 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking the Limits of Knowledge Propagation: How LLMs Fail at Multi-Step Reasoning with Conflicting Knowledge
Jan 21, 2026A common solution for mitigating outdated or incorrect information in Large Language Models (LLMs) is to provide updated facts in-context or through knowledge editing. However, these methods introduce knowledge conflicts when the knowledge update fails to overwrite the model's parametric knowledge, which propagate to faulty reasoning. Current benchmarks for this problem, however, largely focus only on single knowledge updates and fact recall without evaluating how these updates affect downstream reasoning. In this work, we introduce TRACK (Testing Reasoning Amid Conflicting Knowledge), a new benchmark for studying how LLMs propagate new knowledge through multi-step reasoning when it conflicts with the model's initial parametric knowledge. Spanning three reasoning-intensive scenarios (WIKI, CODE, and MATH), TRACK introduces multiple, realistic conflicts to mirror real-world complexity. Our results on TRACK reveal that providing updated facts to models for reasoning can worsen performance compared to providing no updated facts to a model, and that this performance degradation exacerbates as more updated facts are provided. We show this failure stems from both inability to faithfully integrate updated facts, but also flawed reasoning even when knowledge is integrated. TRACK provides a rigorous new benchmark to measure and guide future progress on propagating conflicting knowledge in multi-step reasoning.
Revisiting Multilingual Data Mixtures in Language Model Pretraining
Oct 29, 2025The impact of different multilingual data mixtures in pretraining large language models (LLMs) has been a topic of ongoing debate, often raising concerns about potential trade-offs between language coverage and model performance (i.e., the curse of multilinguality). In this work, we investigate these assumptions by training 1.1B and 3B parameter LLMs on diverse multilingual corpora, varying the number of languages from 25 to 400. Our study challenges common beliefs surrounding multilingual training. First, we find that combining English and multilingual data does not necessarily degrade the in-language performance of either group, provided that languages have a sufficient number of tokens included in the pretraining corpus. Second, we observe that using English as a pivot language (i.e., a high-resource language that serves as a catalyst for multilingual generalization) yields benefits across language families, and contrary to expectations, selecting a pivot language from within a specific family does not consistently improve performance for languages within that family. Lastly, we do not observe a significant "curse of multilinguality" as the number of training languages increases in models at this scale. Our findings suggest that multilingual data, when balanced appropriately, can enhance language model capabilities without compromising performance, even in low-resource settings
CAVE: Detecting and Explaining Commonsense Anomalies in Visual Environments
Oct 29, 2025Humans can naturally identify, reason about, and explain anomalies in their environment. In computer vision, this long-standing challenge remains limited to industrial defects or unrealistic, synthetically generated anomalies, failing to capture the richness and unpredictability of real-world anomalies. In this work, we introduce CAVE, the first benchmark of real-world visual anomalies. CAVE supports three open-ended tasks: anomaly description, explanation, and justification; with fine-grained annotations for visual grounding and categorizing anomalies based on their visual manifestations, their complexity, severity, and commonness. These annotations draw inspiration from cognitive science research on how humans identify and resolve anomalies, providing a comprehensive framework for evaluating Vision-Language Models (VLMs) in detecting and understanding anomalies. We show that state-of-the-art VLMs struggle with visual anomaly perception and commonsense reasoning, even with advanced prompting strategies. By offering a realistic and cognitively grounded benchmark, CAVE serves as a valuable resource for advancing research in anomaly detection and commonsense reasoning in VLMs.
Apertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
Crosscoding Through Time: Tracking Emergence & Consolidation Of Linguistic Representations Throughout LLM Pretraining
Sep 05, 2025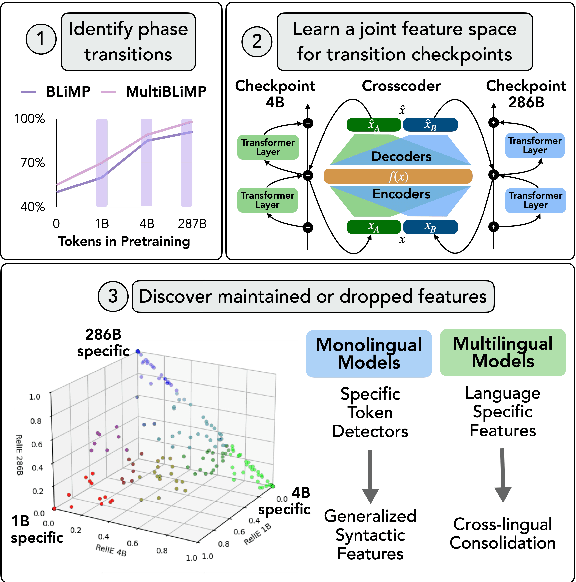
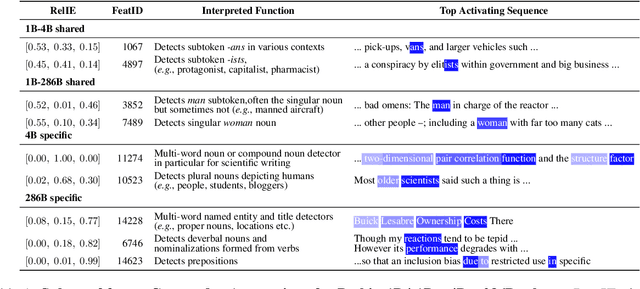
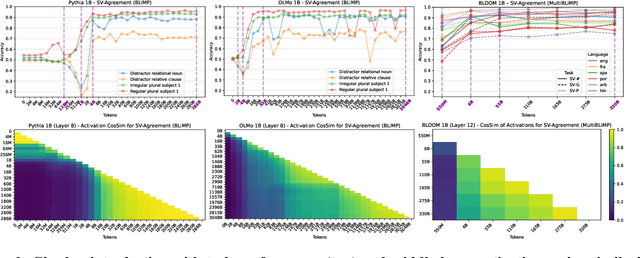

Large language models (LLMs) learn non-trivial abstractions during pretraining, like detecting irregular plural noun subjects. However, it is not well understood when and how specific linguistic abilities emerge as traditional evaluation methods such as benchmarking fail to reveal how models acquire concepts and capabilities. To bridge this gap and better understand model training at the concept level, we use sparse crosscoders to discover and align features across model checkpoints. Using this approach, we track the evolution of linguistic features during pretraining. We train crosscoders between open-sourced checkpoint triplets with significant performance and representation shifts, and introduce a novel metric, Relative Indirect Effects (RelIE), to trace training stages at which individual features become causally important for task performance. We show that crosscoders can detect feature emergence, maintenance, and discontinuation during pretraining. Our approach is architecture-agnostic and scalable, offering a promising path toward more interpretable and fine-grained analysis of representation learning throughout pretraining.
Parity-Aware Byte-Pair Encoding: Improving Cross-lingual Fairness in Tokenization
Aug 06, 2025



Tokenization is the first -- and often least scrutinized -- step of most NLP pipelines. Standard algorithms for learning tokenizers rely on frequency-based objectives, which favor languages dominant in the training data and consequently leave lower-resource languages with tokenizations that are disproportionately longer, morphologically implausible, or even riddled with <UNK> placeholders. This phenomenon ultimately amplifies computational and financial inequalities between users from different language backgrounds. To remedy this, we introduce Parity-aware Byte Pair Encoding (BPE), a variant of the widely-used BPE algorithm. At every merge step, Parity-aware BPE maximizes the compression gain of the currently worst-compressed language, trading a small amount of global compression for cross-lingual parity. We find empirically that Parity-aware BPE leads to more equitable token counts across languages, with negligible impact on global compression rate and no substantial effect on language-model performance in downstream tasks.
GeoExplorer: Active Geo-localization with Curiosity-Driven Exploration
Jul 31, 2025Active Geo-localization (AGL) is the task of localizing a goal, represented in various modalities (e.g., aerial images, ground-level images, or text), within a predefined search area. Current methods approach AGL as a goal-reaching reinforcement learning (RL) problem with a distance-based reward. They localize the goal by implicitly learning to minimize the relative distance from it. However, when distance estimation becomes challenging or when encountering unseen targets and environments, the agent exhibits reduced robustness and generalization ability due to the less reliable exploration strategy learned during training. In this paper, we propose GeoExplorer, an AGL agent that incorporates curiosity-driven exploration through intrinsic rewards. Unlike distance-based rewards, our curiosity-driven reward is goal-agnostic, enabling robust, diverse, and contextually relevant exploration based on effective environment modeling. These capabilities have been proven through extensive experiments across four AGL benchmarks, demonstrating the effectiveness and generalization ability of GeoExplorer in diverse settings, particularly in localizing unfamiliar targets and environments.
PERK: Long-Context Reasoning as Parameter-Efficient Test-Time Learning
Jul 08, 2025Long-context reasoning requires accurately identifying relevant information in extensive, noisy input contexts. Previous research shows that using test-time learning to encode context directly into model parameters can effectively enable reasoning over noisy information. However, meta-learning methods for enabling test-time learning are prohibitively memory-intensive, preventing their application to long context settings. In this work, we propose PERK (Parameter Efficient Reasoning over Knowledge), a scalable approach for learning to encode long input contexts using gradient updates to a lightweight model adapter at test time. Specifically, PERK employs two nested optimization loops in a meta-training phase. The inner loop rapidly encodes contexts into a low-rank adapter (LoRA) that serves as a parameter-efficient memory module for the base model. Concurrently, the outer loop learns to use the updated adapter to accurately recall and reason over relevant information from the encoded long context. Our evaluations on several long-context reasoning tasks show that PERK significantly outperforms the standard prompt-based long-context baseline, achieving average absolute performance gains of up to 90% for smaller models (GPT-2) and up to 27% for our largest evaluated model, Qwen-2.5-0.5B. In general, PERK is more robust to reasoning complexity, length extrapolation, and the locations of relevant information in contexts. Finally, we show that while PERK is memory-intensive during training, it scales more efficiently at inference time than prompt-based long-context inference.
ConLID: Supervised Contrastive Learning for Low-Resource Language Identification
Jun 18, 2025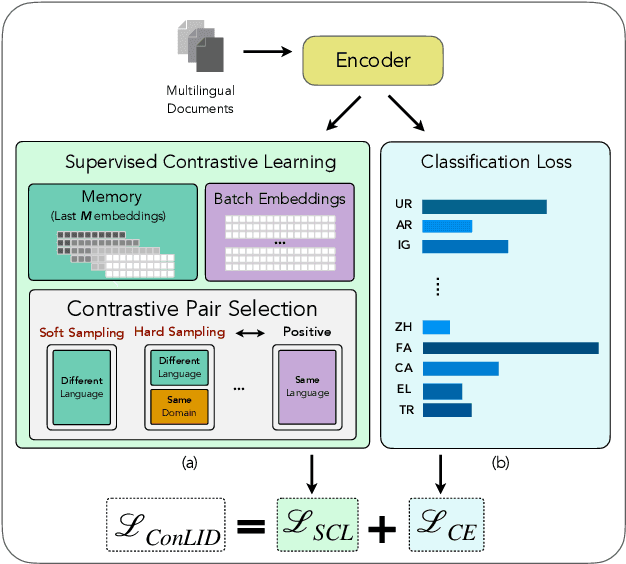
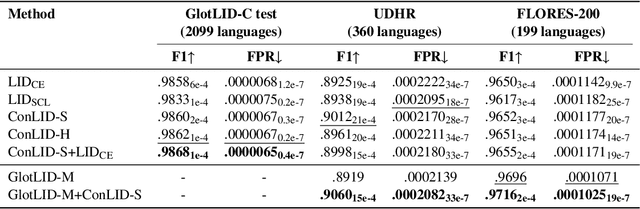

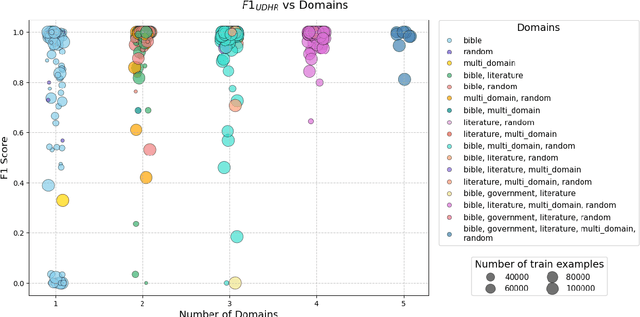
Language identification (LID) is a critical step in curating multilingual LLM pretraining corpora from web crawls. While many studies on LID model training focus on collecting diverse training data to improve performance, low-resource languages -- often limited to single-domain data, such as the Bible -- continue to perform poorly. To resolve these class imbalance and bias issues, we propose a novel supervised contrastive learning (SCL) approach to learn domain-invariant representations for low-resource languages. Through an extensive analysis, we show that our approach improves LID performance on out-of-domain data for low-resource languages by 3.2%, demonstrating its effectiveness in enhancing LID models.
Mixture of Cognitive Reasoners: Modular Reasoning with Brain-Like Specialization
Jun 16, 2025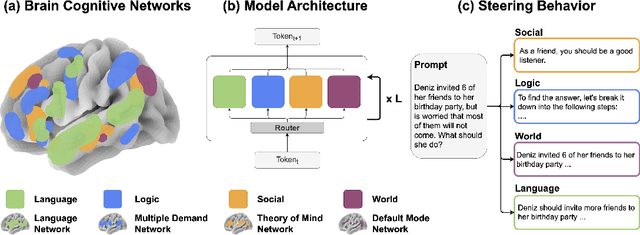
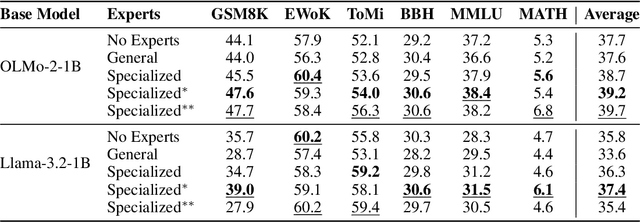
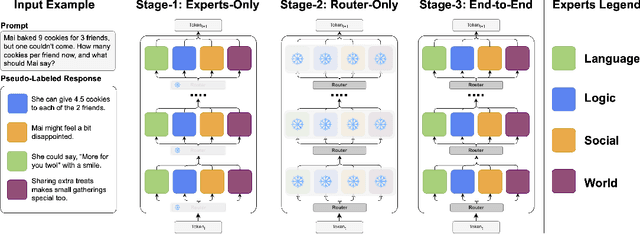
Human intelligence emerges from the interaction of specialized brain networks, each dedicated to distinct cognitive functions such as language processing, logical reasoning, social understanding, and memory retrieval. Inspired by this biological observation, we introduce the Mixture of Cognitive Reasoners (MiCRo) architecture and training paradigm: a modular transformer-based language model with a training curriculum that encourages the emergence of functional specialization among different modules. Inspired by studies in neuroscience, we partition the layers of a pretrained transformer model into four expert modules, each corresponding to a well-studied cognitive brain network. Our Brain-Like model has three key benefits over the state of the art: First, the specialized experts are highly interpretable and functionally critical, where removing a module significantly impairs performance on domain-relevant benchmarks. Second, our model outperforms comparable baselines that lack specialization on seven reasoning benchmarks. And third, the model's behavior can be steered at inference time by selectively emphasizing certain expert modules (e.g., favoring social over logical reasoning), enabling fine-grained control over the style of its response. Our findings suggest that biologically inspired inductive biases involved in human cognition lead to significant modeling gains in interpretability, performance, and controllability.