 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Few-Shot Commonsense Knowledge Models
Paper and Code



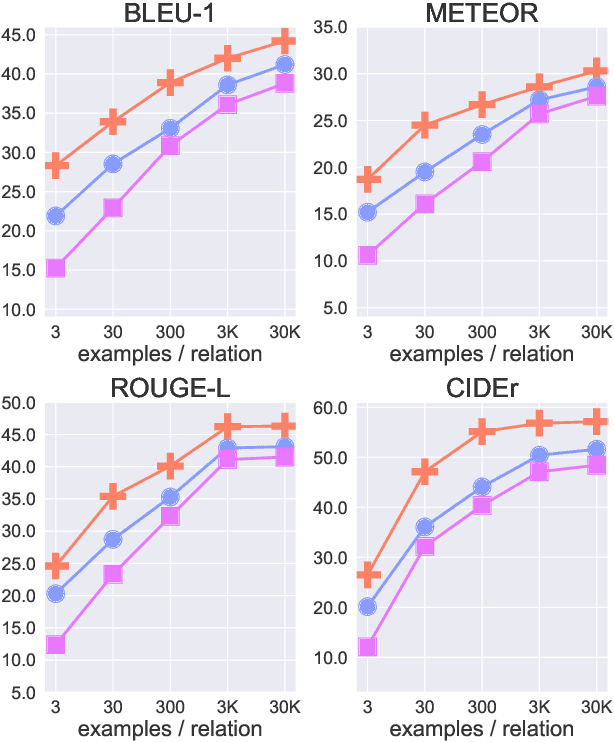
Providing natural language processing systems with commonsense knowledge is a critical challenge for achieving language understanding. Recently, commonsense knowledge models have emerged as a suitable approach for hypothesizing situation-relevant commonsense knowledge on-demand in natural language applications. However, these systems are limited by the fixed set of relations captured by schemas of the knowledge bases on which they're trained. To address this limitation, we investigate training commonsense knowledge models in a few-shot setting with limited tuples per commonsense relation in the graph. We perform five separate studies on different dimensions of few-shot commonsense knowledge learning, providing a roadmap on best practices for training these systems efficiently. Importantly, we find that human quality ratings for knowledge produced from a few-shot trained system can achieve performance within 6% of knowledge produced from fully supervised systems. This few-shot performance enables coverage of a wide breadth of relations in future commonsense systems.