 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCP-Atlas: A Large-Scale Benchmark for Tool-Use Competency with Real MCP Servers
Jan 31, 2026The Model Context Protocol (MCP) is rapidly becoming the standard interface for Large Language Models (LLMs) to discover and invoke external tools. However, existing evaluations often fail to capture the complexity of real-world scenarios, relying on restricted toolsets, simplistic workflows, or subjective LLM-as-a-judge metrics. We introduce MCP-Atlas, a large-scale benchmark for evaluating tool-use competency, comprising 36 real MCP servers and 220 tools. It includes 1,000 tasks designed to assess tool-use competency in realistic, multi-step workflows. Tasks use natural language prompts that avoid naming specific tools or servers, requiring agents to identify and orchestrate 3-6 tool calls across multiple servers. We score tasks using a claims-based rubric that awards partial credit based on the factual claims satisfied in the model's final answer, complemented by internal diagnostics on tool discovery, parameterization, syntax, error recovery, and efficiency. Evaluation results on frontier models reveal that top models achieve pass rates exceeding 50%, with primary failures arising from inadequate tool usage and task understanding. We release the task schema, containerized harness, and a 500-task public subset of the benchmark dataset to facilitate reproducible comparisons and advance the development of robust, tool-augmented agents.
Imitation Learning for Multi-turn LM Agents via On-policy Expert Corrections
Dec 16, 2025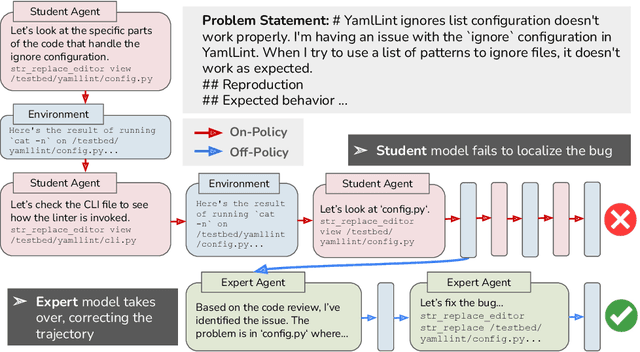
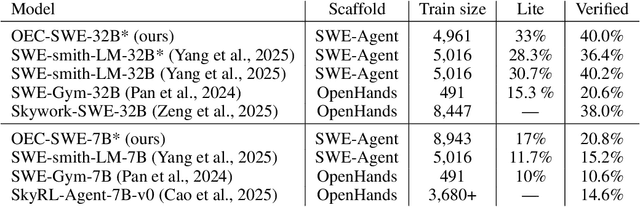
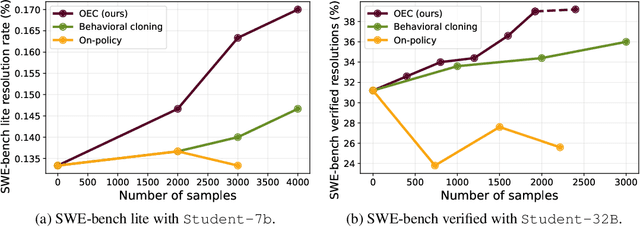

A popular paradigm for training LM agents relies on imitation learning, fine-tuning on expert trajectories. However, we show that the off-policy nature of imitation learning for multi-turn LM agents suffers from the fundamental limitation known as covariate shift: as the student policy's behavior diverges from the expert's, it encounters states not present in the training data, reducing the effectiveness of fine-tuning. Taking inspiration from the classic DAgger algorithm, we propose a novel data generation methodology for addressing covariate shift for multi-turn LLM training. We introduce on-policy expert corrections (OECs), partially on-policy data generated by starting rollouts with a student model and then switching to an expert model part way through the trajectory. We explore the effectiveness of our data generation technique in the domain of software engineering (SWE) tasks, a multi-turn setting where LLM agents must interact with a development environment to fix software bugs. Our experiments compare OEC data against various other on-policy and imitation learning approaches on SWE agent problems and train models using a common rejection sampling (i.e., using environment reward) combined with supervised fine-tuning technique. Experiments find that OEC trajectories show a relative 14% and 13% improvement over traditional imitation learning in the 7b and 32b setting, respectively, on SWE-bench verified. Our results demonstrate the need for combining expert demonstrations with on-policy data for effective multi-turn LM agent training.
Agent-RLVR: Training Software Engineering Agents via Guidance and Environment Rewards
Jun 13, 2025Reinforcement Learning from Verifiable Rewards (RLVR) has been widely adopted as the de facto method for enhancing the reasoning capabilities of large language models and has demonstrated notable success in verifiable domains like math and competitive programming tasks. However, the efficacy of RLVR diminishes significantly when applied to agentic environments. These settings, characterized by multi-step, complex problem solving, lead to high failure rates even for frontier LLMs, as the reward landscape is too sparse for effective model training via conventional RLVR. In this work, we introduce Agent-RLVR, a framework that makes RLVR effective in challenging agentic settings, with an initial focus on software engineering tasks. Inspired by human pedagogy, Agent-RLVR introduces agent guidance, a mechanism that actively steers the agent towards successful trajectories by leveraging diverse informational cues. These cues, ranging from high-level strategic plans to dynamic feedback on the agent's errors and environmental interactions, emulate a teacher's guidance, enabling the agent to navigate difficult solution spaces and promotes active self-improvement via additional environment exploration. In the Agent-RLVR training loop, agents first attempt to solve tasks to produce initial trajectories, which are then validated by unit tests and supplemented with agent guidance. Agents then reattempt with guidance, and the agent policy is updated with RLVR based on the rewards of these guided trajectories. Agent-RLVR elevates the pass@1 performance of Qwen-2.5-72B-Instruct from 9.4% to 22.4% on SWE-Bench Verified. We find that our guidance-augmented RLVR data is additionally useful for test-time reward model training, shown by further boosting pass@1 to 27.8%. Agent-RLVR lays the groundwork for training agents with RLVR in complex, real-world environments where conventional RL methods struggle.
Learning Goal-Conditioned Representations for Language Reward Models
Jul 18, 2024



Techniques that learn improved representations via offline data or self-supervised objectives have shown impressive results in traditional reinforcement learning (RL). Nevertheless, it is unclear how improved representation learning can benefit reinforcement learning from human feedback (RLHF) on language models (LMs). In this work, we propose training reward models (RMs) in a contrastive, $\textit{goal-conditioned}$ fashion by increasing the representation similarity of future states along sampled preferred trajectories and decreasing the similarity along randomly sampled dispreferred trajectories. This objective significantly improves RM performance by up to 0.09 AUROC across challenging benchmarks, such as MATH and GSM8k. These findings extend to general alignment as well -- on the Helpful-Harmless dataset, we observe $2.3\%$ increase in accuracy. Beyond improving reward model performance, we show this way of training RM representations enables improved $\textit{steerability}$ because it allows us to evaluate the likelihood of an action achieving a particular goal-state (e.g., whether a solution is correct or helpful). Leveraging this insight, we find that we can filter up to $55\%$ of generated tokens during majority voting by discarding trajectories likely to end up in an "incorrect" state, which leads to significant cost savings. We additionally find that these representations can perform fine-grained control by conditioning on desired future goal-states. For example, we show that steering a Llama 3 model towards helpful generations with our approach improves helpfulness by $9.6\%$ over a supervised-fine-tuning trained baseline. Similarly, steering the model towards complex generations improves complexity by $21.6\%$ over the baseline. Overall, we find that training RMs in this contrastive, goal-conditioned fashion significantly improves performance and enables model steerability.
A Careful Examination of Large Language Model Performance on Grade School Arithmetic
May 02, 2024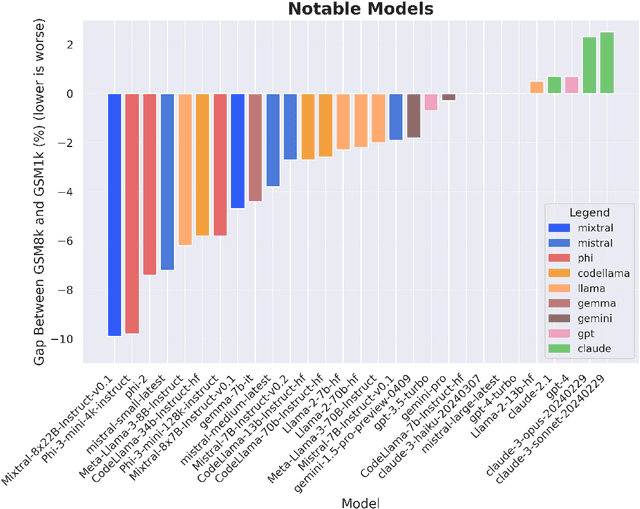

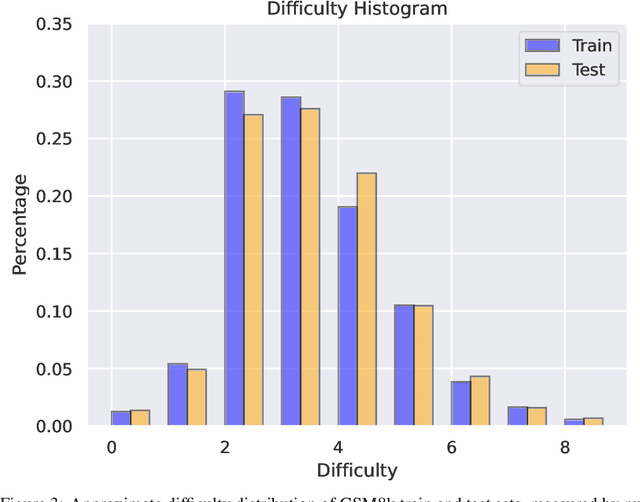
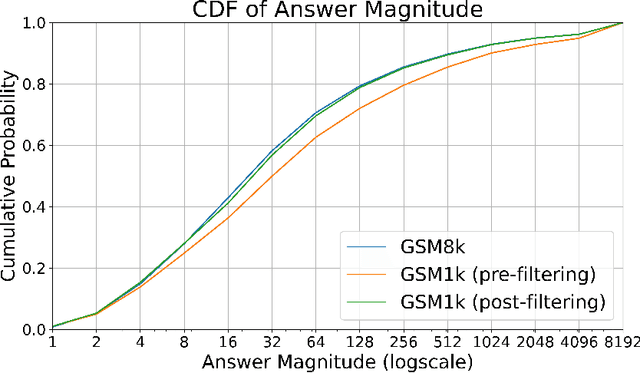
Large language models (LLMs) have achieved impressive success on many benchmarks for mathematical reasoning. However, there is growing concern that some of this performance actually reflects dataset contamination, where data closely resembling benchmark questions leaks into the training data, instead of true reasoning ability. To investigate this claim rigorously, we commission Grade School Math 1000 (GSM1k). GSM1k is designed to mirror the style and complexity of the established GSM8k benchmark, the gold standard for measuring elementary mathematical reasoning. We ensure that the two benchmarks are comparable across important metrics such as human solve rates, number of steps in solution, answer magnitude, and more. When evaluating leading open- and closed-source LLMs on GSM1k, we observe accuracy drops of up to 13%, with several families of models (e.g., Phi and Mistral) showing evidence of systematic overfitting across almost all model sizes. At the same time, many models, especially those on the frontier, (e.g., Gemini/GPT/Claude) show minimal signs of overfitting. Further analysis suggests a positive relationship (Spearman's r^2=0.32) between a model's probability of generating an example from GSM8k and its performance gap between GSM8k and GSM1k, suggesting that many models may have partially memorized GSM8k.
Do Androids Laugh at Electric Sheep? Humor "Understanding" Benchmarks from The New Yorker Caption Contest
Sep 13, 2022

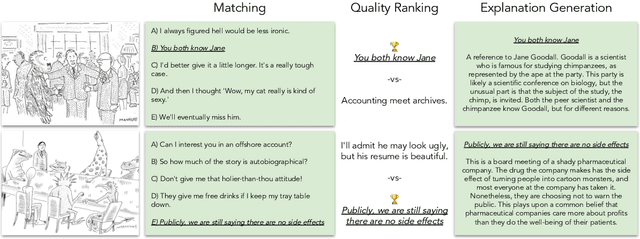
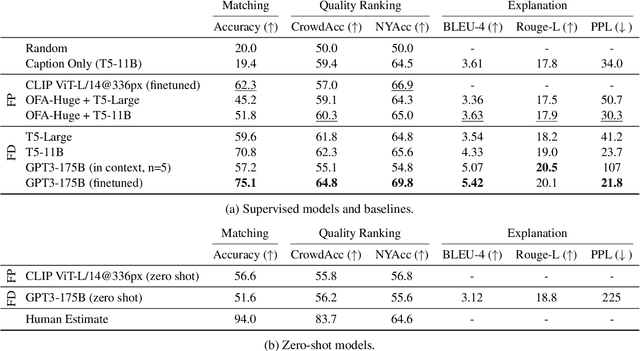
We challenge AI models to "demonstrate understanding" of the sophisticated multimodal humor of The New Yorker Caption Contest. Concretely, we develop three carefully circumscribed tasks for which it suffices (but is not necessary) to grasp potentially complex and unexpected relationships between image and caption, and similarly complex and unexpected allusions to the wide varieties of human experience; these are the hallmarks of a New Yorker-caliber cartoon. We investigate vision-and-language models that take as input the cartoon pixels and caption directly, as well as language-only models for which we circumvent image-processing by providing textual descriptions of the image. Even with the rich multifaceted annotations we provide for the cartoon images, we identify performance gaps between high-quality machine learning models (e.g., a fine-tuned, 175B parameter language model) and humans. We publicly release our corpora including annotations describing the image's locations/entities, what's unusual about the scene, and an explanation of the joke.
Understanding Few-Shot Commonsense Knowledge Models
Jan 01, 2021


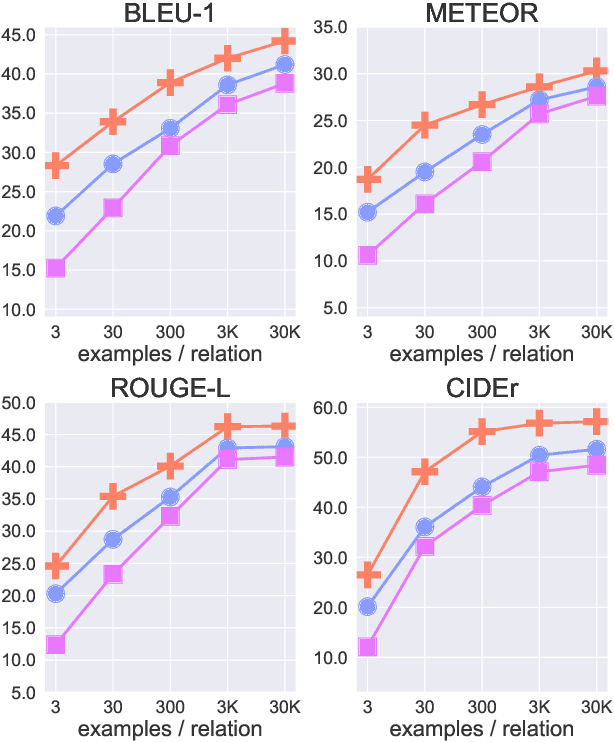
Providing natural language processing systems with commonsense knowledge is a critical challenge for achieving language understanding. Recently, commonsense knowledge models have emerged as a suitable approach for hypothesizing situation-relevant commonsense knowledge on-demand in natural language applications. However, these systems are limited by the fixed set of relations captured by schemas of the knowledge bases on which they're trained. To address this limitation, we investigate training commonsense knowledge models in a few-shot setting with limited tuples per commonsense relation in the graph. We perform five separate studies on different dimensions of few-shot commonsense knowledge learning, providing a roadmap on best practices for training these systems efficiently. Importantly, we find that human quality ratings for knowledge produced from a few-shot trained system can achieve performance within 6% of knowledge produced from fully supervised systems. This few-shot performance enables coverage of a wide breadth of relations in future commonsense systems.
Edited Media Understanding: Reasoning About Implications of Manipulated Images
Dec 08, 2020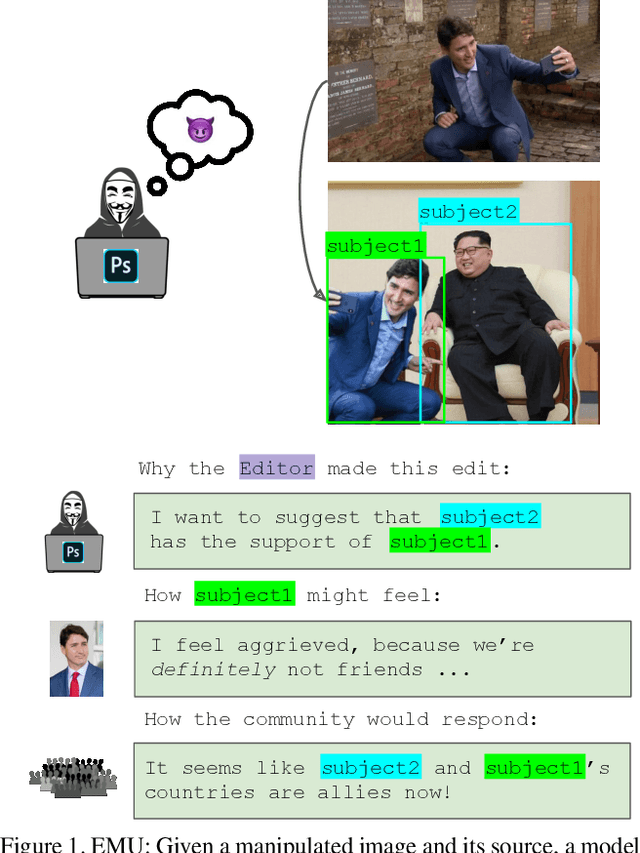

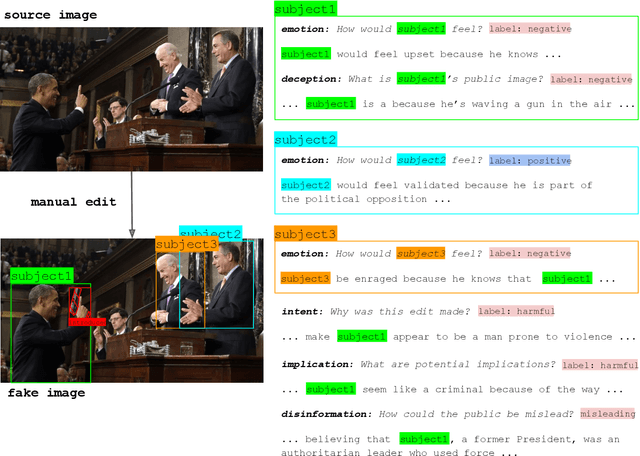
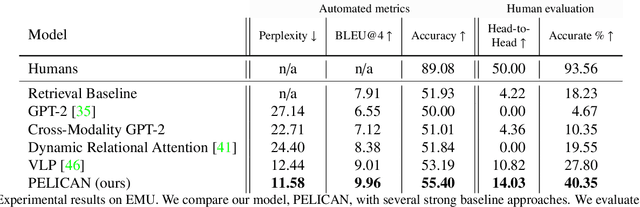
Multimodal disinformation, from `deepfakes' to simple edits that deceive, is an important societal problem. Yet at the same time, the vast majority of media edits are harmless -- such as a filtered vacation photo. The difference between this example, and harmful edits that spread disinformation, is one of intent. Recognizing and describing this intent is a major challenge for today's AI systems. We present the task of Edited Media Understanding, requiring models to answer open-ended questions that capture the intent and implications of an image edit. We introduce a dataset for our task, EMU, with 48k question-answer pairs written in rich natural language. We evaluate a wide variety of vision-and-language models for our task, and introduce a new model PELICAN, which builds upon recent progress in pretrained multimodal representations. Our model obtains promising results on our dataset, with humans rating its answers as accurate 40.35% of the time. At the same time, there is still much work to be done -- humans prefer human-annotated captions 93.56% of the time -- and we provide analysis that highlights areas for further progress.
COMET-ATOMIC 2020: On Symbolic and Neural Commonsense Knowledge Graphs
Oct 12, 2020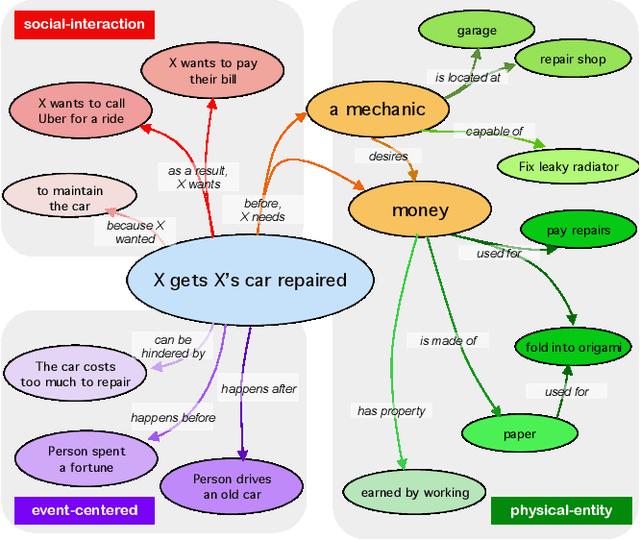

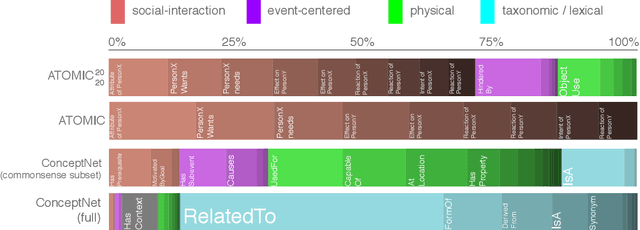
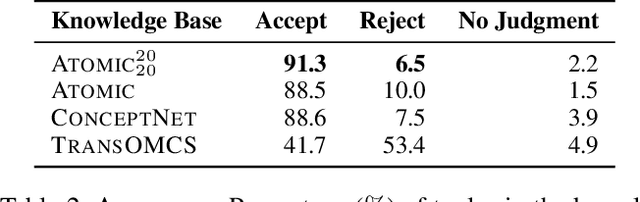
Recent years have brought about a renewed interest in commonsense representation and reasoning in the field of natural language understanding. The development of new commonsense knowledge graphs (CSKG) has been central to these advances as their diverse facts can be used and referenced by machine learning models for tackling new and challenging tasks. At the same time, there remain questions about the quality and coverage of these resources due to the massive scale required to comprehensively encompass general commonsense knowledge. In this work, we posit that manually constructed CSKGs will never achieve the coverage necessary to be applicable in all situations encountered by NLP agents. Therefore, we propose a new evaluation framework for testing the utility of KGs based on how effectively implicit knowledge representations can be learned from them. With this new goal, we propose ATOMIC 2020, a new CSKG of general-purpose commonsense knowledge containing knowledge that is not readily available in pretrained language models. We evaluate its properties in comparison with other leading CSKGs, performing the first large-scale pairwise study of commonsense knowledge resources. Next, we show that ATOMIC 2020 is better suited for training knowledge models that can generate accurate, representative knowledge for new, unseen entities and events. Finally, through human evaluation, we show that the few-shot performance of GPT-3 (175B parameters), while impressive, remains ~12 absolute points lower than a BART-based knowledge model trained on ATOMIC 2020 despite using over 430x fewer parameters.
BIG MOOD: Relating Transformers to Explicit Commonsense Knowledge
Oct 17, 2019


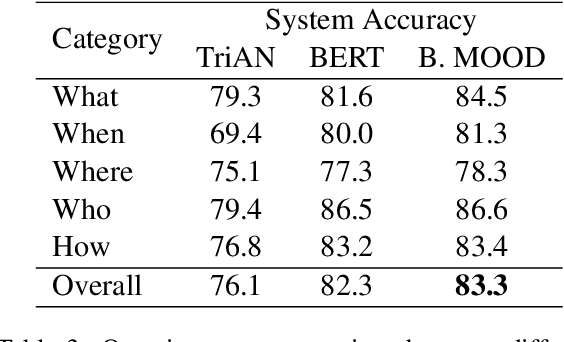
We introduce a simple yet effective method of integrating contextual embeddings with commonsense graph embeddings, dubbed BERT Infused Graphs: Matching Over Other embeDdings. First, we introduce a preprocessing method to improve the speed of querying knowledge bases. Then, we develop a method of creating knowledge embeddings from each knowledge base. We introduce a method of aligning tokens between two misaligned tokenization methods. Finally, we contribute a method of contextualizing BERT after combining with knowledge base embeddings. We also show BERTs tendency to correct lower accuracy question types. Our model achieves a higher accuracy than BERT, and we score fifth on the official leaderboard of the shared task and score the highest without any additional language model pretraining.