 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Jul 23, 2025
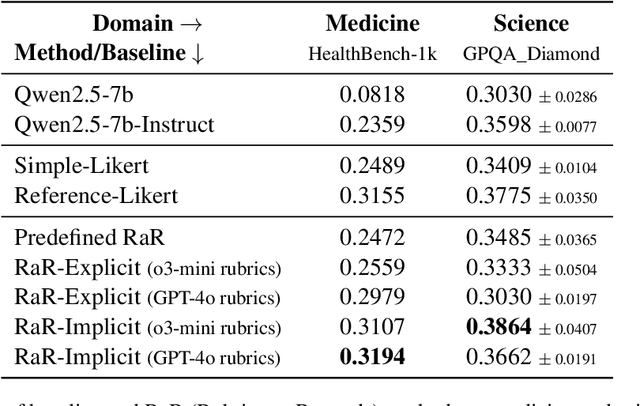
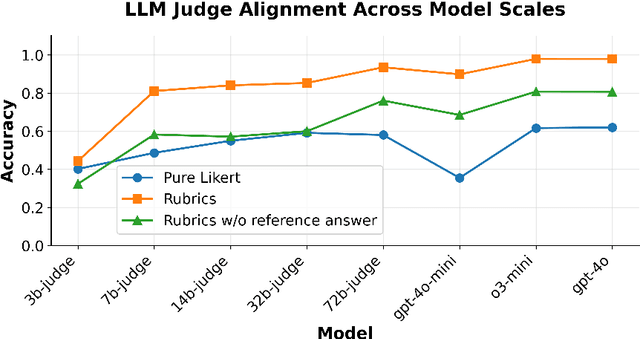
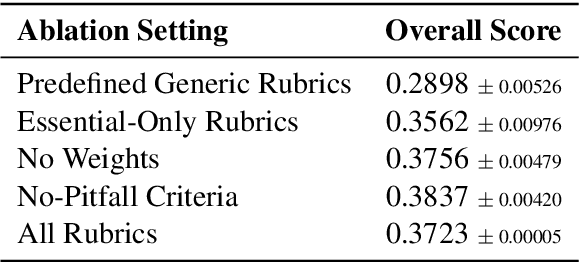
Extending Reinforcement Learning with Verifiable Rewards (RLVR) to real-world tasks often requires balancing objective and subjective evaluation criteria. However, many such tasks lack a single, unambiguous ground truth-making it difficult to define reliable reward signals for post-training language models. While traditional preference-based methods offer a workaround, they rely on opaque reward functions that are difficult to interpret and prone to spurious correlations. We introduce $\textbf{Rubrics as Rewards}$ (RaR), a framework that uses structured, checklist-style rubrics as interpretable reward signals for on-policy training with GRPO. Our best RaR method yields up to a $28\%$ relative improvement on HealthBench-1k compared to simple Likert-based approaches, while matching or surpassing the performance of reward signals derived from expert-written references. By treating rubrics as structured reward signals, we show that RaR enables smaller-scale judge models to better align with human preferences and sustain robust performance across model scales.
Agent-RLVR: Training Software Engineering Agents via Guidance and Environment Rewards
Jun 13, 2025Reinforcement Learning from Verifiable Rewards (RLVR) has been widely adopted as the de facto method for enhancing the reasoning capabilities of large language models and has demonstrated notable success in verifiable domains like math and competitive programming tasks. However, the efficacy of RLVR diminishes significantly when applied to agentic environments. These settings, characterized by multi-step, complex problem solving, lead to high failure rates even for frontier LLMs, as the reward landscape is too sparse for effective model training via conventional RLVR. In this work, we introduce Agent-RLVR, a framework that makes RLVR effective in challenging agentic settings, with an initial focus on software engineering tasks. Inspired by human pedagogy, Agent-RLVR introduces agent guidance, a mechanism that actively steers the agent towards successful trajectories by leveraging diverse informational cues. These cues, ranging from high-level strategic plans to dynamic feedback on the agent's errors and environmental interactions, emulate a teacher's guidance, enabling the agent to navigate difficult solution spaces and promotes active self-improvement via additional environment exploration. In the Agent-RLVR training loop, agents first attempt to solve tasks to produce initial trajectories, which are then validated by unit tests and supplemented with agent guidance. Agents then reattempt with guidance, and the agent policy is updated with RLVR based on the rewards of these guided trajectories. Agent-RLVR elevates the pass@1 performance of Qwen-2.5-72B-Instruct from 9.4% to 22.4% on SWE-Bench Verified. We find that our guidance-augmented RLVR data is additionally useful for test-time reward model training, shown by further boosting pass@1 to 27.8%. Agent-RLVR lays the groundwork for training agents with RLVR in complex, real-world environments where conventional RL methods struggle.
EnigmaEval: A Benchmark of Long Multimodal Reasoning Challenges
Feb 13, 2025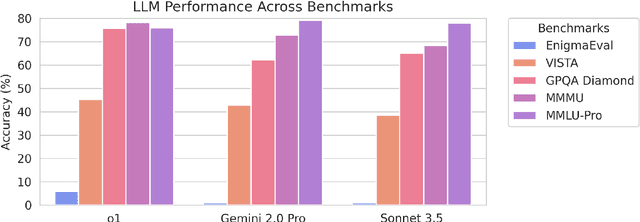



As language models master existing reasoning benchmarks, we need new challenges to evaluate their cognitive frontiers. Puzzle-solving events are rich repositories of challenging multimodal problems that test a wide range of advanced reasoning and knowledge capabilities, making them a unique testbed for evaluating frontier language models. We introduce EnigmaEval, a dataset of problems and solutions derived from puzzle competitions and events that probes models' ability to perform implicit knowledge synthesis and multi-step deductive reasoning. Unlike existing reasoning and knowledge benchmarks, puzzle solving challenges models to discover hidden connections between seemingly unrelated pieces of information to uncover solution paths. The benchmark comprises 1184 puzzles of varying complexity -- each typically requiring teams of skilled solvers hours to days to complete -- with unambiguous, verifiable solutions that enable efficient evaluation. State-of-the-art language models achieve extremely low accuracy on these puzzles, even lower than other difficult benchmarks such as Humanity's Last Exam, unveiling models' shortcomings when challenged with problems requiring unstructured and lateral reasoning.
ToolComp: A Multi-Tool Reasoning & Process Supervision Benchmark
Jan 02, 2025



Despite recent advances in AI, the development of systems capable of executing complex, multi-step reasoning tasks involving multiple tools remains a significant challenge. Current benchmarks fall short in capturing the real-world complexity of tool-use reasoning, where verifying the correctness of not only the final answer but also the intermediate steps is important for evaluation, development, and identifying failures during inference time. To bridge this gap, we introduce ToolComp, a comprehensive benchmark designed to evaluate multi-step tool-use reasoning. ToolComp is developed through a collaboration between models and human annotators, featuring human-edited/verified prompts, final answers, and process supervision labels, allowing for the evaluation of both final outcomes and intermediate reasoning. Evaluation across six different model families demonstrates the challenging nature of our dataset, with the majority of models achieving less than 50% accuracy. Additionally, we generate synthetic training data to compare the performance of outcome-supervised reward models (ORMs) with process-supervised reward models (PRMs) to assess their ability to improve complex tool-use reasoning as evaluated by ToolComp. Our results show that PRMs generalize significantly better than ORMs, achieving a 19% and 11% improvement in rank@1 accuracy for ranking base and fine-tuned model trajectories, respectively. These findings highlight the critical role of process supervision in both the evaluation and training of AI models, paving the way for more robust and capable systems in complex, multi-step tool-use tasks.
Planning In Natural Language Improves LLM Search For Code Generation
Sep 05, 2024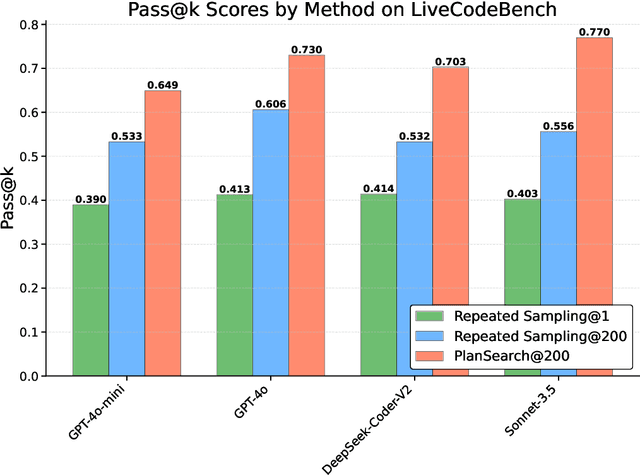
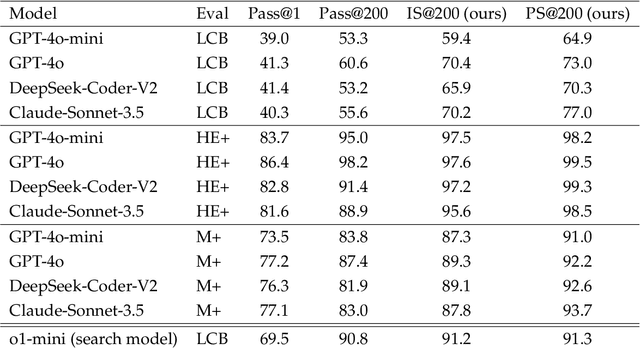
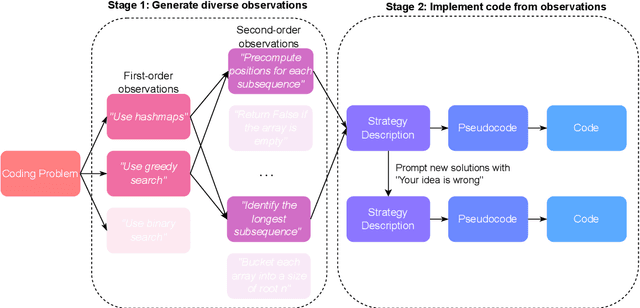
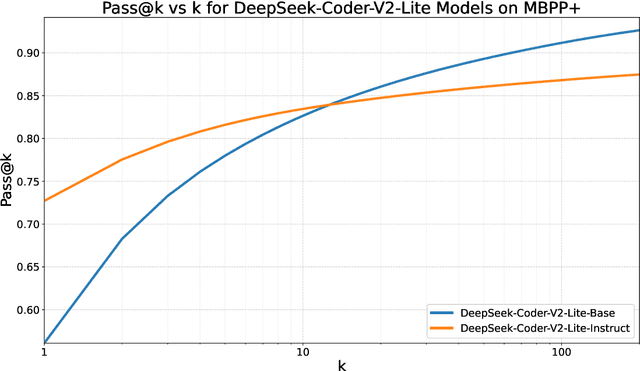
While scaling training compute has led to remarkable improvements in large language models (LLMs), scaling inference compute has not yet yielded analogous gains. We hypothesize that a core missing component is a lack of diverse LLM outputs, leading to inefficient search due to models repeatedly sampling highly similar, yet incorrect generations. We empirically demonstrate that this lack of diversity can be mitigated by searching over candidate plans for solving a problem in natural language. Based on this insight, we propose PLANSEARCH, a novel search algorithm which shows strong results across HumanEval+, MBPP+, and LiveCodeBench (a contamination-free benchmark for competitive coding). PLANSEARCH generates a diverse set of observations about the problem and then uses these observations to construct plans for solving the problem. By searching over plans in natural language rather than directly over code solutions, PLANSEARCH explores a significantly more diverse range of potential solutions compared to baseline search methods. Using PLANSEARCH on top of Claude 3.5 Sonnet achieves a state-of-the-art pass@200 of 77.0% on LiveCodeBench, outperforming both the best score achieved without search (pass@1 = 41.4%) and using standard repeated sampling (pass@200 = 60.6%). Finally, we show that, across all models, search algorithms, and benchmarks analyzed, we can accurately predict performance gains due to search as a direct function of the diversity over generated ideas.
Pre-Training Multimodal Hallucination Detectors with Corrupted Grounding Data
Aug 30, 2024



Multimodal language models can exhibit hallucinations in their outputs, which limits their reliability. The ability to automatically detect these errors is important for mitigating them, but has been less explored and existing efforts do not localize hallucinations, instead framing this as a classification task. In this work, we first pose multimodal hallucination detection as a sequence labeling task where models must localize hallucinated text spans and present a strong baseline model. Given the high cost of human annotations for this task, we propose an approach to improve the sample efficiency of these models by creating corrupted grounding data, which we use for pre-training. Leveraging phrase grounding data, we generate hallucinations to replace grounded spans and create hallucinated text. Experiments show that pre-training on this data improves sample efficiency when fine-tuning, and that the learning signal from the grounding data plays an important role in these improvements.
Learning Goal-Conditioned Representations for Language Reward Models
Jul 18, 2024



Techniques that learn improved representations via offline data or self-supervised objectives have shown impressive results in traditional reinforcement learning (RL). Nevertheless, it is unclear how improved representation learning can benefit reinforcement learning from human feedback (RLHF) on language models (LMs). In this work, we propose training reward models (RMs) in a contrastive, $\textit{goal-conditioned}$ fashion by increasing the representation similarity of future states along sampled preferred trajectories and decreasing the similarity along randomly sampled dispreferred trajectories. This objective significantly improves RM performance by up to 0.09 AUROC across challenging benchmarks, such as MATH and GSM8k. These findings extend to general alignment as well -- on the Helpful-Harmless dataset, we observe $2.3\%$ increase in accuracy. Beyond improving reward model performance, we show this way of training RM representations enables improved $\textit{steerability}$ because it allows us to evaluate the likelihood of an action achieving a particular goal-state (e.g., whether a solution is correct or helpful). Leveraging this insight, we find that we can filter up to $55\%$ of generated tokens during majority voting by discarding trajectories likely to end up in an "incorrect" state, which leads to significant cost savings. We additionally find that these representations can perform fine-grained control by conditioning on desired future goal-states. For example, we show that steering a Llama 3 model towards helpful generations with our approach improves helpfulness by $9.6\%$ over a supervised-fine-tuning trained baseline. Similarly, steering the model towards complex generations improves complexity by $21.6\%$ over the baseline. Overall, we find that training RMs in this contrastive, goal-conditioned fashion significantly improves performance and enables model steerability.
A Careful Examination of Large Language Model Performance on Grade School Arithmetic
May 02, 2024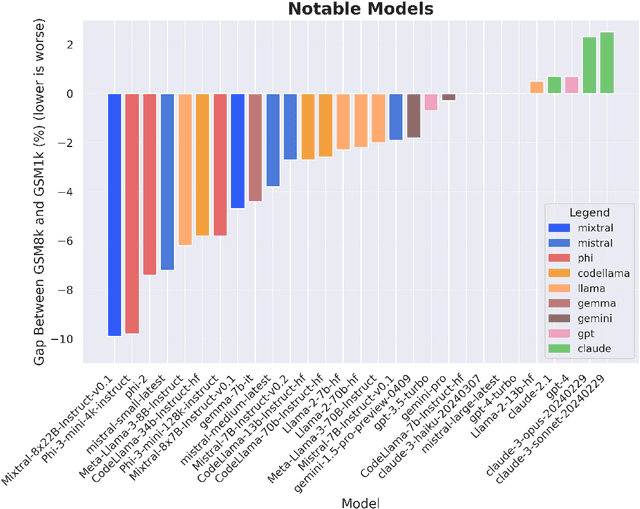

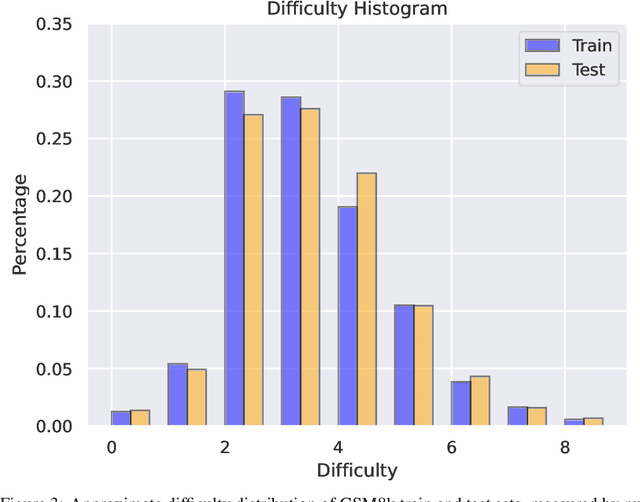
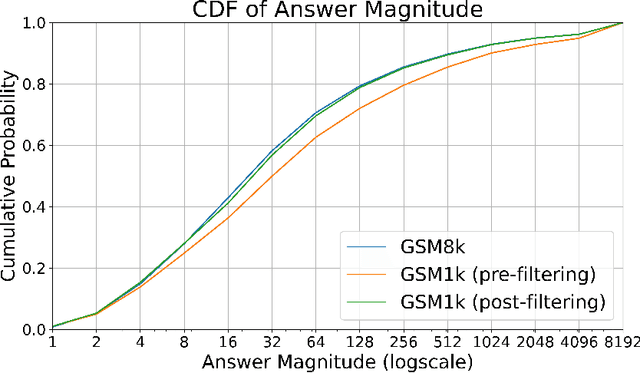
Large language models (LLMs) have achieved impressive success on many benchmarks for mathematical reasoning. However, there is growing concern that some of this performance actually reflects dataset contamination, where data closely resembling benchmark questions leaks into the training data, instead of true reasoning ability. To investigate this claim rigorously, we commission Grade School Math 1000 (GSM1k). GSM1k is designed to mirror the style and complexity of the established GSM8k benchmark, the gold standard for measuring elementary mathematical reasoning. We ensure that the two benchmarks are comparable across important metrics such as human solve rates, number of steps in solution, answer magnitude, and more. When evaluating leading open- and closed-source LLMs on GSM1k, we observe accuracy drops of up to 13%, with several families of models (e.g., Phi and Mistral) showing evidence of systematic overfitting across almost all model sizes. At the same time, many models, especially those on the frontier, (e.g., Gemini/GPT/Claude) show minimal signs of overfitting. Further analysis suggests a positive relationship (Spearman's r^2=0.32) between a model's probability of generating an example from GSM8k and its performance gap between GSM8k and GSM1k, suggesting that many models may have partially memorized GSM8k.
Out-of-Distribution Detection & Applications With Ablated Learned Temperature Energy
Jan 22, 2024As deep neural networks become adopted in high-stakes domains, it is crucial to be able to identify when inference inputs are Out-of-Distribution (OOD) so that users can be alerted of likely drops in performance and calibration despite high confidence. Among many others, existing methods use the following two scores to do so without training on any apriori OOD examples: a learned temperature and an energy score. In this paper we introduce Ablated Learned Temperature Energy (or "AbeT" for short), a method which combines these prior methods in novel ways with effective modifications. Due to these contributions, AbeT lowers the False Positive Rate at $95\%$ True Positive Rate (FPR@95) by $35.39\%$ in classification (averaged across all ID and OOD datasets measured) compared to state of the art without training networks in multiple stages or requiring hyperparameters or test-time backward passes. We additionally provide empirical insights as to how our model learns to distinguish between In-Distribution (ID) and OOD samples while only being explicitly trained on ID samples via exposure to misclassified ID examples at training time. Lastly, we show the efficacy of our method in identifying predicted bounding boxes and pixels corresponding to OOD objects in object detection and semantic segmentation, respectively - with an AUROC increase of $5.15\%$ in object detection and both a decrease in FPR@95 of $41.48\%$ and an increase in AUPRC of $34.20\%$ on average in semantic segmentation compared to previous state of the art.
A Baseline Analysis of Reward Models' Ability To Accurately Analyze Foundation Models Under Distribution Shift
Dec 04, 2023
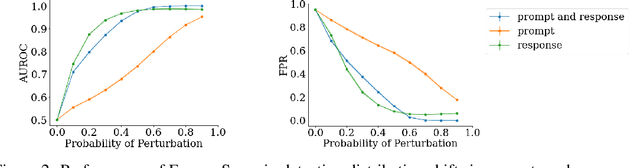
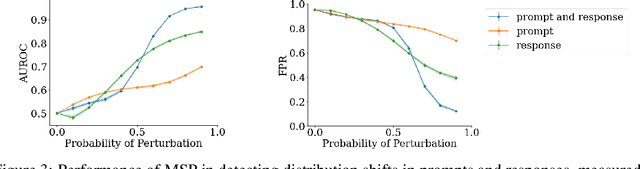
Foundation models, specifically Large Language Models (LLM's), have lately gained wide-spread attention and adoption. Reinforcement Learning with Human Feedback (RLHF) involves training a reward model to capture desired behaviors, which is then used to align LLM's. These reward models are additionally used at inference-time to estimate LLM responses' adherence to those desired behaviors. However, there is little work measuring how robust these reward models are to distribution shifts. In this work, we evaluate how reward model performance - measured via accuracy and calibration (i.e. alignment between accuracy and confidence) - is affected by distribution shift. We show novel calibration patterns and accuracy drops due to OOD prompts and responses, and that the reward model is more sensitive to shifts in responses than prompts. Additionally, we adapt an OOD detection technique commonly used in classification to the reward model setting to detect these distribution shifts in prompts and responses.