtering method to further improve data quality by effectively removing erroneous and redundant data. This approach effectively eliminates noisy data, leading to improved performance. Experiments on three visual grounding tasks demonstrate that our method significantly improves the performance of existing models and achieves state-of-the-art results.
Few-Shot Vision-Language Action-Incremental Policy Learning
Apr 22, 2025Recently, Transformer-based robotic manipulation methods utilize multi-view spatial representations and language instructions to learn robot motion trajectories by leveraging numerous robot demonstrations. However, the collection of robot data is extremely challenging, and existing methods lack the capability for continuous learning on new tasks with only a few demonstrations. In this paper, we formulate these challenges as the Few-Shot Action-Incremental Learning (FSAIL) task, and accordingly design a Task-prOmpt graPh evolutIon poliCy (TOPIC) to address these issues. Specifically, to address the data scarcity issue in robotic imitation learning, TOPIC learns Task-Specific Prompts (TSP) through the deep interaction of multi-modal information within few-shot demonstrations, thereby effectively extracting the task-specific discriminative information. On the other hand, to enhance the capability for continual learning on new tasks and mitigate the issue of catastrophic forgetting, TOPIC adopts a Continuous Evolution Strategy (CES). CES leverages the intrinsic relationships between tasks to construct a task relation graph, which effectively facilitates the adaptation of new tasks by reusing skills learned from previous tasks. TOPIC pioneers few-shot continual learning in the robotic manipulation task, and extensive experimental results demonstrate that TOPIC outperforms state-of-the-art baselines by over 26$\%$ in success rate, significantly enhancing the continual learning capabilities of existing Transformer-based policies.
Density-based Object Detection in Crowded Scenes
Apr 14, 2025Compared with the generic scenes, crowded scenes contain highly-overlapped instances, which result in: 1) more ambiguous anchors during training of object detectors, and 2) more predictions are likely to be mistakenly suppressed in post-processing during inference. To address these problems, we propose two new strategies, density-guided anchors (DGA) and density-guided NMS (DG-NMS), which uses object density maps to jointly compute optimal anchor assignments and reweighing, as well as an adaptive NMS. Concretely, based on an unbalanced optimal transport (UOT) problem, the density owned by each ground-truth object is transported to each anchor position at a minimal transport cost. And density on anchors comprises an instance-specific density distribution, from which DGA decodes the optimal anchor assignment and re-weighting strategy. Meanwhile, DG-NMS utilizes the predicted density map to adaptively adjust the NMS threshold to reduce mistaken suppressions. In the UOT, a novel overlap-aware transport cost is specifically designed for ambiguous anchors caused by overlapped neighboring objects. Extensive experiments on the challenging CrowdHuman dataset with Citypersons dataset demonstrate that our proposed density-guided detector is effective and robust to crowdedness. The code and pre-trained models will be made available later.