 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Goal-Conditioned Representations for Language Reward Models
Jul 18, 2024



Techniques that learn improved representations via offline data or self-supervised objectives have shown impressive results in traditional reinforcement learning (RL). Nevertheless, it is unclear how improved representation learning can benefit reinforcement learning from human feedback (RLHF) on language models (LMs). In this work, we propose training reward models (RMs) in a contrastive, $\textit{goal-conditioned}$ fashion by increasing the representation similarity of future states along sampled preferred trajectories and decreasing the similarity along randomly sampled dispreferred trajectories. This objective significantly improves RM performance by up to 0.09 AUROC across challenging benchmarks, such as MATH and GSM8k. These findings extend to general alignment as well -- on the Helpful-Harmless dataset, we observe $2.3\%$ increase in accuracy. Beyond improving reward model performance, we show this way of training RM representations enables improved $\textit{steerability}$ because it allows us to evaluate the likelihood of an action achieving a particular goal-state (e.g., whether a solution is correct or helpful). Leveraging this insight, we find that we can filter up to $55\%$ of generated tokens during majority voting by discarding trajectories likely to end up in an "incorrect" state, which leads to significant cost savings. We additionally find that these representations can perform fine-grained control by conditioning on desired future goal-states. For example, we show that steering a Llama 3 model towards helpful generations with our approach improves helpfulness by $9.6\%$ over a supervised-fine-tuning trained baseline. Similarly, steering the model towards complex generations improves complexity by $21.6\%$ over the baseline. Overall, we find that training RMs in this contrastive, goal-conditioned fashion significantly improves performance and enables model steerability.
A Careful Examination of Large Language Model Performance on Grade School Arithmetic
May 02, 2024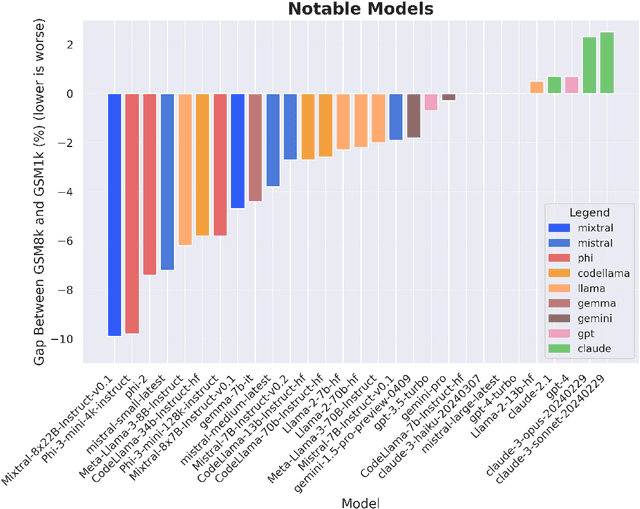

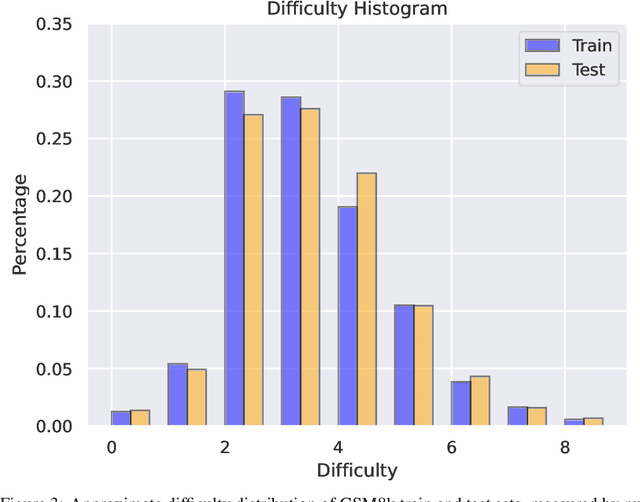
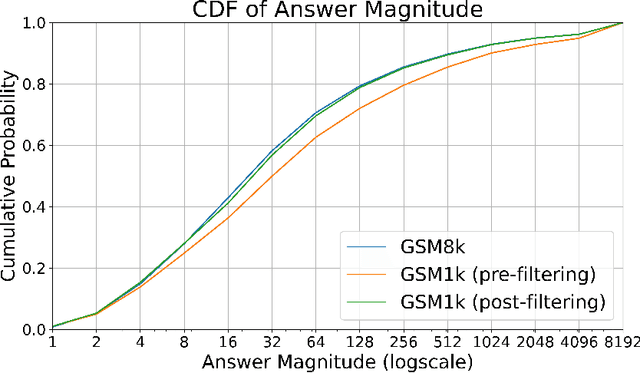
Large language models (LLMs) have achieved impressive success on many benchmarks for mathematical reasoning. However, there is growing concern that some of this performance actually reflects dataset contamination, where data closely resembling benchmark questions leaks into the training data, instead of true reasoning ability. To investigate this claim rigorously, we commission Grade School Math 1000 (GSM1k). GSM1k is designed to mirror the style and complexity of the established GSM8k benchmark, the gold standard for measuring elementary mathematical reasoning. We ensure that the two benchmarks are comparable across important metrics such as human solve rates, number of steps in solution, answer magnitude, and more. When evaluating leading open- and closed-source LLMs on GSM1k, we observe accuracy drops of up to 13%, with several families of models (e.g., Phi and Mistral) showing evidence of systematic overfitting across almost all model sizes. At the same time, many models, especially those on the frontier, (e.g., Gemini/GPT/Claude) show minimal signs of overfitting. Further analysis suggests a positive relationship (Spearman's r^2=0.32) between a model's probability of generating an example from GSM8k and its performance gap between GSM8k and GSM1k, suggesting that many models may have partially memorized GSM8k.
Post Hoc Explanations of Language Models Can Improve Language Models
May 19, 2023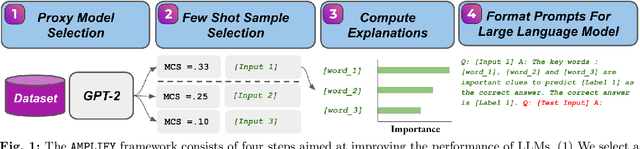
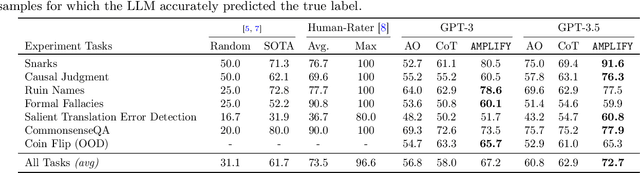
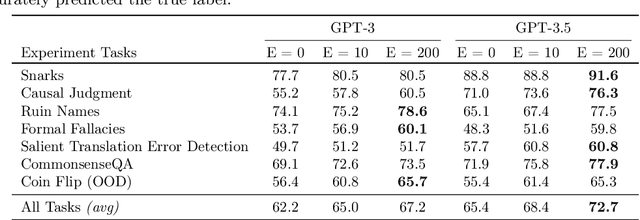
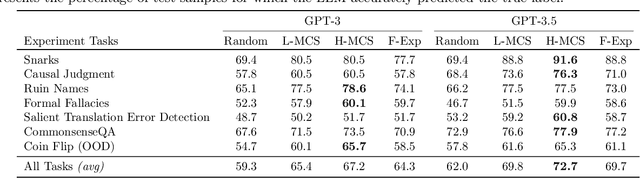
Large Language Models (LLMs) have demonstrated remarkable capabilities in performing complex tasks. Moreover, recent research has shown that incorporating human-annotated rationales (e.g., Chain-of- Thought prompting) during in-context learning can significantly enhance the performance of these models, particularly on tasks that require reasoning capabilities. However, incorporating such rationales poses challenges in terms of scalability as this requires a high degree of human involvement. In this work, we present a novel framework, Amplifying Model Performance by Leveraging In-Context Learning with Post Hoc Explanations (AMPLIFY), which addresses the aforementioned challenges by automating the process of rationale generation. To this end, we leverage post hoc explanation methods which output attribution scores (explanations) capturing the influence of each of the input features on model predictions. More specifically, we construct automated natural language rationales that embed insights from post hoc explanations to provide corrective signals to LLMs. Extensive experimentation with real-world datasets demonstrates that our framework, AMPLIFY, leads to prediction accuracy improvements of about 10-25% over a wide range of tasks, including those where prior approaches which rely on human-annotated rationales such as Chain-of-Thought prompting fall short. Our work makes one of the first attempts at highlighting the potential of post hoc explanations as valuable tools for enhancing the effectiveness of LLMs. Furthermore, we conduct additional empirical analyses and ablation studies to demonstrate the impact of each of the components of AMPLIFY, which, in turn, lead to critical insights for refining in-context learning.
TABLET: Learning From Instructions For Tabular Data
Apr 25, 2023
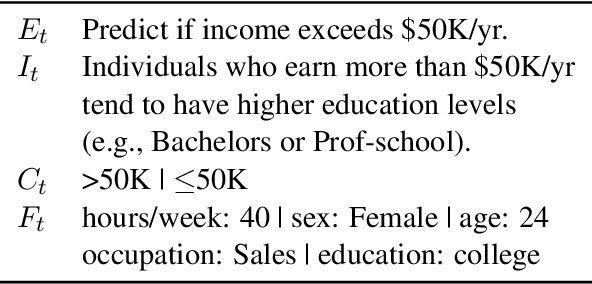

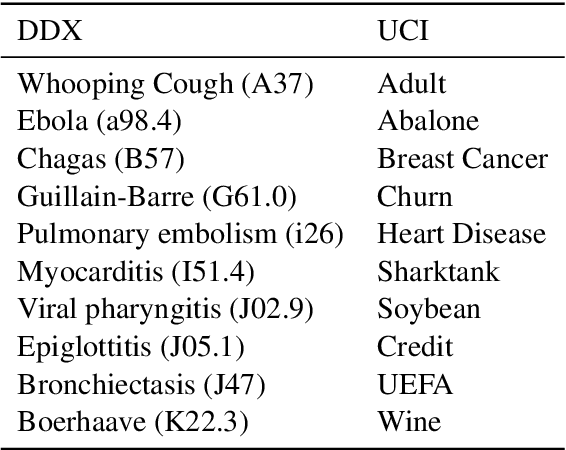
Acquiring high-quality data is often a significant challenge in training machine learning (ML) models for tabular prediction, particularly in privacy-sensitive and costly domains like medicine and finance. Providing natural language instructions to large language models (LLMs) offers an alternative solution. However, it is unclear how effectively instructions leverage the knowledge in LLMs for solving tabular prediction problems. To address this gap, we introduce TABLET, a benchmark of 20 diverse tabular datasets annotated with instructions that vary in their phrasing, granularity, and technicality. Additionally, TABLET includes the instructions' logic and structured modifications to the instructions. We find in-context instructions increase zero-shot F1 performance for Flan-T5 11b by 44% on average and 13% for ChatGPT on TABLET. Also, we explore the limitations of using LLMs for tabular prediction in our benchmark by evaluating instruction faithfulness. We find LLMs often ignore instructions and fail to predict specific instances correctly, even with examples. Our analysis on TABLET shows that, while instructions help LLM performance, learning from instructions for tabular data requires new capabilities.
TalkToModel: Understanding Machine Learning Models With Open Ended Dialogues
Jul 08, 2022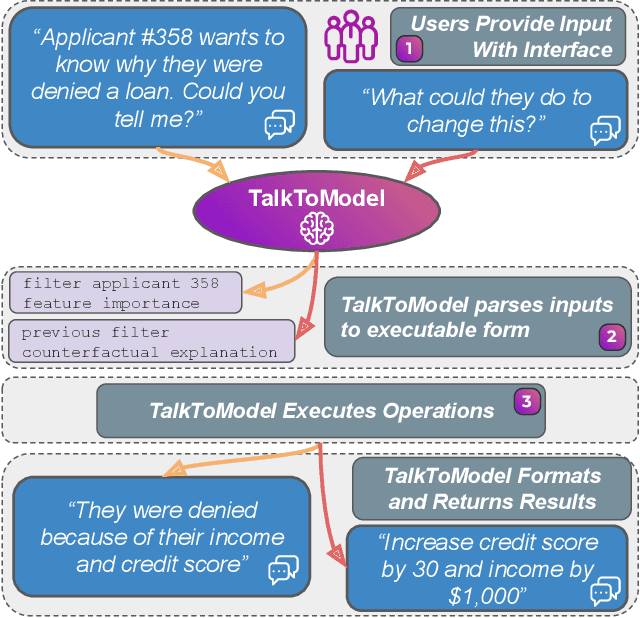



Machine Learning (ML) models are increasingly used to make critical decisions in real-world applications, yet they have also become more complex, making them harder to understand. To this end, several techniques to explain model predictions have been proposed. However, practitioners struggle to leverage explanations because they often do not know which to use, how to interpret the results, and may have insufficient data science experience to obtain explanations. In addition, most current works focus on generating one-shot explanations and do not allow users to follow up and ask fine-grained questions about the explanations, which can be frustrating. In this work, we address these challenges by introducing TalkToModel: an open-ended dialogue system for understanding machine learning models. Specifically, TalkToModel comprises three key components: 1) a natural language interface for engaging in dialogues, making understanding ML models highly accessible, 2) a dialogue engine that adapts to any tabular model and dataset, interprets natural language, maps it to appropriate operations (e.g., feature importance explanations, counterfactual explanations, showing model errors), and generates text responses, and 3) an execution component that run the operations and ensures explanations are accurate. We carried out quantitative and human subject evaluations of TalkToModel. We found the system understands user questions on novel datasets and models with high accuracy, demonstrating the system's capacity to generalize to new situations. In human evaluations, 73% of healthcare workers (e.g., doctors and nurses) agreed they would use TalkToModel over baseline point-and-click systems, and 84.6% of ML graduate students agreed TalkToModel was easier to use.
SAFER: Data-Efficient and Safe Reinforcement Learning via Skill Acquisition
Feb 10, 2022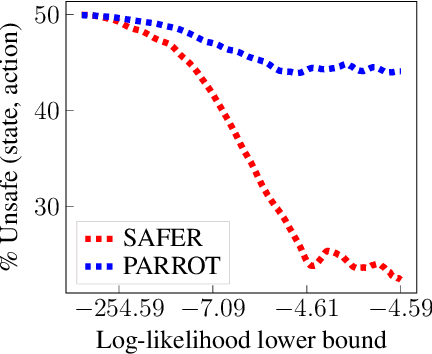
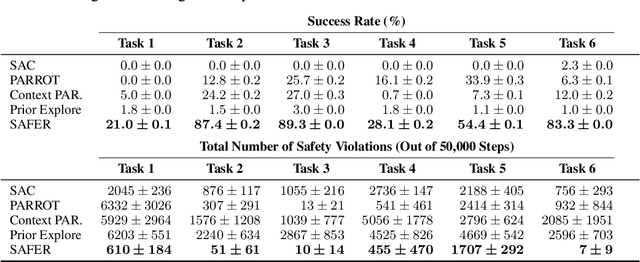
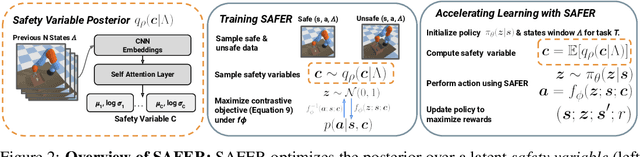
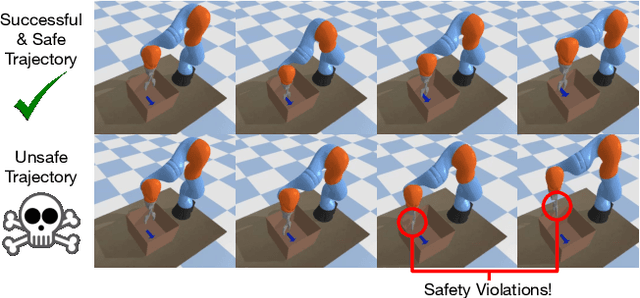
Though many reinforcement learning (RL) problems involve learning policies in settings with difficult-to-specify safety constraints and sparse rewards, current methods struggle to acquire successful and safe policies. Methods that extract useful policy primitives from offline datasets using generative modeling have recently shown promise at accelerating RL in these more complex settings. However, we discover that current primitive-learning methods may not be well-equipped for safe policy learning and may promote unsafe behavior due to their tendency to ignore data from undesirable behaviors. To overcome these issues, we propose SAFEty skill pRiors (SAFER), an algorithm that accelerates policy learning on complex control tasks under safety constraints. Through principled training on an offline dataset, SAFER learns to extract safe primitive skills. In the inference stage, policies trained with SAFER learn to compose safe skills into successful policies. We theoretically characterize why SAFER can enforce safe policy learning and demonstrate its effectiveness on several complex safety-critical robotic grasping tasks inspired by the game Operation, in which SAFER outperforms baseline methods in learning successful policies and enforcing safety.
Rethinking Explainability as a Dialogue: A Practitioner's Perspective
Feb 03, 2022
As practitioners increasingly deploy machine learning models in critical domains such as health care, finance, and policy, it becomes vital to ensure that domain experts function effectively alongside these models. Explainability is one way to bridge the gap between human decision-makers and machine learning models. However, most of the existing work on explainability focuses on one-off, static explanations like feature importances or rule lists. These sorts of explanations may not be sufficient for many use cases that require dynamic, continuous discovery from stakeholders. In the literature, few works ask decision-makers about the utility of existing explanations and other desiderata they would like to see in an explanation going forward. In this work, we address this gap and carry out a study where we interview doctors, healthcare professionals, and policymakers about their needs and desires for explanations. Our study indicates that decision-makers would strongly prefer interactive explanations in the form of natural language dialogues. Domain experts wish to treat machine learning models as "another colleague", i.e., one who can be held accountable by asking why they made a particular decision through expressive and accessible natural language interactions. Considering these needs, we outline a set of five principles researchers should follow when designing interactive explanations as a starting place for future work. Further, we show why natural language dialogues satisfy these principles and are a desirable way to build interactive explanations. Next, we provide a design of a dialogue system for explainability and discuss the risks, trade-offs, and research opportunities of building these systems. Overall, we hope our work serves as a starting place for researchers and engineers to design interactive explainability systems.
Feature Attributions and Counterfactual Explanations Can Be Manipulated
Jun 25, 2021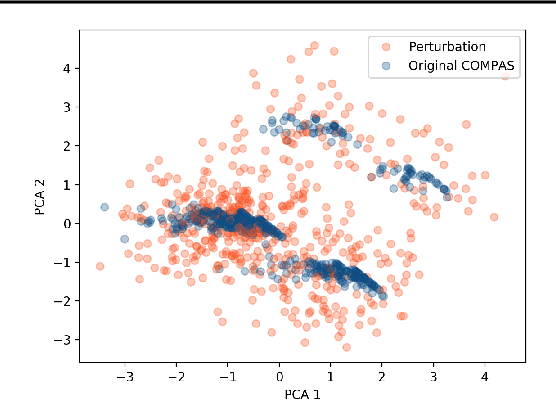
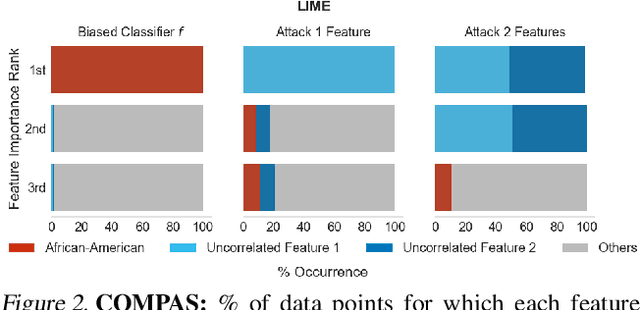
As machine learning models are increasingly used in critical decision-making settings (e.g., healthcare, finance), there has been a growing emphasis on developing methods to explain model predictions. Such \textit{explanations} are used to understand and establish trust in models and are vital components in machine learning pipelines. Though explanations are a critical piece in these systems, there is little understanding about how they are vulnerable to manipulation by adversaries. In this paper, we discuss how two broad classes of explanations are vulnerable to manipulation. We demonstrate how adversaries can design biased models that manipulate model agnostic feature attribution methods (e.g., LIME \& SHAP) and counterfactual explanations that hill-climb during the counterfactual search (e.g., Wachter's Algorithm \& DiCE) into \textit{concealing} the model's biases. These vulnerabilities allow an adversary to deploy a biased model, yet explanations will not reveal this bias, thereby deceiving stakeholders into trusting the model. We evaluate the manipulations on real world data sets, including COMPAS and Communities \& Crime, and find explanations can be manipulated in practice.
On the Lack of Robust Interpretability of Neural Text Classifiers
Jun 08, 2021
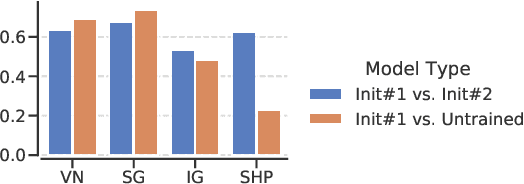


With the ever-increasing complexity of neural language models, practitioners have turned to methods for understanding the predictions of these models. One of the most well-adopted approaches for model interpretability is feature-based interpretability, i.e., ranking the features in terms of their impact on model predictions. Several prior studies have focused on assessing the fidelity of feature-based interpretability methods, i.e., measuring the impact of dropping the top-ranked features on the model output. However, relatively little work has been conducted on quantifying the robustness of interpretations. In this work, we assess the robustness of interpretations of neural text classifiers, specifically, those based on pretrained Transformer encoders, using two randomization tests. The first compares the interpretations of two models that are identical except for their initializations. The second measures whether the interpretations differ between a model with trained parameters and a model with random parameters. Both tests show surprising deviations from expected behavior, raising questions about the extent of insights that practitioners may draw from interpretations.
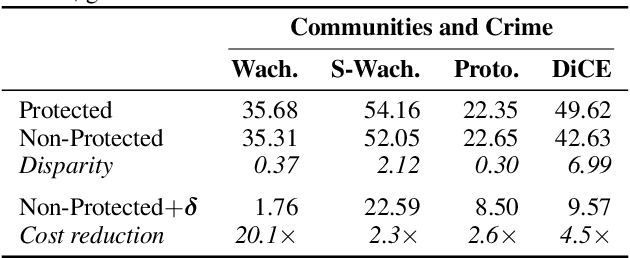
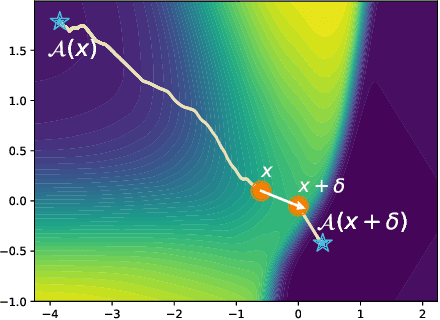
Counterfactual Explanations Can Be Manipulated
Jun 04, 2021
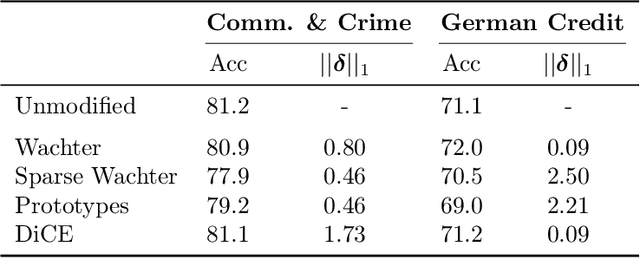
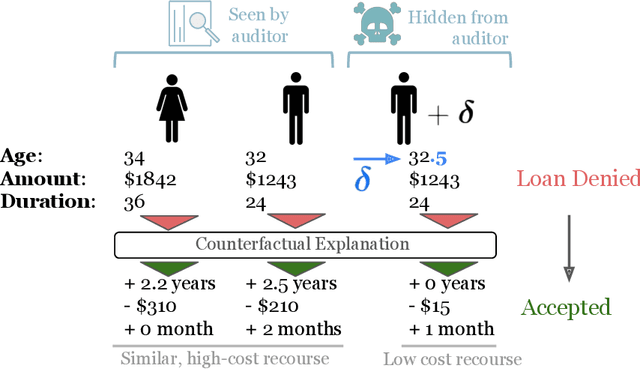

Counterfactual explanations are emerging as an attractive option for providing recourse to individuals adversely impacted by algorithmic decisions. As they are deployed in critical applications (e.g. law enforcement, financial lending), it becomes important to ensure that we clearly understand the vulnerabilities of these methods and find ways to address them. However, there is little understanding of the vulnerabilities and shortcomings of counterfactual explanations. In this work, we introduce the first framework that describes the vulnerabilities of counterfactual explanations and shows how they can be manipulated. More specifically, we show counterfactual explanations may converge to drastically different counterfactuals under a small perturbation indicating they are not robust. Leveraging this insight, we introduce a novel objective to train seemingly fair models where counterfactual explanations find much lower cost recourse under a slight perturbation. We describe how these models can unfairly provide low-cost recourse for specific subgroups in the data while appearing fair to auditors. We perform experiments on loan and violent crime prediction data sets where certain subgroups achieve up to 20x lower cost recourse under the perturbation. These results raise concerns regarding the dependability of current counterfactual explanation techniques, which we hope will inspire investigations in robust counterfactual explanations.