 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitation Learning for Multi-turn LM Agents via On-policy Expert Corrections
Dec 16, 2025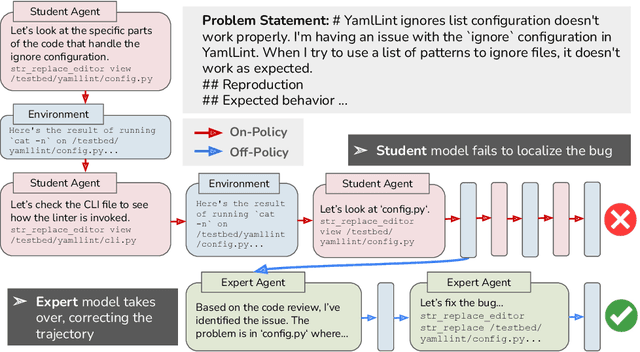
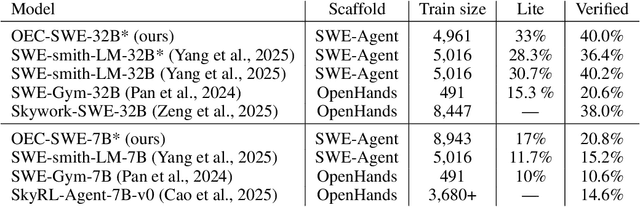
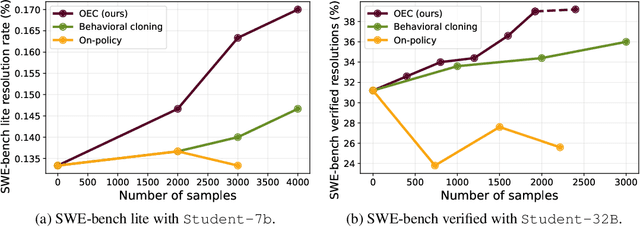

A popular paradigm for training LM agents relies on imitation learning, fine-tuning on expert trajectories. However, we show that the off-policy nature of imitation learning for multi-turn LM agents suffers from the fundamental limitation known as covariate shift: as the student policy's behavior diverges from the expert's, it encounters states not present in the training data, reducing the effectiveness of fine-tuning. Taking inspiration from the classic DAgger algorithm, we propose a novel data generation methodology for addressing covariate shift for multi-turn LLM training. We introduce on-policy expert corrections (OECs), partially on-policy data generated by starting rollouts with a student model and then switching to an expert model part way through the trajectory. We explore the effectiveness of our data generation technique in the domain of software engineering (SWE) tasks, a multi-turn setting where LLM agents must interact with a development environment to fix software bugs. Our experiments compare OEC data against various other on-policy and imitation learning approaches on SWE agent problems and train models using a common rejection sampling (i.e., using environment reward) combined with supervised fine-tuning technique. Experiments find that OEC trajectories show a relative 14% and 13% improvement over traditional imitation learning in the 7b and 32b setting, respectively, on SWE-bench verified. Our results demonstrate the need for combining expert demonstrations with on-policy data for effective multi-turn LM agent training.
Task-Aware 3D Affordance Segmentation via 2D Guidance and Geometric Refinement
Nov 12, 2025Understanding 3D scene-level affordances from natural language instructions is essential for enabling embodied agents to interact meaningfully in complex environments. However, this task remains challenging due to the need for semantic reasoning and spatial grounding. Existing methods mainly focus on object-level affordances or merely lift 2D predictions to 3D, neglecting rich geometric structure information in point clouds and incurring high computational costs. To address these limitations, we introduce Task-Aware 3D Scene-level Affordance segmentation (TASA), a novel geometry-optimized framework that jointly leverages 2D semantic cues and 3D geometric reasoning in a coarse-to-fine manner. To improve the affordance detection efficiency, TASA features a task-aware 2D affordance detection module to identify manipulable points from language and visual inputs, guiding the selection of task-relevant views. To fully exploit 3D geometric information, a 3D affordance refinement module is proposed to integrate 2D semantic priors with local 3D geometry, resulting in accurate and spatially coherent 3D affordance masks. Experiments on SceneFun3D demonstrate that TASA significantly outperforms the baselines in both accuracy and efficiency in scene-level affordance segmentation.
F1: A Vision-Language-Action Model Bridging Understanding and Generation to Actions
Sep 09, 2025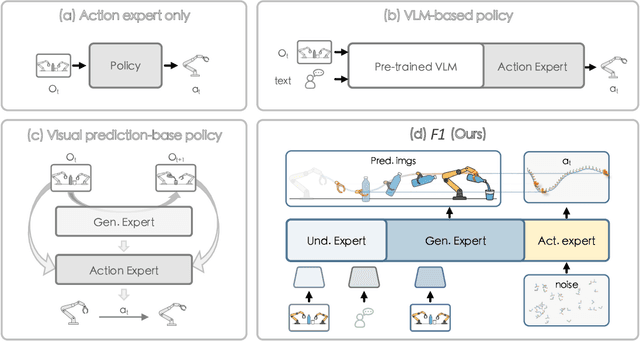

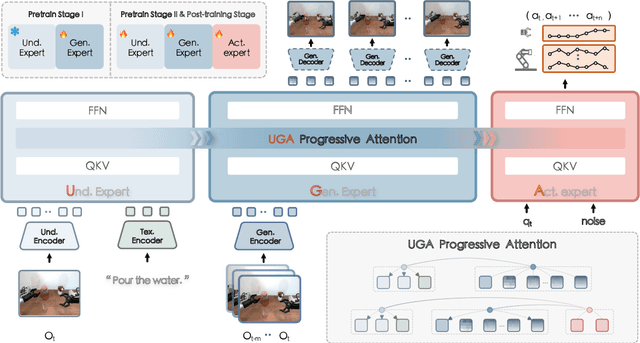

Executing language-conditioned tasks in dynamic visual environments remains a central challenge in embodied AI. Existing Vision-Language-Action (VLA) models predominantly adopt reactive state-to-action mappings, often leading to short-sighted behaviors and poor robustness in dynamic scenes. In this paper, we introduce F1, a pretrained VLA framework which integrates the visual foresight generation into decision-making pipeline. F1 adopts a Mixture-of-Transformer architecture with dedicated modules for perception, foresight generation, and control, thereby bridging understanding, generation, and actions. At its core, F1 employs a next-scale prediction mechanism to synthesize goal-conditioned visual foresight as explicit planning targets. By forecasting plausible future visual states, F1 reformulates action generation as a foresight-guided inverse dynamics problem, enabling actions that implicitly achieve visual goals. To endow F1 with robust and generalizable capabilities, we propose a three-stage training recipe on an extensive dataset comprising over 330k trajectories across 136 diverse tasks. This training scheme enhances modular reasoning and equips the model with transferable visual foresight, which is critical for complex and dynamic environments. Extensive evaluations on real-world tasks and simulation benchmarks demonstrate F1 consistently outperforms existing approaches, achieving substantial gains in both task success rate and generalization ability.
UAV-ON: A Benchmark for Open-World Object Goal Navigation with Aerial Agents
Aug 01, 2025Aerial navigation is a fundamental yet underexplored capability in embodied intelligence, enabling agents to operate in large-scale, unstructured environments where traditional navigation paradigms fall short. However, most existing research follows the Vision-and-Language Navigation (VLN) paradigm, which heavily depends on sequential linguistic instructions, limiting its scalability and autonomy. To address this gap, we introduce UAV-ON, a benchmark for large-scale Object Goal Navigation (ObjectNav) by aerial agents in open-world environments, where agents operate based on high-level semantic goals without relying on detailed instructional guidance as in VLN. UAV-ON comprises 14 high-fidelity Unreal Engine environments with diverse semantic regions and complex spatial layouts, covering urban, natural, and mixed-use settings. It defines 1270 annotated target objects, each characterized by an instance-level instruction that encodes category, physical footprint, and visual descriptors, allowing grounded reasoning. These instructions serve as semantic goals, introducing realistic ambiguity and complex reasoning challenges for aerial agents. To evaluate the benchmark, we implement several baseline methods, including Aerial ObjectNav Agent (AOA), a modular policy that integrates instruction semantics with egocentric observations for long-horizon, goal-directed exploration. Empirical results show that all baselines struggle in this setting, highlighting the compounded challenges of aerial navigation and semantic goal grounding. UAV-ON aims to advance research on scalable UAV autonomy driven by semantic goal descriptions in complex real-world environments.
Agent-RLVR: Training Software Engineering Agents via Guidance and Environment Rewards
Jun 13, 2025Reinforcement Learning from Verifiable Rewards (RLVR) has been widely adopted as the de facto method for enhancing the reasoning capabilities of large language models and has demonstrated notable success in verifiable domains like math and competitive programming tasks. However, the efficacy of RLVR diminishes significantly when applied to agentic environments. These settings, characterized by multi-step, complex problem solving, lead to high failure rates even for frontier LLMs, as the reward landscape is too sparse for effective model training via conventional RLVR. In this work, we introduce Agent-RLVR, a framework that makes RLVR effective in challenging agentic settings, with an initial focus on software engineering tasks. Inspired by human pedagogy, Agent-RLVR introduces agent guidance, a mechanism that actively steers the agent towards successful trajectories by leveraging diverse informational cues. These cues, ranging from high-level strategic plans to dynamic feedback on the agent's errors and environmental interactions, emulate a teacher's guidance, enabling the agent to navigate difficult solution spaces and promotes active self-improvement via additional environment exploration. In the Agent-RLVR training loop, agents first attempt to solve tasks to produce initial trajectories, which are then validated by unit tests and supplemented with agent guidance. Agents then reattempt with guidance, and the agent policy is updated with RLVR based on the rewards of these guided trajectories. Agent-RLVR elevates the pass@1 performance of Qwen-2.5-72B-Instruct from 9.4% to 22.4% on SWE-Bench Verified. We find that our guidance-augmented RLVR data is additionally useful for test-time reward model training, shown by further boosting pass@1 to 27.8%. Agent-RLVR lays the groundwork for training agents with RLVR in complex, real-world environments where conventional RL methods struggle.
STAR: Learning Diverse Robot Skill Abstractions through Rotation-Augmented Vector Quantization
Jun 04, 2025



Transforming complex actions into discrete skill abstractions has demonstrated strong potential for robotic manipulation. Existing approaches mainly leverage latent variable models, e.g., VQ-VAE, to learn skill abstractions through learned vectors (codebooks), while they suffer from codebook collapse and modeling the causal relationship between learned skills. To address these limitations, we present \textbf{S}kill \textbf{T}raining with \textbf{A}ugmented \textbf{R}otation (\textbf{STAR}), a framework that advances both skill learning and composition to complete complex behaviors. Specifically, to prevent codebook collapse, we devise rotation-augmented residual skill quantization (RaRSQ). It encodes relative angles between encoder outputs into the gradient flow by rotation-based gradient mechanism. Points within the same skill code are forced to be either pushed apart or pulled closer together depending on gradient directions. Further, to capture the causal relationship between skills, we present causal skill transformer (CST) which explicitly models dependencies between skill representations through an autoregressive mechanism for coherent action generation. Extensive experiments demonstrate the superiority of STAR on both LIBERO benchmark and realworld tasks, with around 12\% improvement over the baselines.
* Accepted by ICML 2025 Spotlight
Few-Shot Vision-Language Action-Incremental Policy Learning
Apr 22, 2025Recently, Transformer-based robotic manipulation methods utilize multi-view spatial representations and language instructions to learn robot motion trajectories by leveraging numerous robot demonstrations. However, the collection of robot data is extremely challenging, and existing methods lack the capability for continuous learning on new tasks with only a few demonstrations. In this paper, we formulate these challenges as the Few-Shot Action-Incremental Learning (FSAIL) task, and accordingly design a Task-prOmpt graPh evolutIon poliCy (TOPIC) to address these issues. Specifically, to address the data scarcity issue in robotic imitation learning, TOPIC learns Task-Specific Prompts (TSP) through the deep interaction of multi-modal information within few-shot demonstrations, thereby effectively extracting the task-specific discriminative information. On the other hand, to enhance the capability for continual learning on new tasks and mitigate the issue of catastrophic forgetting, TOPIC adopts a Continuous Evolution Strategy (CES). CES leverages the intrinsic relationships between tasks to construct a task relation graph, which effectively facilitates the adaptation of new tasks by reusing skills learned from previous tasks. TOPIC pioneers few-shot continual learning in the robotic manipulation task, and extensive experimental results demonstrate that TOPIC outperforms state-of-the-art baselines by over 26$\%$ in success rate, significantly enhancing the continual learning capabilities of existing Transformer-based policies.
Graph-based Diffusion Model for Collaborative Filtering
Apr 07, 2025Recently, diffusion-based recommendation methods have achieved impressive results. However, existing approaches predominantly treat each user's historical interactions as independent training samples, overlooking the potential of higher-order collaborative signals between users and items. Such signals, which encapsulate richer and more nuanced relationships, can be naturally captured using graph-based data structures. To address this limitation, we extend diffusion-based recommendation methods to the graph domain by directly modeling user-item bipartite graphs with diffusion models. This enables better modeling of the higher-order connectivity inherent in complex interaction dynamics. However, this extension introduces two primary challenges: (1) Noise Heterogeneity, where interactions are influenced by various forms of continuous and discrete noise, and (2) Relation Explosion, referring to the high computational costs of processing large-scale graphs. To tackle these challenges, we propose a Graph-based Diffusion Model for Collaborative Filtering (GDMCF). To address noise heterogeneity, we introduce a multi-level noise corruption mechanism that integrates both continuous and discrete noise, effectively simulating real-world interaction complexities. To mitigate relation explosion, we design a user-active guided diffusion process that selectively focuses on the most meaningful edges and active users, reducing inference costs while preserving the graph's topological integrity. Extensive experiments on three benchmark datasets demonstrate that GDMCF consistently outperforms state-of-the-art methods, highlighting its effectiveness in capturing higher-order collaborative signals and improving recommendation performance.
Spatial-Temporal Graph Diffusion Policy with Kinematic Modeling for Bimanual Robotic Manipulation
Mar 13, 2025



Despite the significant success of imitation learning in robotic manipulation, its application to bimanual tasks remains highly challenging. Existing approaches mainly learn a policy to predict a distant next-best end-effector pose (NBP) and then compute the corresponding joint rotation angles for motion using inverse kinematics. However, they suffer from two important issues: (1) rarely considering the physical robotic structure, which may cause self-collisions or interferences, and (2) overlooking the kinematics constraint, which may result in the predicted poses not conforming to the actual limitations of the robot joints. In this paper, we propose Kinematics enhanced Spatial-TemporAl gRaph Diffuser (KStar Diffuser). Specifically, (1) to incorporate the physical robot structure information into action prediction, KStar Diffuser maintains a dynamic spatial-temporal graph according to the physical bimanual joint motions at continuous timesteps. This dynamic graph serves as the robot-structure condition for denoising the actions; (2) to make the NBP learning objective consistent with kinematics, we introduce the differentiable kinematics to provide the reference for optimizing KStar Diffuser. This module regularizes the policy to predict more reliable and kinematics-aware next end-effector poses. Experimental results show that our method effectively leverages the physical structural information and generates kinematics-aware actions in both simulation and real-world
Embodied Crowd Counting
Mar 11, 2025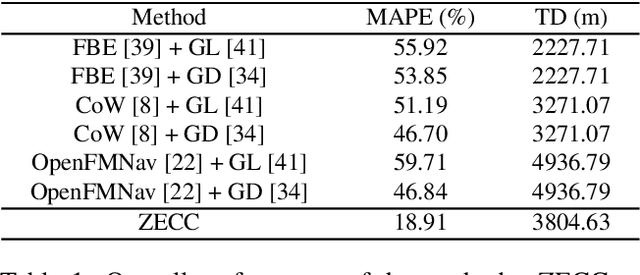
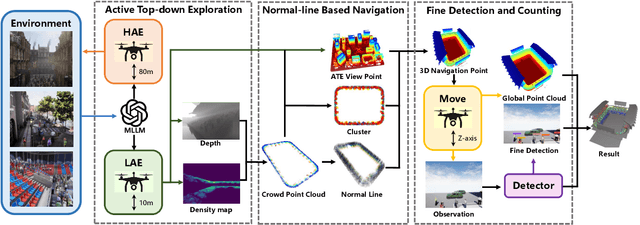


Occlusion is one of the fundamental challenges in crowd counting. In the community, various data-driven approaches have been developed to address this issue, yet their effectiveness is limited. This is mainly because most existing crowd counting datasets on which the methods are trained are based on passive cameras, restricting their ability to fully sense the environment. Recently, embodied navigation methods have shown significant potential in precise object detection in interactive scenes. These methods incorporate active camera settings, holding promise in addressing the fundamental issues in crowd counting. However, most existing methods are designed for indoor navigation, showing unknown performance in analyzing complex object distribution in large scale scenes, such as crowds. Besides, most existing embodied navigation datasets are indoor scenes with limited scale and object quantity, preventing them from being introduced into dense crowd analysis. Based on this, a novel task, Embodied Crowd Counting (ECC), is proposed. We first build up an interactive simulator, Embodied Crowd Counting Dataset (ECCD), which enables large scale scenes and large object quantity. A prior probability distribution that approximates realistic crowd distribution is introduced to generate crowds. Then, a zero-shot navigation method (ZECC) is proposed. This method contains a MLLM driven coarse-to-fine navigation mechanism, enabling active Z-axis exploration, and a normal-line-based crowd distribution analysis method for fine counting. Experimental results against baselines show that the proposed method achieves the best trade-off between counting accuracy and navigation cost.