 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$p1$: Better Prompt Optimization with Fewer Prompts
Apr 09, 2026Prompt optimization improves language models without updating their weights by searching for a better system prompt, but its effectiveness varies widely across tasks. We study what makes a task amenable to prompt optimization. We show that the reward variance across different system prompts can be decomposed into two components: variance among responses, which captures generation stochasticity, and variance among system prompts, which captures differences in system prompt quality. Prompt optimization succeeds when variance among system prompts is sufficiently large, but fails when variance among responses dominates the variance of the system prompts. Surprisingly, we further show that scaling to more user prompts can hurt optimization by reducing variance among system prompts, especially on heterogeneous datasets where different user prompts favor different system prompts. Motivated by this insight, we propose $p1$, a simple user prompt filtering method that selects a small subset of user prompts with high variance across candidate system prompts. This subset of user prompts allows one to distinguish a good system prompt from a bad one, making system optimization easier. Experiments on reasoning benchmarks show that $p1$ substantially improves prompt optimization over training on the full dataset and outperforms strong baselines such as GEPA. Notably, training on only two prompts from AIME 24 yields a system prompt that generalizes well to other reasoning benchmarks.
LLMs Can Learn to Reason Via Off-Policy RL
Feb 22, 2026Reinforcement learning (RL) approaches for Large Language Models (LLMs) frequently use on-policy algorithms, such as PPO or GRPO. However, policy lag from distributed training architectures and differences between the training and inference policies break this assumption, making the data off-policy by design. To rectify this, prior work has focused on making this off-policy data appear more on-policy, either via importance sampling (IS), or by more closely aligning the training and inference policies by explicitly modifying the inference engine. In this work, we embrace off-policyness and propose a novel off-policy RL algorithm that does not require these modifications: Optimal Advantage-based Policy Optimization with Lagged Inference policy (OAPL). We show that OAPL outperforms GRPO with importance sampling on competition math benchmarks, and can match the performance of a publicly available coding model, DeepCoder, on LiveCodeBench, while using 3x fewer generations during training. We further empirically demonstrate that models trained via OAPL have improved test time scaling under the Pass@k metric. OAPL allows for efficient, effective post-training even with lags of more than 400 gradient steps between the training and inference policies, 100x more off-policy than prior approaches.
Accelerating RL for LLM Reasoning with Optimal Advantage Regression
May 27, 2025Reinforcement learning (RL) has emerged as a powerful tool for fine-tuning large language models (LLMs) to improve complex reasoning abilities. However, state-of-the-art policy optimization methods often suffer from high computational overhead and memory consumption, primarily due to the need for multiple generations per prompt and the reliance on critic networks or advantage estimates of the current policy. In this paper, we propose $A$*-PO, a novel two-stage policy optimization framework that directly approximates the optimal advantage function and enables efficient training of LLMs for reasoning tasks. In the first stage, we leverage offline sampling from a reference policy to estimate the optimal value function $V$*, eliminating the need for costly online value estimation. In the second stage, we perform on-policy updates using a simple least-squares regression loss with only a single generation per prompt. Theoretically, we establish performance guarantees and prove that the KL-regularized RL objective can be optimized without requiring complex exploration strategies. Empirically, $A$*-PO achieves competitive performance across a wide range of mathematical reasoning benchmarks, while reducing training time by up to 2$\times$ and peak memory usage by over 30% compared to PPO, GRPO, and REBEL. Implementation of $A$*-PO can be found at https://github.com/ZhaolinGao/A-PO.
Value-Guided Search for Efficient Chain-of-Thought Reasoning
May 23, 2025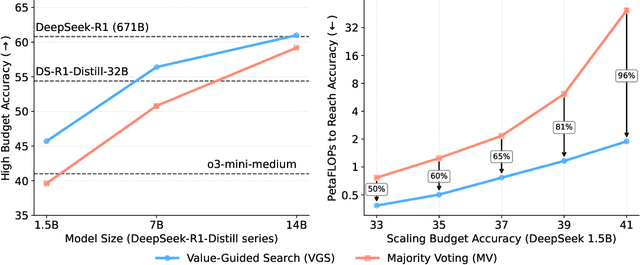

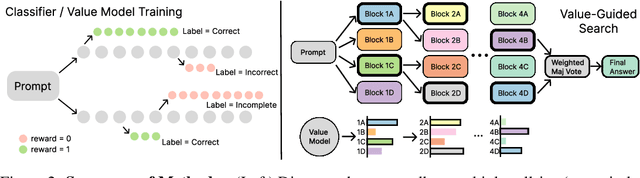
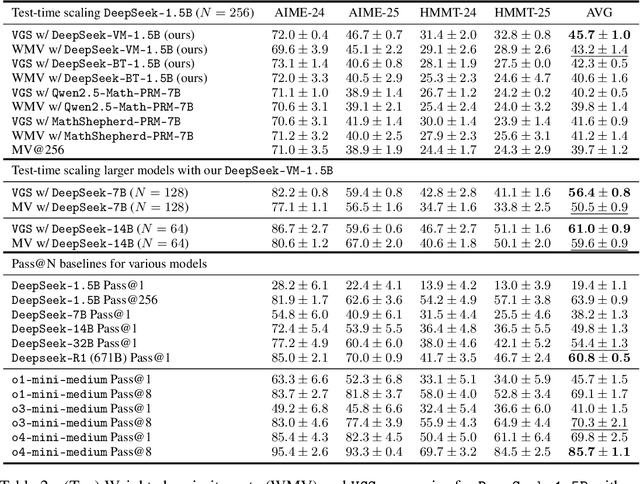
In this paper, we propose a simple and efficient method for value model training on long-context reasoning traces. Compared to existing process reward models (PRMs), our method does not require a fine-grained notion of "step," which is difficult to define for long-context reasoning models. By collecting a dataset of 2.5 million reasoning traces, we train a 1.5B token-level value model and apply it to DeepSeek models for improved performance with test-time compute scaling. We find that block-wise value-guided search (VGS) with a final weighted majority vote achieves better test-time scaling than standard methods such as majority voting or best-of-n. With an inference budget of 64 generations, VGS with DeepSeek-R1-Distill-1.5B achieves an average accuracy of 45.7% across four competition math benchmarks (AIME 2024 & 2025, HMMT Feb 2024 & 2025), reaching parity with o3-mini-medium. Moreover, VGS significantly reduces the inference FLOPs required to achieve the same performance of majority voting. Our dataset, model and codebase are open-sourced.
$Q\sharp$: Provably Optimal Distributional RL for LLM Post-Training
Feb 27, 2025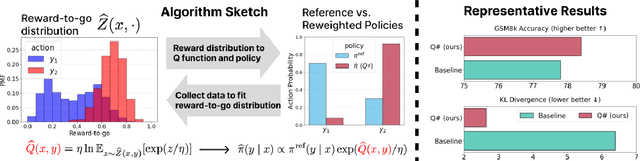



Reinforcement learning (RL) post-training is crucial for LLM alignment and reasoning, but existing policy-based methods, such as PPO and DPO, can fall short of fixing shortcuts inherited from pre-training. In this work, we introduce $Q\sharp$, a value-based algorithm for KL-regularized RL that guides the reference policy using the optimal regularized $Q$ function. We propose to learn the optimal $Q$ function using distributional RL on an aggregated online dataset. Unlike prior value-based baselines that guide the model using unregularized $Q$-values, our method is theoretically principled and provably learns the optimal policy for the KL-regularized RL problem. Empirically, $Q\sharp$ outperforms prior baselines in math reasoning benchmarks while maintaining a smaller KL divergence to the reference policy. Theoretically, we establish a reduction from KL-regularized RL to no-regret online learning, providing the first bounds for deterministic MDPs under only realizability. Thanks to distributional RL, our bounds are also variance-dependent and converge faster when the reference policy has small variance. In sum, our results highlight $Q\sharp$ as an effective approach for post-training LLMs, offering both improved performance and theoretical guarantees. The code can be found at https://github.com/jinpz/q_sharp.
Diffusing States and Matching Scores: A New Framework for Imitation Learning
Oct 17, 2024Adversarial Imitation Learning is traditionally framed as a two-player zero-sum game between a learner and an adversarially chosen cost function, and can therefore be thought of as the sequential generalization of a Generative Adversarial Network (GAN). A prominent example of this framework is Generative Adversarial Imitation Learning (GAIL). However, in recent years, diffusion models have emerged as a non-adversarial alternative to GANs that merely require training a score function via regression, yet produce generations of a higher quality. In response, we investigate how to lift insights from diffusion modeling to the sequential setting. We propose diffusing states and performing score-matching along diffused states to measure the discrepancy between the expert's and learner's states. Thus, our approach only requires training score functions to predict noises via standard regression, making it significantly easier and more stable to train than adversarial methods. Theoretically, we prove first- and second-order instance-dependent bounds with linear scaling in the horizon, proving that our approach avoids the compounding errors that stymie offline approaches to imitation learning. Empirically, we show our approach outperforms GAN-style imitation learning baselines across various continuous control problems, including complex tasks like controlling humanoids to walk, sit, and crawl.
LLMs Are In-Context Reinforcement Learners
Oct 07, 2024



Large Language Models (LLMs) can learn new tasks through in-context supervised learning (i.e., ICL). This work studies if this ability extends to in-context reinforcement learning (ICRL), where models are not given gold labels in context, but only their past predictions and rewards. We show that a naive application of ICRL fails miserably, and identify the root cause as a fundamental deficiency at exploration, which leads to quick model degeneration. We propose an algorithm to address this deficiency by increasing test-time compute, as well as a compute-bound approximation. We use several challenging classification tasks to empirically show that our ICRL algorithms lead to effective learning from rewards alone, and analyze the characteristics of this ability and our methods. Overall, our results reveal remarkable ICRL abilities in LLMs.
Regressing the Relative Future: Efficient Policy Optimization for Multi-turn RLHF
Oct 06, 2024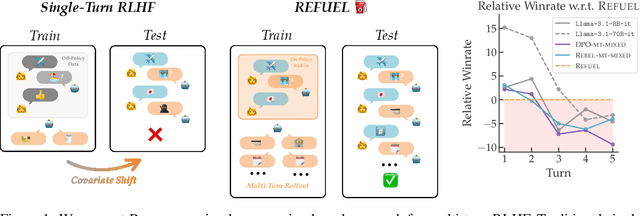
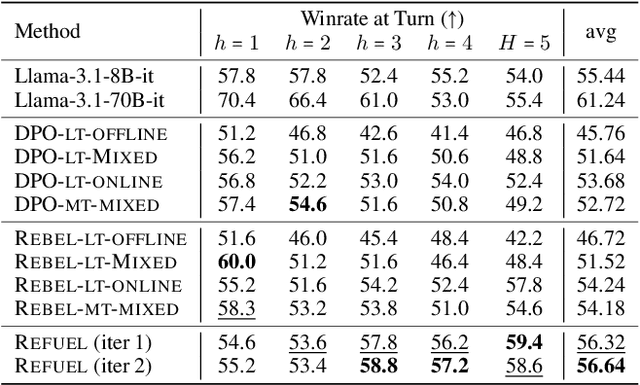
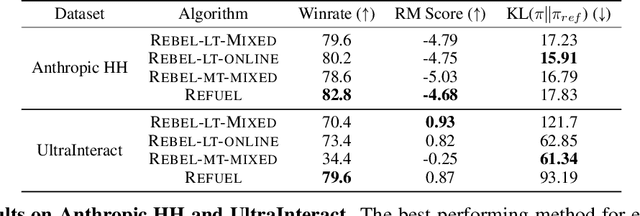
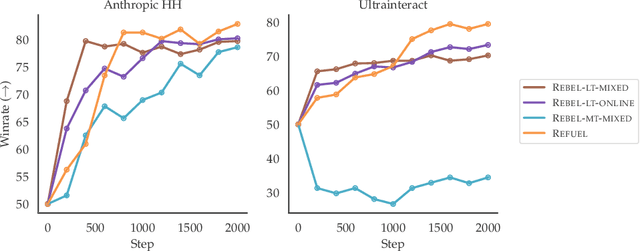
Large Language Models (LLMs) have achieved remarkable success at tasks like summarization that involve a single turn of interaction. However, they can still struggle with multi-turn tasks like dialogue that require long-term planning. Previous works on multi-turn dialogue extend single-turn reinforcement learning from human feedback (RLHF) methods to the multi-turn setting by treating all prior dialogue turns as a long context. Such approaches suffer from covariate shift: the conversations in the training set have previous turns generated by some reference policy, which means that low training error may not necessarily correspond to good performance when the learner is actually in the conversation loop. In response, we introduce REgressing the RELative FUture (REFUEL), an efficient policy optimization approach designed to address multi-turn RLHF in LLMs. REFUEL employs a single model to estimate $Q$-values and trains on self-generated data, addressing the covariate shift issue. REFUEL frames the multi-turn RLHF problem as a sequence of regression tasks on iteratively collected datasets, enabling ease of implementation. Theoretically, we prove that REFUEL can match the performance of any policy covered by the training set. Empirically, we evaluate our algorithm by using Llama-3.1-70B-it to simulate a user in conversation with our model. REFUEL consistently outperforms state-of-the-art methods such as DPO and REBEL across various settings. Furthermore, despite having only 8 billion parameters, Llama-3-8B-it fine-tuned with REFUEL outperforms Llama-3.1-70B-it on long multi-turn dialogues. Implementation of REFUEL can be found at https://github.com/ZhaolinGao/REFUEL/, and models trained by REFUEL can be found at https://huggingface.co/Cornell-AGI.
REBEL: Reinforcement Learning via Regressing Relative Rewards
Apr 25, 2024While originally developed for continuous control problems, Proximal Policy Optimization (PPO) has emerged as the work-horse of a variety of reinforcement learning (RL) applications including the fine-tuning of generative models. Unfortunately, PPO requires multiple heuristics to enable stable convergence (e.g. value networks, clipping) and is notorious for its sensitivity to the precise implementation of these components. In response, we take a step back and ask what a minimalist RL algorithm for the era of generative models would look like. We propose REBEL, an algorithm that cleanly reduces the problem of policy optimization to regressing the relative rewards via a direct policy parameterization between two completions to a prompt, enabling strikingly lightweight implementation. In theory, we prove that fundamental RL algorithms like Natural Policy Gradient can be seen as variants of REBEL, which allows us to match the strongest known theoretical guarantees in terms of convergence and sample complexity in the RL literature. REBEL can also cleanly incorporate offline data and handle the intransitive preferences we frequently see in practice. Empirically, we find that REBEL provides a unified approach to language modeling and image generation with stronger or similar performance as PPO and DPO, all while being simpler to implement and more computationally tractable than PPO.
Dataset Reset Policy Optimization for RLHF
Apr 15, 2024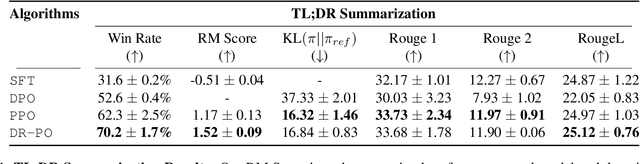
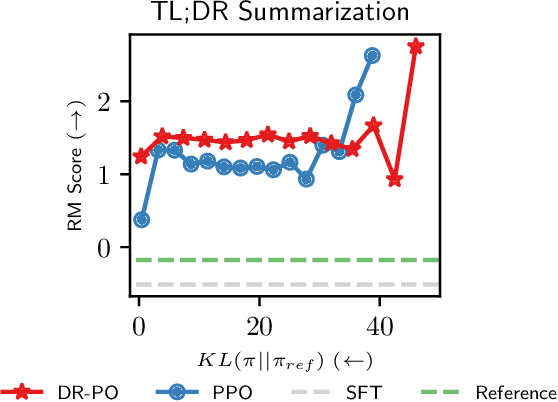


Reinforcement Learning (RL) from Human Preference-based feedback is a popular paradigm for fine-tuning generative models, which has produced impressive models such as GPT-4 and Claude3 Opus. This framework often consists of two steps: learning a reward model from an offline preference dataset followed by running online RL to optimize the learned reward model. In this work, leveraging the idea of reset, we propose a new RLHF algorithm with provable guarantees. Motivated by the fact that offline preference dataset provides informative states (i.e., data that is preferred by the labelers), our new algorithm, Dataset Reset Policy Optimization (DR-PO), integrates the existing offline preference dataset into the online policy training procedure via dataset reset: it directly resets the policy optimizer to the states in the offline dataset, instead of always starting from the initial state distribution. In theory, we show that DR-PO learns to perform at least as good as any policy that is covered by the offline dataset under general function approximation with finite sample complexity. In experiments, we demonstrate that on both the TL;DR summarization and the Anthropic Helpful Harmful (HH) dataset, the generation from DR-PO is better than that from Proximal Policy Optimization (PPO) and Direction Preference Optimization (DPO), under the metric of GPT4 win-rate. Code for this work can be found at https://github.com/Cornell-RL/drpo.