 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$p1$: Better Prompt Optimization with Fewer Prompts
Apr 09, 2026Prompt optimization improves language models without updating their weights by searching for a better system prompt, but its effectiveness varies widely across tasks. We study what makes a task amenable to prompt optimization. We show that the reward variance across different system prompts can be decomposed into two components: variance among responses, which captures generation stochasticity, and variance among system prompts, which captures differences in system prompt quality. Prompt optimization succeeds when variance among system prompts is sufficiently large, but fails when variance among responses dominates the variance of the system prompts. Surprisingly, we further show that scaling to more user prompts can hurt optimization by reducing variance among system prompts, especially on heterogeneous datasets where different user prompts favor different system prompts. Motivated by this insight, we propose $p1$, a simple user prompt filtering method that selects a small subset of user prompts with high variance across candidate system prompts. This subset of user prompts allows one to distinguish a good system prompt from a bad one, making system optimization easier. Experiments on reasoning benchmarks show that $p1$ substantially improves prompt optimization over training on the full dataset and outperforms strong baselines such as GEPA. Notably, training on only two prompts from AIME 24 yields a system prompt that generalizes well to other reasoning benchmarks.
Pre-trained Large Language Models Learn Hidden Markov Models In-context
Jun 08, 2025Hidden Markov Models (HMMs) are foundational tools for modeling sequential data with latent Markovian structure, yet fitting them to real-world data remains computationally challenging. In this work, we show that pre-trained large language models (LLMs) can effectively model data generated by HMMs via in-context learning (ICL)$\unicode{x2013}$their ability to infer patterns from examples within a prompt. On a diverse set of synthetic HMMs, LLMs achieve predictive accuracy approaching the theoretical optimum. We uncover novel scaling trends influenced by HMM properties, and offer theoretical conjectures for these empirical observations. We also provide practical guidelines for scientists on using ICL as a diagnostic tool for complex data. On real-world animal decision-making tasks, ICL achieves competitive performance with models designed by human experts. To our knowledge, this is the first demonstration that ICL can learn and predict HMM-generated sequences$\unicode{x2013}$an advance that deepens our understanding of in-context learning in LLMs and establishes its potential as a powerful tool for uncovering hidden structure in complex scientific data.
Accelerating RL for LLM Reasoning with Optimal Advantage Regression
May 27, 2025Reinforcement learning (RL) has emerged as a powerful tool for fine-tuning large language models (LLMs) to improve complex reasoning abilities. However, state-of-the-art policy optimization methods often suffer from high computational overhead and memory consumption, primarily due to the need for multiple generations per prompt and the reliance on critic networks or advantage estimates of the current policy. In this paper, we propose $A$*-PO, a novel two-stage policy optimization framework that directly approximates the optimal advantage function and enables efficient training of LLMs for reasoning tasks. In the first stage, we leverage offline sampling from a reference policy to estimate the optimal value function $V$*, eliminating the need for costly online value estimation. In the second stage, we perform on-policy updates using a simple least-squares regression loss with only a single generation per prompt. Theoretically, we establish performance guarantees and prove that the KL-regularized RL objective can be optimized without requiring complex exploration strategies. Empirically, $A$*-PO achieves competitive performance across a wide range of mathematical reasoning benchmarks, while reducing training time by up to 2$\times$ and peak memory usage by over 30% compared to PPO, GRPO, and REBEL. Implementation of $A$*-PO can be found at https://github.com/ZhaolinGao/A-PO.
Value-Guided Search for Efficient Chain-of-Thought Reasoning
May 23, 2025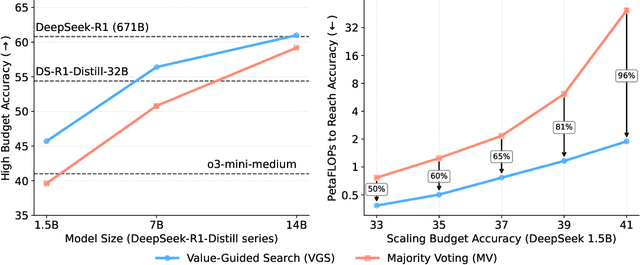

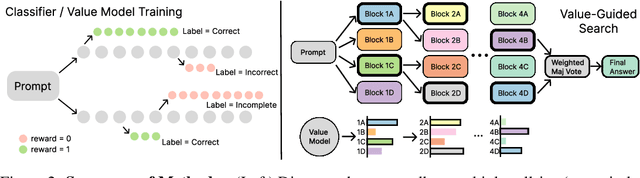
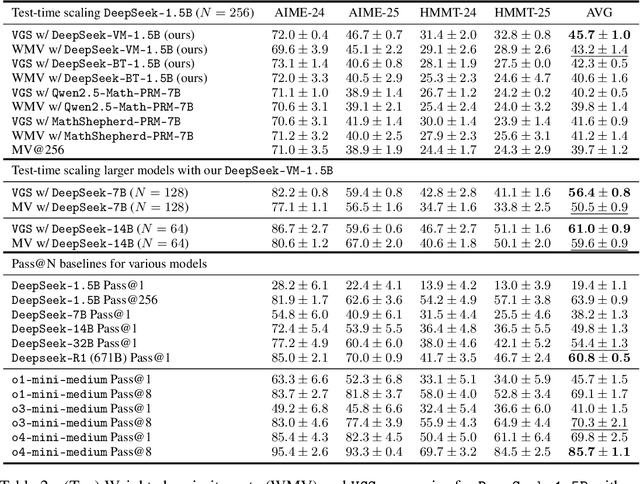
In this paper, we propose a simple and efficient method for value model training on long-context reasoning traces. Compared to existing process reward models (PRMs), our method does not require a fine-grained notion of "step," which is difficult to define for long-context reasoning models. By collecting a dataset of 2.5 million reasoning traces, we train a 1.5B token-level value model and apply it to DeepSeek models for improved performance with test-time compute scaling. We find that block-wise value-guided search (VGS) with a final weighted majority vote achieves better test-time scaling than standard methods such as majority voting or best-of-n. With an inference budget of 64 generations, VGS with DeepSeek-R1-Distill-1.5B achieves an average accuracy of 45.7% across four competition math benchmarks (AIME 2024 & 2025, HMMT Feb 2024 & 2025), reaching parity with o3-mini-medium. Moreover, VGS significantly reduces the inference FLOPs required to achieve the same performance of majority voting. Our dataset, model and codebase are open-sourced.
$Q\sharp$: Provably Optimal Distributional RL for LLM Post-Training
Feb 27, 2025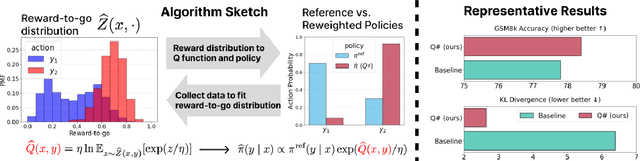



Reinforcement learning (RL) post-training is crucial for LLM alignment and reasoning, but existing policy-based methods, such as PPO and DPO, can fall short of fixing shortcuts inherited from pre-training. In this work, we introduce $Q\sharp$, a value-based algorithm for KL-regularized RL that guides the reference policy using the optimal regularized $Q$ function. We propose to learn the optimal $Q$ function using distributional RL on an aggregated online dataset. Unlike prior value-based baselines that guide the model using unregularized $Q$-values, our method is theoretically principled and provably learns the optimal policy for the KL-regularized RL problem. Empirically, $Q\sharp$ outperforms prior baselines in math reasoning benchmarks while maintaining a smaller KL divergence to the reference policy. Theoretically, we establish a reduction from KL-regularized RL to no-regret online learning, providing the first bounds for deterministic MDPs under only realizability. Thanks to distributional RL, our bounds are also variance-dependent and converge faster when the reference policy has small variance. In sum, our results highlight $Q\sharp$ as an effective approach for post-training LLMs, offering both improved performance and theoretical guarantees. The code can be found at https://github.com/jinpz/q_sharp.
End-to-end Training for Recommendation with Language-based User Profiles
Oct 24, 2024



Many online platforms maintain user profiles for personalization. Unfortunately, these profiles are typically not interpretable or easily modifiable by the user. To remedy this shortcoming, we explore natural language-based user profiles, as they promise enhanced transparency and scrutability of recommender systems. While existing work has shown that language-based profiles from standard LLMs can be effective, such generalist LLMs are unlikely to be optimal for this task. In this paper, we introduce LangPTune, the first end-to-end learning method for training LLMs to produce language-based user profiles that optimize recommendation effectiveness. Through comprehensive evaluations of LangPTune across various training configurations and benchmarks, we demonstrate that our approach significantly outperforms existing profile-based methods. In addition, it approaches performance levels comparable to state-of-the-art, less transparent recommender systems, providing a robust and interpretable alternative to conventional systems. Finally, we validate the relative interpretability of these language-based user profiles through user studies involving crowdworkers and GPT-4-based evaluations. Implementation of LangPTune can be found at https://github.com/ZhaolinGao/LangPTune.
Regressing the Relative Future: Efficient Policy Optimization for Multi-turn RLHF
Oct 06, 2024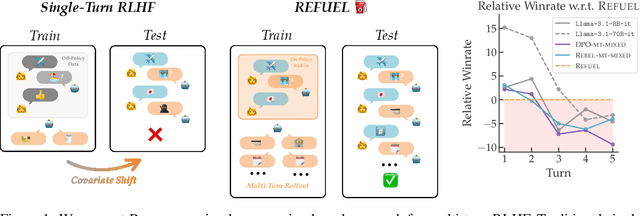
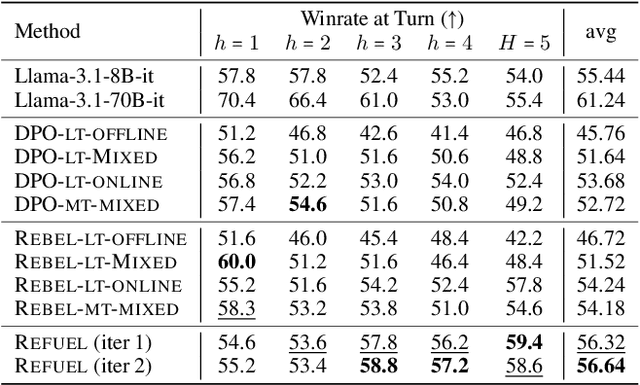
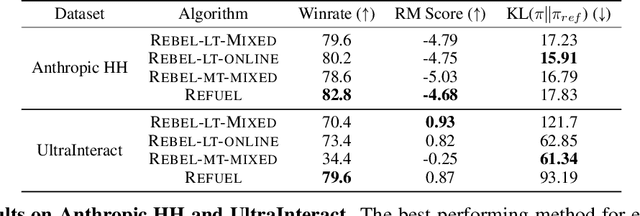
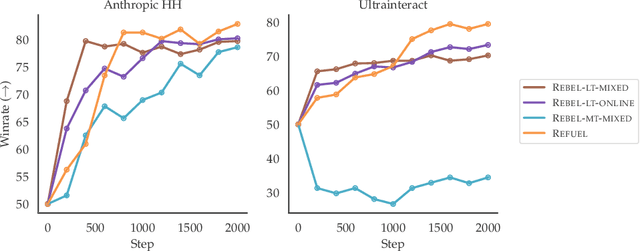
Large Language Models (LLMs) have achieved remarkable success at tasks like summarization that involve a single turn of interaction. However, they can still struggle with multi-turn tasks like dialogue that require long-term planning. Previous works on multi-turn dialogue extend single-turn reinforcement learning from human feedback (RLHF) methods to the multi-turn setting by treating all prior dialogue turns as a long context. Such approaches suffer from covariate shift: the conversations in the training set have previous turns generated by some reference policy, which means that low training error may not necessarily correspond to good performance when the learner is actually in the conversation loop. In response, we introduce REgressing the RELative FUture (REFUEL), an efficient policy optimization approach designed to address multi-turn RLHF in LLMs. REFUEL employs a single model to estimate $Q$-values and trains on self-generated data, addressing the covariate shift issue. REFUEL frames the multi-turn RLHF problem as a sequence of regression tasks on iteratively collected datasets, enabling ease of implementation. Theoretically, we prove that REFUEL can match the performance of any policy covered by the training set. Empirically, we evaluate our algorithm by using Llama-3.1-70B-it to simulate a user in conversation with our model. REFUEL consistently outperforms state-of-the-art methods such as DPO and REBEL across various settings. Furthermore, despite having only 8 billion parameters, Llama-3-8B-it fine-tuned with REFUEL outperforms Llama-3.1-70B-it on long multi-turn dialogues. Implementation of REFUEL can be found at https://github.com/ZhaolinGao/REFUEL/, and models trained by REFUEL can be found at https://huggingface.co/Cornell-AGI.
REBEL: Reinforcement Learning via Regressing Relative Rewards
Apr 25, 2024While originally developed for continuous control problems, Proximal Policy Optimization (PPO) has emerged as the work-horse of a variety of reinforcement learning (RL) applications including the fine-tuning of generative models. Unfortunately, PPO requires multiple heuristics to enable stable convergence (e.g. value networks, clipping) and is notorious for its sensitivity to the precise implementation of these components. In response, we take a step back and ask what a minimalist RL algorithm for the era of generative models would look like. We propose REBEL, an algorithm that cleanly reduces the problem of policy optimization to regressing the relative rewards via a direct policy parameterization between two completions to a prompt, enabling strikingly lightweight implementation. In theory, we prove that fundamental RL algorithms like Natural Policy Gradient can be seen as variants of REBEL, which allows us to match the strongest known theoretical guarantees in terms of convergence and sample complexity in the RL literature. REBEL can also cleanly incorporate offline data and handle the intransitive preferences we frequently see in practice. Empirically, we find that REBEL provides a unified approach to language modeling and image generation with stronger or similar performance as PPO and DPO, all while being simpler to implement and more computationally tractable than PPO.
Reviewer2: Optimizing Review Generation Through Prompt Generation
Feb 16, 2024Recent developments in LLMs offer new opportunities for assisting authors in improving their work. In this paper, we envision a use case where authors can receive LLM-generated reviews that uncover weak points in the current draft. While initial methods for automated review generation already exist, these methods tend to produce reviews that lack detail, and they do not cover the range of opinions that human reviewers produce. To address this shortcoming, we propose an efficient two-stage review generation framework called Reviewer2. Unlike prior work, this approach explicitly models the distribution of possible aspects that the review may address. We show that this leads to more detailed reviews that better cover the range of aspects that human reviewers identify in the draft. As part of the research, we generate a large-scale review dataset of 27k papers and 99k reviews that we annotate with aspect prompts, which we make available as a resource for future research.
Shoestring: Graph-Based Semi-Supervised Learning with Severely Limited Labeled Data
Oct 28, 2019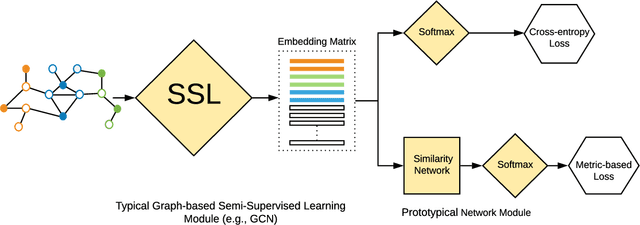

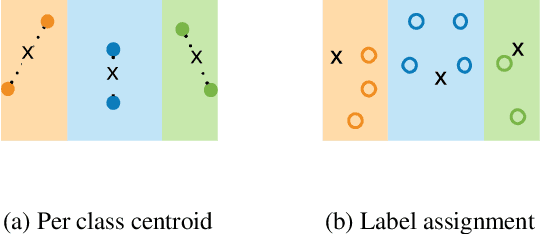
Graph-based semi-supervised learning has been shown to be one of the most effective approaches for classification tasks from a wide range of domains, such as image classification and text classification, as they can exploit the connectivity patterns between labeled and unlabeled samples to improve learning performance. In this work, we advance this effective learning paradigm towards a scenario where labeled data are severely limited. More specifically, we address the problem of graph-based semi-supervised learning in the presence of severely limited labeled samples, and propose a new framework, called {\em Shoestring}, that improves the learning performance through semantic transfer from these very few labeled samples to large numbers of unlabeled samples. In particular, our framework learns a metric space in which classification can be performed by computing the similarity to centroid embedding of each class. {\em Shoestring} is trained in an end-to-end fashion to learn to leverage the semantic knowledge of limited labeled samples as well as their connectivity patterns with large numbers of unlabeled samples simultaneously. By combining {\em Shoestring} with graph convolutional networks, label propagation and their recent label-efficient variations (IGCN and GLP), we are able to achieve state-of-the-art node classification performance in the presence of very few labeled samples. In addition, we demonstrate the effectiveness of our framework on image classification tasks in the few-shot learning regime, with significant gains on miniImageNet ($2.57\%\sim3.59\%$) and tieredImageNet ($1.05\%\sim2.70\%$).