 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegressing the Relative Future: Efficient Policy Optimization for Multi-turn RLHF
Oct 06, 2024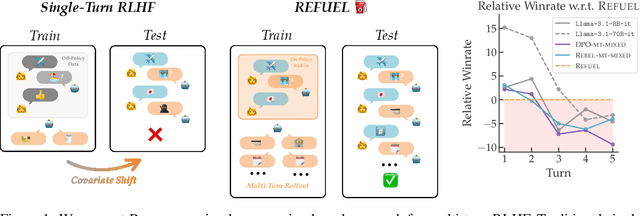
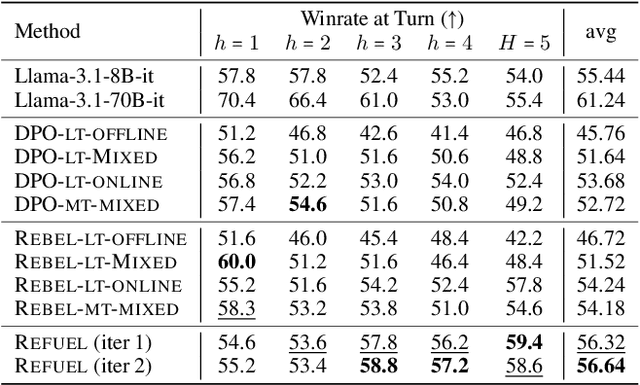
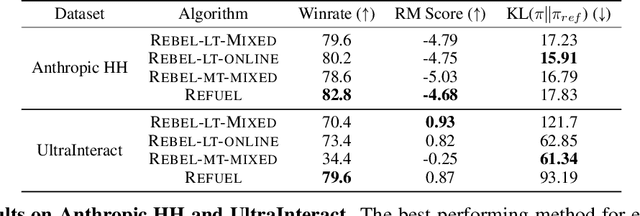
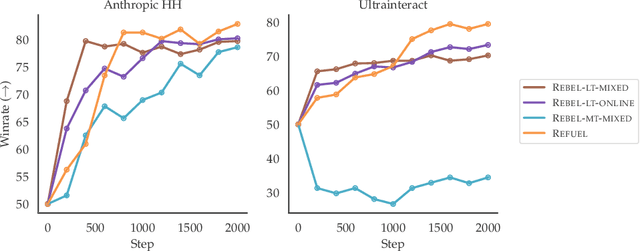
Large Language Models (LLMs) have achieved remarkable success at tasks like summarization that involve a single turn of interaction. However, they can still struggle with multi-turn tasks like dialogue that require long-term planning. Previous works on multi-turn dialogue extend single-turn reinforcement learning from human feedback (RLHF) methods to the multi-turn setting by treating all prior dialogue turns as a long context. Such approaches suffer from covariate shift: the conversations in the training set have previous turns generated by some reference policy, which means that low training error may not necessarily correspond to good performance when the learner is actually in the conversation loop. In response, we introduce REgressing the RELative FUture (REFUEL), an efficient policy optimization approach designed to address multi-turn RLHF in LLMs. REFUEL employs a single model to estimate $Q$-values and trains on self-generated data, addressing the covariate shift issue. REFUEL frames the multi-turn RLHF problem as a sequence of regression tasks on iteratively collected datasets, enabling ease of implementation. Theoretically, we prove that REFUEL can match the performance of any policy covered by the training set. Empirically, we evaluate our algorithm by using Llama-3.1-70B-it to simulate a user in conversation with our model. REFUEL consistently outperforms state-of-the-art methods such as DPO and REBEL across various settings. Furthermore, despite having only 8 billion parameters, Llama-3-8B-it fine-tuned with REFUEL outperforms Llama-3.1-70B-it on long multi-turn dialogues. Implementation of REFUEL can be found at https://github.com/ZhaolinGao/REFUEL/, and models trained by REFUEL can be found at https://huggingface.co/Cornell-AGI.
Critique-out-Loud Reward Models
Aug 21, 2024Traditionally, reward models used for reinforcement learning from human feedback (RLHF) are trained to directly predict preference scores without leveraging the generation capabilities of the underlying large language model (LLM). This limits the capabilities of reward models as they must reason implicitly about the quality of a response, i.e., preference modeling must be performed in a single forward pass through the model. To enable reward models to reason explicitly about the quality of a response, we introduce Critique-out-Loud (CLoud) reward models. CLoud reward models operate by first generating a natural language critique of the assistant's response that is then used to predict a scalar reward for the quality of the response. We demonstrate the success of CLoud reward models for both Llama-3-8B and 70B base models: compared to classic reward models CLoud reward models improve pairwise preference classification accuracy on RewardBench by 4.65 and 5.84 percentage points for the 8B and 70B base models respectively. Furthermore, CLoud reward models lead to a Pareto improvement for win rate on ArenaHard when used as the scoring model for Best-of-N. Finally, we explore how to exploit the dynamic inference compute capabilities of CLoud reward models by performing self-consistency decoding for reward prediction.
REBEL: Reinforcement Learning via Regressing Relative Rewards
Apr 25, 2024While originally developed for continuous control problems, Proximal Policy Optimization (PPO) has emerged as the work-horse of a variety of reinforcement learning (RL) applications including the fine-tuning of generative models. Unfortunately, PPO requires multiple heuristics to enable stable convergence (e.g. value networks, clipping) and is notorious for its sensitivity to the precise implementation of these components. In response, we take a step back and ask what a minimalist RL algorithm for the era of generative models would look like. We propose REBEL, an algorithm that cleanly reduces the problem of policy optimization to regressing the relative rewards via a direct policy parameterization between two completions to a prompt, enabling strikingly lightweight implementation. In theory, we prove that fundamental RL algorithms like Natural Policy Gradient can be seen as variants of REBEL, which allows us to match the strongest known theoretical guarantees in terms of convergence and sample complexity in the RL literature. REBEL can also cleanly incorporate offline data and handle the intransitive preferences we frequently see in practice. Empirically, we find that REBEL provides a unified approach to language modeling and image generation with stronger or similar performance as PPO and DPO, all while being simpler to implement and more computationally tractable than PPO.
Dataset Reset Policy Optimization for RLHF
Apr 15, 2024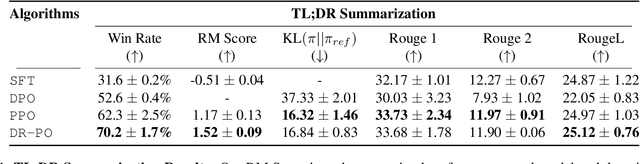
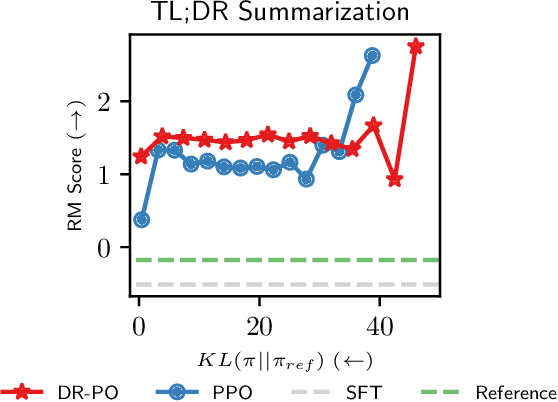


Reinforcement Learning (RL) from Human Preference-based feedback is a popular paradigm for fine-tuning generative models, which has produced impressive models such as GPT-4 and Claude3 Opus. This framework often consists of two steps: learning a reward model from an offline preference dataset followed by running online RL to optimize the learned reward model. In this work, leveraging the idea of reset, we propose a new RLHF algorithm with provable guarantees. Motivated by the fact that offline preference dataset provides informative states (i.e., data that is preferred by the labelers), our new algorithm, Dataset Reset Policy Optimization (DR-PO), integrates the existing offline preference dataset into the online policy training procedure via dataset reset: it directly resets the policy optimizer to the states in the offline dataset, instead of always starting from the initial state distribution. In theory, we show that DR-PO learns to perform at least as good as any policy that is covered by the offline dataset under general function approximation with finite sample complexity. In experiments, we demonstrate that on both the TL;DR summarization and the Anthropic Helpful Harmful (HH) dataset, the generation from DR-PO is better than that from Proximal Policy Optimization (PPO) and Direction Preference Optimization (DPO), under the metric of GPT4 win-rate. Code for this work can be found at https://github.com/Cornell-RL/drpo.
Adversarial Imitation Learning via Boosting
Apr 12, 2024
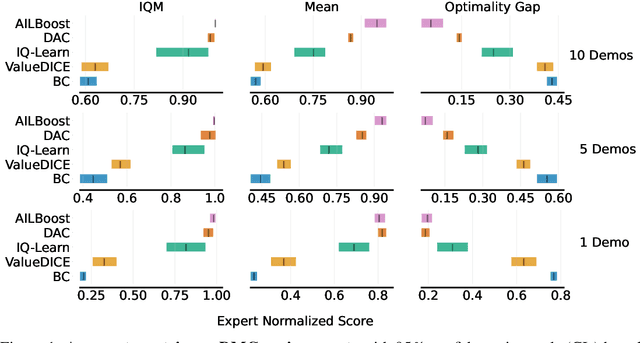
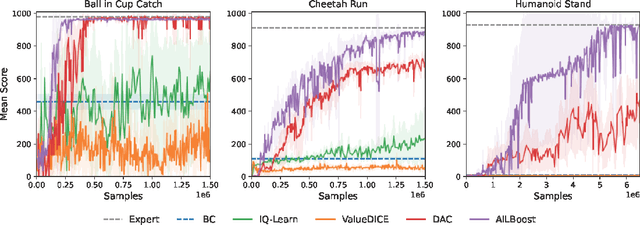

Adversarial imitation learning (AIL) has stood out as a dominant framework across various imitation learning (IL) applications, with Discriminator Actor Critic (DAC) (Kostrikov et al.,, 2019) demonstrating the effectiveness of off-policy learning algorithms in improving sample efficiency and scalability to higher-dimensional observations. Despite DAC's empirical success, the original AIL objective is on-policy and DAC's ad-hoc application of off-policy training does not guarantee successful imitation (Kostrikov et al., 2019; 2020). Follow-up work such as ValueDICE (Kostrikov et al., 2020) tackles this issue by deriving a fully off-policy AIL objective. Instead in this work, we develop a novel and principled AIL algorithm via the framework of boosting. Like boosting, our new algorithm, AILBoost, maintains an ensemble of properly weighted weak learners (i.e., policies) and trains a discriminator that witnesses the maximum discrepancy between the distributions of the ensemble and the expert policy. We maintain a weighted replay buffer to represent the state-action distribution induced by the ensemble, allowing us to train discriminators using the entire data collected so far. In the weighted replay buffer, the contribution of the data from older policies are properly discounted with the weight computed based on the boosting framework. Empirically, we evaluate our algorithm on both controller state-based and pixel-based environments from the DeepMind Control Suite. AILBoost outperforms DAC on both types of environments, demonstrating the benefit of properly weighting replay buffer data for off-policy training. On state-based environments, DAC outperforms ValueDICE and IQ-Learn (Gary et al., 2021), achieving competitive performance with as little as one expert trajectory.
RL for Consistency Models: Faster Reward Guided Text-to-Image Generation
Mar 25, 2024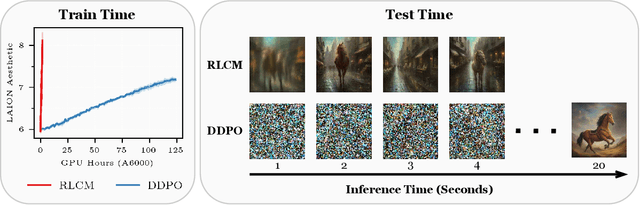
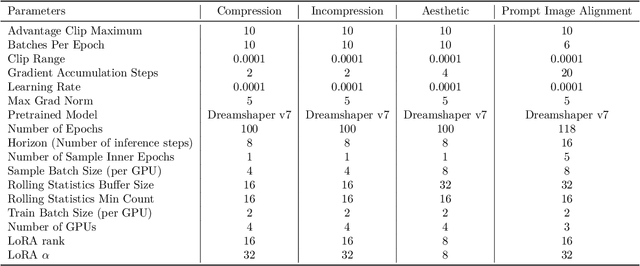
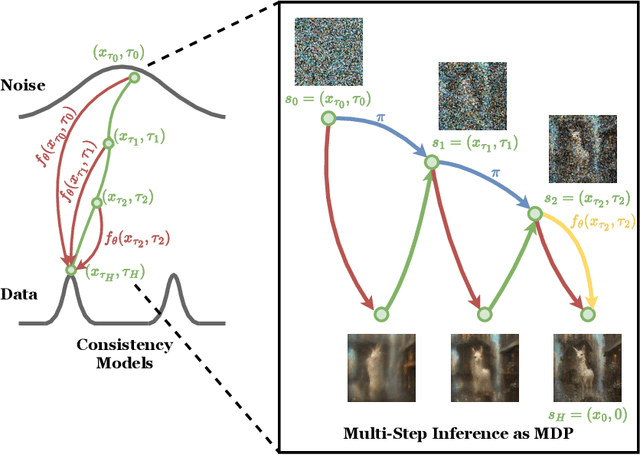

Reinforcement learning (RL) has improved guided image generation with diffusion models by directly optimizing rewards that capture image quality, aesthetics, and instruction following capabilities. However, the resulting generative policies inherit the same iterative sampling process of diffusion models that causes slow generation. To overcome this limitation, consistency models proposed learning a new class of generative models that directly map noise to data, resulting in a model that can generate an image in as few as one sampling iteration. In this work, to optimize text-to-image generative models for task specific rewards and enable fast training and inference, we propose a framework for fine-tuning consistency models via RL. Our framework, called Reinforcement Learning for Consistency Model (RLCM), frames the iterative inference process of a consistency model as an RL procedure. RLCM improves upon RL fine-tuned diffusion models on text-to-image generation capabilities and trades computation during inference time for sample quality. Experimentally, we show that RLCM can adapt text-to-image consistency models to objectives that are challenging to express with prompting, such as image compressibility, and those derived from human feedback, such as aesthetic quality. Comparing to RL finetuned diffusion models, RLCM trains significantly faster, improves the quality of the generation measured under the reward objectives, and speeds up the inference procedure by generating high quality images with as few as two inference steps. Our code is available at https://rlcm.owenoertell.com
Policy-Gradient Training of Language Models for Ranking
Oct 06, 2023



Text retrieval plays a crucial role in incorporating factual knowledge for decision making into language processing pipelines, ranging from chat-based web search to question answering systems. Current state-of-the-art text retrieval models leverage pre-trained large language models (LLMs) to achieve competitive performance, but training LLM-based retrievers via typical contrastive losses requires intricate heuristics, including selecting hard negatives and using additional supervision as learning signals. This reliance on heuristics stems from the fact that the contrastive loss itself is heuristic and does not directly optimize the downstream metrics of decision quality at the end of the processing pipeline. To address this issue, we introduce Neural PG-RANK, a novel training algorithm that learns to rank by instantiating a LLM as a Plackett-Luce ranking policy. Neural PG-RANK provides a principled method for end-to-end training of retrieval models as part of larger decision systems via policy gradient, with little reliance on complex heuristics, and it effectively unifies the training objective with downstream decision-making quality. We conduct extensive experiments on various text retrieval benchmarks. The results demonstrate that when the training objective aligns with the evaluation setup, Neural PG-RANK yields remarkable in-domain performance improvement, with substantial out-of-domain generalization to some critical datasets employed in downstream question answering tasks.
Learning to Generate Better Than Your LLM
Jun 20, 2023Reinforcement learning (RL) has emerged as a powerful paradigm for fine-tuning Large Language Models (LLMs) for conditional text generation. In particular, recent LLMs such as ChatGPT and GPT-4 can engage in fluent conversations with users by incorporating RL and feedback from humans. Inspired by learning-to-search algorithms and capitalizing on key properties of text generation, we seek to investigate reinforcement learning algorithms beyond general purpose algorithms such as Proximal policy optimization (PPO). In particular, we extend RL algorithms to allow them to interact with a dynamic black-box guide LLM such as GPT-3 and propose RL with guided feedback (RLGF), a suite of RL algorithms for LLM fine-tuning. We experiment on the IMDB positive review and CommonGen text generation task from the GRUE benchmark. We show that our RL algorithms achieve higher performance than supervised learning (SL) and default PPO baselines, demonstrating the benefit of interaction with the guide LLM. On CommonGen, we not only outperform our SL baselines but also improve beyond PPO across a variety of lexical and semantic metrics beyond the one we optimized for. Notably, on the IMDB dataset, we show that our GPT-2 based policy outperforms the zero-shot GPT-3 oracle, indicating that our algorithms can learn from a powerful, black-box GPT-3 oracle with a simpler, cheaper, and publicly available GPT-2 model while gaining performance.
Learning Bellman Complete Representations for Offline Policy Evaluation
Jul 12, 2022


We study representation learning for Offline Reinforcement Learning (RL), focusing on the important task of Offline Policy Evaluation (OPE). Recent work shows that, in contrast to supervised learning, realizability of the Q-function is not enough for learning it. Two sufficient conditions for sample-efficient OPE are Bellman completeness and coverage. Prior work often assumes that representations satisfying these conditions are given, with results being mostly theoretical in nature. In this work, we propose BCRL, which directly learns from data an approximately linear Bellman complete representation with good coverage. With this learned representation, we perform OPE using Least Square Policy Evaluation (LSPE) with linear functions in our learned representation. We present an end-to-end theoretical analysis, showing that our two-stage algorithm enjoys polynomial sample complexity provided some representation in the rich class considered is linear Bellman complete. Empirically, we extensively evaluate our algorithm on challenging, image-based continuous control tasks from the Deepmind Control Suite. We show our representation enables better OPE compared to previous representation learning methods developed for off-policy RL (e.g., CURL, SPR). BCRL achieve competitive OPE error with the state-of-the-art method Fitted Q-Evaluation (FQE), and beats FQE when evaluating beyond the initial state distribution. Our ablations show that both linear Bellman complete and coverage components of our method are crucial.
* Accepted for Long Talk at ICML 2022
Mitigating Covariate Shift in Imitation Learning via Offline Data Without Great Coverage
Jun 14, 2021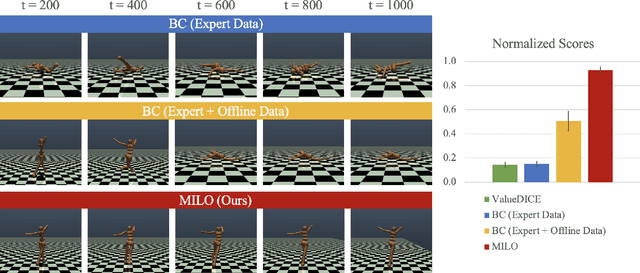

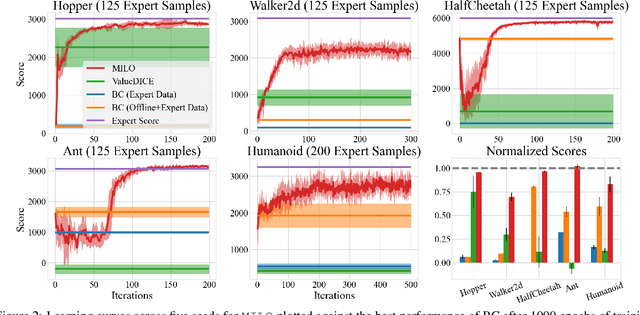
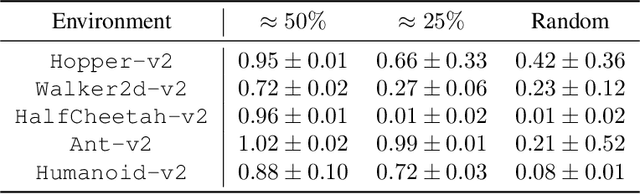
This paper studies offline Imitation Learning (IL) where an agent learns to imitate an expert demonstrator without additional online environment interactions. Instead, the learner is presented with a static offline dataset of state-action-next state transition triples from a potentially less proficient behavior policy. We introduce Model-based IL from Offline data (MILO): an algorithmic framework that utilizes the static dataset to solve the offline IL problem efficiently both in theory and in practice. In theory, even if the behavior policy is highly sub-optimal compared to the expert, we show that as long as the data from the behavior policy provides sufficient coverage on the expert state-action traces (and with no necessity for a global coverage over the entire state-action space), MILO can provably combat the covariate shift issue in IL. Complementing our theory results, we also demonstrate that a practical implementation of our approach mitigates covariate shift on benchmark MuJoCo continuous control tasks. We demonstrate that with behavior policies whose performances are less than half of that of the expert, MILO still successfully imitates with an extremely low number of expert state-action pairs while traditional offline IL method such as behavior cloning (BC) fails completely. Source code is provided at https://github.com/jdchang1/milo.