 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgress over Points: Reframing LM Benchmarks Around Scientific Objectives
Dec 12, 2025Current benchmarks that test LLMs on static, already-solved problems (e.g., math word problems) effectively demonstrated basic capability acquisition. The natural progression has been toward larger, more comprehensive and challenging collections of static problems, an approach that inadvertently constrains the kinds of advances we can measure and incentivize. To address this limitation, we argue for progress-oriented benchmarks, problem environments whose objectives are themselves the core targets of scientific progress, so that achieving state of the art on the benchmark advances the field. As a introductory step, we instantiate an environment based on the NanoGPT speedrun. The environment standardizes a dataset slice, a reference model and training harness, and rich telemetry, with run-time verification and anti-gaming checks. Evaluation centers on the scientific delta achieved: best-attained loss and the efficiency frontier. Using this environment, we achieve a new state-of-the-art training time, improving upon the previous record by 3 seconds, and qualitatively observe the emergence of novel algorithmic ideas. Moreover, comparisons between models and agents remain possible, but they are a means, not the end; the benchmark's purpose is to catalyze reusable improvements to the language modeling stack. With this release, the overarching goal is to seed a community shift from static problem leaderboards to test-time research on open-ended yet measurable scientific problems. In this new paradigm, progress on the benchmark is progress on the science, thus reframing "benchmarking" as a vehicle for scientific advancement.
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Jul 23, 2025
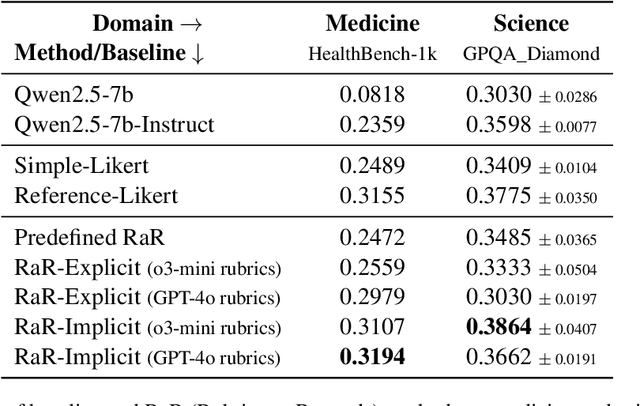
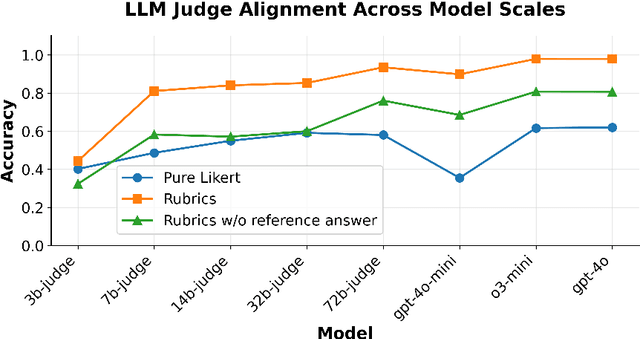
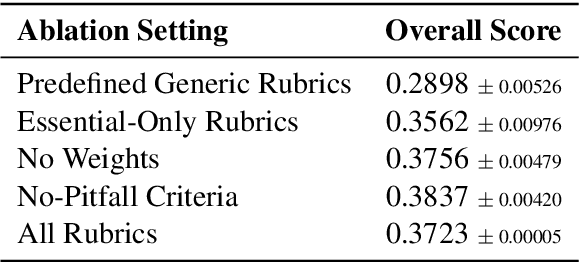
Extending Reinforcement Learning with Verifiable Rewards (RLVR) to real-world tasks often requires balancing objective and subjective evaluation criteria. However, many such tasks lack a single, unambiguous ground truth-making it difficult to define reliable reward signals for post-training language models. While traditional preference-based methods offer a workaround, they rely on opaque reward functions that are difficult to interpret and prone to spurious correlations. We introduce $\textbf{Rubrics as Rewards}$ (RaR), a framework that uses structured, checklist-style rubrics as interpretable reward signals for on-policy training with GRPO. Our best RaR method yields up to a $28\%$ relative improvement on HealthBench-1k compared to simple Likert-based approaches, while matching or surpassing the performance of reward signals derived from expert-written references. By treating rubrics as structured reward signals, we show that RaR enables smaller-scale judge models to better align with human preferences and sustain robust performance across model scales.
ToolComp: A Multi-Tool Reasoning & Process Supervision Benchmark
Jan 02, 2025



Despite recent advances in AI, the development of systems capable of executing complex, multi-step reasoning tasks involving multiple tools remains a significant challenge. Current benchmarks fall short in capturing the real-world complexity of tool-use reasoning, where verifying the correctness of not only the final answer but also the intermediate steps is important for evaluation, development, and identifying failures during inference time. To bridge this gap, we introduce ToolComp, a comprehensive benchmark designed to evaluate multi-step tool-use reasoning. ToolComp is developed through a collaboration between models and human annotators, featuring human-edited/verified prompts, final answers, and process supervision labels, allowing for the evaluation of both final outcomes and intermediate reasoning. Evaluation across six different model families demonstrates the challenging nature of our dataset, with the majority of models achieving less than 50% accuracy. Additionally, we generate synthetic training data to compare the performance of outcome-supervised reward models (ORMs) with process-supervised reward models (PRMs) to assess their ability to improve complex tool-use reasoning as evaluated by ToolComp. Our results show that PRMs generalize significantly better than ORMs, achieving a 19% and 11% improvement in rank@1 accuracy for ranking base and fine-tuned model trajectories, respectively. These findings highlight the critical role of process supervision in both the evaluation and training of AI models, paving the way for more robust and capable systems in complex, multi-step tool-use tasks.
Planning In Natural Language Improves LLM Search For Code Generation
Sep 05, 2024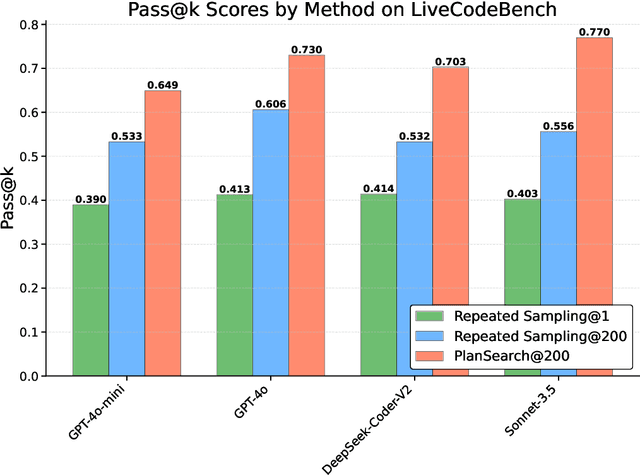
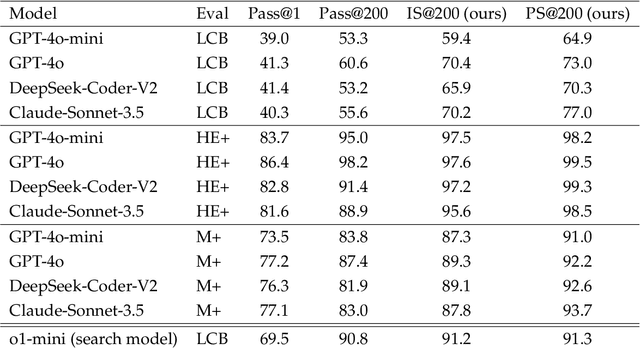
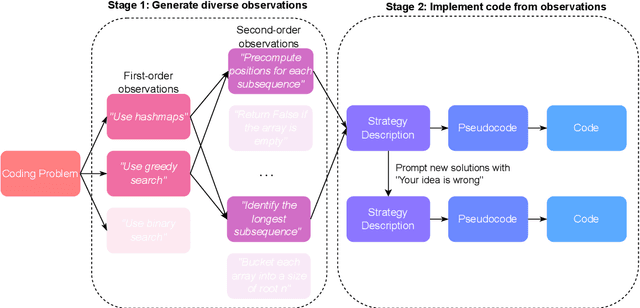
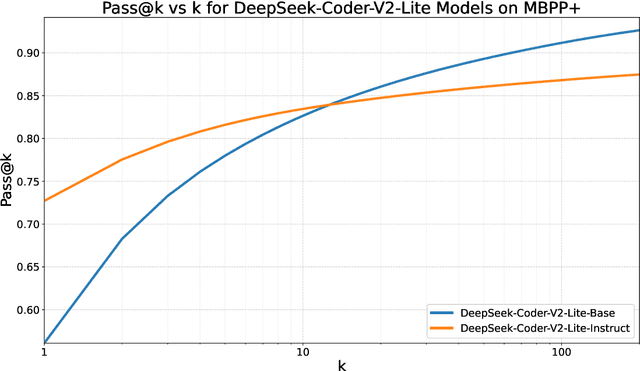
While scaling training compute has led to remarkable improvements in large language models (LLMs), scaling inference compute has not yet yielded analogous gains. We hypothesize that a core missing component is a lack of diverse LLM outputs, leading to inefficient search due to models repeatedly sampling highly similar, yet incorrect generations. We empirically demonstrate that this lack of diversity can be mitigated by searching over candidate plans for solving a problem in natural language. Based on this insight, we propose PLANSEARCH, a novel search algorithm which shows strong results across HumanEval+, MBPP+, and LiveCodeBench (a contamination-free benchmark for competitive coding). PLANSEARCH generates a diverse set of observations about the problem and then uses these observations to construct plans for solving the problem. By searching over plans in natural language rather than directly over code solutions, PLANSEARCH explores a significantly more diverse range of potential solutions compared to baseline search methods. Using PLANSEARCH on top of Claude 3.5 Sonnet achieves a state-of-the-art pass@200 of 77.0% on LiveCodeBench, outperforming both the best score achieved without search (pass@1 = 41.4%) and using standard repeated sampling (pass@200 = 60.6%). Finally, we show that, across all models, search algorithms, and benchmarks analyzed, we can accurately predict performance gains due to search as a direct function of the diversity over generated ideas.
Learning Goal-Conditioned Representations for Language Reward Models
Jul 18, 2024



Techniques that learn improved representations via offline data or self-supervised objectives have shown impressive results in traditional reinforcement learning (RL). Nevertheless, it is unclear how improved representation learning can benefit reinforcement learning from human feedback (RLHF) on language models (LMs). In this work, we propose training reward models (RMs) in a contrastive, $\textit{goal-conditioned}$ fashion by increasing the representation similarity of future states along sampled preferred trajectories and decreasing the similarity along randomly sampled dispreferred trajectories. This objective significantly improves RM performance by up to 0.09 AUROC across challenging benchmarks, such as MATH and GSM8k. These findings extend to general alignment as well -- on the Helpful-Harmless dataset, we observe $2.3\%$ increase in accuracy. Beyond improving reward model performance, we show this way of training RM representations enables improved $\textit{steerability}$ because it allows us to evaluate the likelihood of an action achieving a particular goal-state (e.g., whether a solution is correct or helpful). Leveraging this insight, we find that we can filter up to $55\%$ of generated tokens during majority voting by discarding trajectories likely to end up in an "incorrect" state, which leads to significant cost savings. We additionally find that these representations can perform fine-grained control by conditioning on desired future goal-states. For example, we show that steering a Llama 3 model towards helpful generations with our approach improves helpfulness by $9.6\%$ over a supervised-fine-tuning trained baseline. Similarly, steering the model towards complex generations improves complexity by $21.6\%$ over the baseline. Overall, we find that training RMs in this contrastive, goal-conditioned fashion significantly improves performance and enables model steerability.