 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-DAG: A Subject-Based Directed Acyclic Graph for Multi-Agent Heterogeneous Reasoning
Nov 19, 2025Large Language Models (LLMs) have achieved impressive performance in complex reasoning problems. Their effectiveness highly depends on the specific nature of the task, especially the required domain knowledge. Existing approaches, such as mixture-of-experts, typically operate at the task level; they are too coarse to effectively solve the heterogeneous problems involving multiple subjects. This work proposes a novel framework that performs fine-grained analysis at subject level equipped with a designated multi-agent collaboration strategy for addressing heterogeneous problem reasoning. Specifically, given an input query, we first employ a Graph Neural Network to identify the relevant subjects and infer their interdependencies to generate an \textit{Subject-based Directed Acyclic Graph} (S-DAG), where nodes represent subjects and edges encode information flow. Then we profile the LLM models by assigning each model a subject-specific expertise score, and select the top-performing one for matching corresponding subject of the S-DAG. Such subject-model matching enables graph-structured multi-agent collaboration where information flows from the starting model to the ending model over S-DAG. We curate and release multi-subject subsets of standard benchmarks (MMLU-Pro, GPQA, MedMCQA) to better reflect complex, real-world reasoning tasks. Extensive experiments show that our approach significantly outperforms existing task-level model selection and multi-agent collaboration baselines in accuracy and efficiency. These results highlight the effectiveness of subject-aware reasoning and structured collaboration in addressing complex and multi-subject problems.
The Compositional Architecture of Regret in Large Language Models
Jun 18, 2025



Regret in Large Language Models refers to their explicit regret expression when presented with evidence contradicting their previously generated misinformation. Studying the regret mechanism is crucial for enhancing model reliability and helps in revealing how cognition is coded in neural networks. To understand this mechanism, we need to first identify regret expressions in model outputs, then analyze their internal representation. This analysis requires examining the model's hidden states, where information processing occurs at the neuron level. However, this faces three key challenges: (1) the absence of specialized datasets capturing regret expressions, (2) the lack of metrics to find the optimal regret representation layer, and (3) the lack of metrics for identifying and analyzing regret neurons. Addressing these limitations, we propose: (1) a workflow for constructing a comprehensive regret dataset through strategically designed prompting scenarios, (2) the Supervised Compression-Decoupling Index (S-CDI) metric to identify optimal regret representation layers, and (3) the Regret Dominance Score (RDS) metric to identify regret neurons and the Group Impact Coefficient (GIC) to analyze activation patterns. Our experimental results successfully identified the optimal regret representation layer using the S-CDI metric, which significantly enhanced performance in probe classification experiments. Additionally, we discovered an M-shaped decoupling pattern across model layers, revealing how information processing alternates between coupling and decoupling phases. Through the RDS metric, we categorized neurons into three distinct functional groups: regret neurons, non-regret neurons, and dual neurons.
Knowledge Grafting of Large Language Models
May 24, 2025Cross-capability transfer is a key challenge in large language model (LLM) research, with applications in multi-task integration, model compression, and continual learning. Recent works like FuseLLM and FuseChat have demonstrated the potential of transferring multiple model capabilities to lightweight models, enhancing adaptability and efficiency, which motivates our investigation into more efficient cross-capability transfer methods. However, existing approaches primarily focus on small, homogeneous models, limiting their applicability. For large, heterogeneous models, knowledge distillation with full-parameter fine-tuning often overlooks the student model's intrinsic capacity and risks catastrophic forgetting, while PEFT methods struggle to effectively absorb knowledge from source LLMs. To address these issues, we introduce GraftLLM, a novel method that stores source model capabilities in a target model with SkillPack format. This approach preserves general capabilities, reduces parameter conflicts, and supports forget-free continual learning and model fusion. We employ a module-aware adaptive compression strategy to compress parameter updates, ensuring efficient storage while maintaining task-specific knowledge. The resulting SkillPack serves as a compact and transferable knowledge carrier, ideal for heterogeneous model fusion and continual learning. Experiments across various scenarios demonstrate that GraftLLM outperforms existing techniques in knowledge transfer, knowledge fusion, and forget-free learning, providing a scalable and efficient solution for cross-capability transfer. The code is publicly available at: https://github.com/duguodong7/GraftLLM.
HPS: Hard Preference Sampling for Human Preference Alignment
Feb 20, 2025Aligning Large Language Model (LLM) responses with human preferences is vital for building safe and controllable AI systems. While preference optimization methods based on Plackett-Luce (PL) and Bradley-Terry (BT) models have shown promise, they face challenges such as poor handling of harmful content, inefficient use of dispreferred responses, and, specifically for PL, high computational costs. To address these issues, we propose Hard Preference Sampling (HPS), a novel framework for robust and efficient human preference alignment. HPS introduces a training loss that prioritizes the most preferred response while rejecting all dispreferred and harmful ones. It emphasizes "hard" dispreferred responses--those closely resembling preferred ones--to enhance the model's rejection capabilities. By leveraging a single-sample Monte Carlo sampling strategy, HPS reduces computational overhead while maintaining alignment quality. Theoretically, HPS improves sample efficiency over existing PL methods and maximizes the reward margin between preferred and dispreferred responses, ensuring clearer distinctions. Experiments on HH-RLHF and PKU-Safety datasets validate HPS's effectiveness, achieving comparable BLEU and reward scores while greatly improving reward margins and thus reducing harmful content generation.
Accelerating AIGC Services with Latent Action Diffusion Scheduling in Edge Networks
Dec 24, 2024



Artificial Intelligence Generated Content (AIGC) has gained significant popularity for creating diverse content. Current AIGC models primarily focus on content quality within a centralized framework, resulting in a high service delay and negative user experiences. However, not only does the workload of an AIGC task depend on the AIGC model's complexity rather than the amount of data, but the large model and its multi-layer encoder structure also result in a huge demand for computational and memory resources. These unique characteristics pose new challenges in its modeling, deployment, and scheduling at edge networks. Thus, we model an offloading problem among edges for providing real AIGC services and propose LAD-TS, a novel Latent Action Diffusion-based Task Scheduling method that orchestrates multiple edge servers for expedited AIGC services. The LAD-TS generates a near-optimal offloading decision by leveraging the diffusion model's conditional generation capability and the reinforcement learning's environment interaction ability, thereby minimizing the service delays under multiple resource constraints. Meanwhile, a latent action diffusion strategy is designed to guide decision generation by utilizing historical action probability, enabling rapid achievement of near-optimal decisions. Furthermore, we develop DEdgeAI, a prototype edge system with a refined AIGC model deployment to implement and evaluate our LAD-TS method. DEdgeAI provides a real AIGC service for users, demonstrating up to 29.18% shorter service delays than the current five representative AIGC platforms. We release our open-source code at https://github.com/ChangfuXu/DEdgeAI/.
Unveiling Molecular Secrets: An LLM-Augmented Linear Model for Explainable and Calibratable Molecular Property Prediction
Oct 11, 2024



Explainable molecular property prediction is essential for various scientific fields, such as drug discovery and material science. Despite delivering intrinsic explainability, linear models struggle with capturing complex, non-linear patterns. Large language models (LLMs), on the other hand, yield accurate predictions through powerful inference capabilities yet fail to provide chemically meaningful explanations for their predictions. This work proposes a novel framework, called MoleX, which leverages LLM knowledge to build a simple yet powerful linear model for accurate molecular property prediction with faithful explanations. The core of MoleX is to model complicated molecular structure-property relationships using a simple linear model, augmented by LLM knowledge and a crafted calibration strategy. Specifically, to extract the maximum amount of task-relevant knowledge from LLM embeddings, we employ information bottleneck-inspired fine-tuning and sparsity-inducing dimensionality reduction. These informative embeddings are then used to fit a linear model for explainable inference. Moreover, we introduce residual calibration to address prediction errors stemming from linear models' insufficient expressiveness of complex LLM embeddings, thus recovering the LLM's predictive power and boosting overall accuracy. Theoretically, we provide a mathematical foundation to justify MoleX's explainability. Extensive experiments demonstrate that MoleX outperforms existing methods in molecular property prediction, establishing a new milestone in predictive performance, explainability, and efficiency. In particular, MoleX enables CPU inference and accelerates large-scale dataset processing, achieving comparable performance 300x faster with 100,000 fewer parameters than LLMs. Additionally, the calibration improves model performance by up to 12.7% without compromising explainability.
Faithful Interpretation for Graph Neural Networks
Oct 09, 2024Currently, attention mechanisms have garnered increasing attention in Graph Neural Networks (GNNs), such as Graph Attention Networks (GATs) and Graph Transformers (GTs). It is not only due to the commendable boost in performance they offer but also its capacity to provide a more lucid rationale for model behaviors, which are often viewed as inscrutable. However, Attention-based GNNs have demonstrated instability in interpretability when subjected to various sources of perturbations during both training and testing phases, including factors like additional edges or nodes. In this paper, we propose a solution to this problem by introducing a novel notion called Faithful Graph Attention-based Interpretation (FGAI). In particular, FGAI has four crucial properties regarding stability and sensitivity to interpretation and final output distribution. Built upon this notion, we propose an efficient methodology for obtaining FGAI, which can be viewed as an ad hoc modification to the canonical Attention-based GNNs. To validate our proposed solution, we introduce two novel metrics tailored for graph interpretation assessment. Experimental results demonstrate that FGAI exhibits superior stability and preserves the interpretability of attention under various forms of perturbations and randomness, which makes FGAI a more faithful and reliable explanation tool.
Debiasing Graph Representation Learning based on Information Bottleneck
Sep 02, 2024Graph representation learning has shown superior performance in numerous real-world applications, such as finance and social networks. Nevertheless, most existing works might make discriminatory predictions due to insufficient attention to fairness in their decision-making processes. This oversight has prompted a growing focus on fair representation learning. Among recent explorations on fair representation learning, prior works based on adversarial learning usually induce unstable or counterproductive performance. To achieve fairness in a stable manner, we present the design and implementation of GRAFair, a new framework based on a variational graph auto-encoder. The crux of GRAFair is the Conditional Fairness Bottleneck, where the objective is to capture the trade-off between the utility of representations and sensitive information of interest. By applying variational approximation, we can make the optimization objective tractable. Particularly, GRAFair can be trained to produce informative representations of tasks while containing little sensitive information without adversarial training. Experiments on various real-world datasets demonstrate the effectiveness of our proposed method in terms of fairness, utility, robustness, and stability.
Explainable Molecular Property Prediction: Aligning Chemical Concepts with Predictions via Language Models
May 25, 2024



Providing explainable molecule property predictions is critical for many scientific domains, such as drug discovery and material science. Though transformer-based language models have shown great potential in accurate molecular property prediction, they neither provide chemically meaningful explanations nor faithfully reveal the molecular structure-property relationships. In this work, we develop a new framework for explainable molecular property prediction based on language models, dubbed as Lamole, which can provide chemical concepts-aligned explanations. We first leverage a designated molecular representation -- the Group SELFIES -- as it can provide chemically meaningful semantics. Because attention mechanisms in Transformers can inherently capture relationships within the input, we further incorporate the attention weights and gradients together to generate explanations for capturing the functional group interactions. We then carefully craft a marginal loss to explicitly optimize the explanations to be able to align with the chemists' annotations. We bridge the manifold hypothesis with the elaborated marginal loss to prove that the loss can align the explanations with the tangent space of the data manifold, leading to concept-aligned explanations. Experimental results over six mutagenicity datasets and one hepatotoxicity dataset demonstrate Lamole can achieve comparable classification accuracy and boost the explanation accuracy by up to 14.8%, being the state-of-the-art in explainable molecular property prediction.
Fast 3D Molecule Generation via Unified Geometric Optimal Transport
May 24, 2024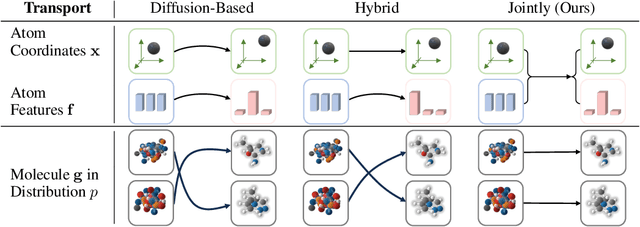
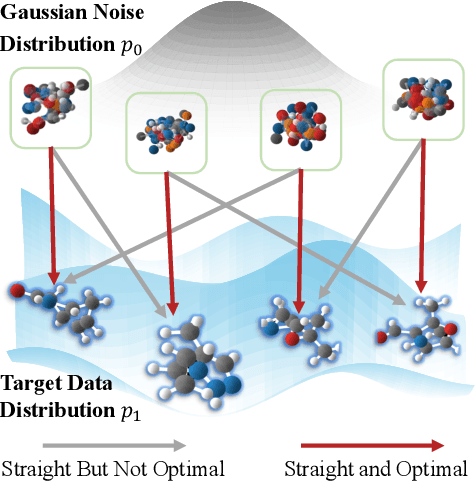
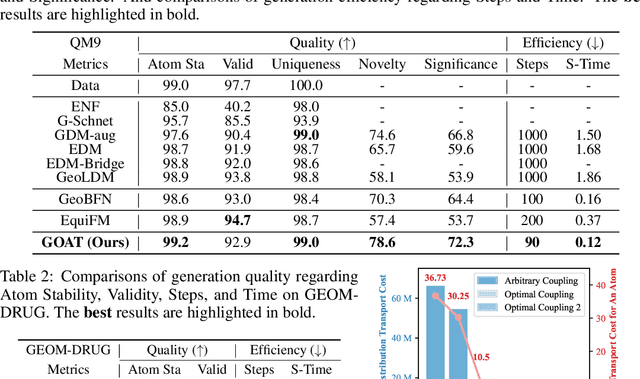
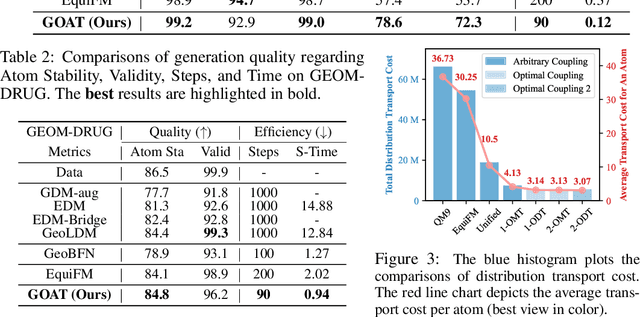
This paper proposes a new 3D molecule generation framework, called GOAT, for fast and effective 3D molecule generation based on the flow-matching optimal transport objective. Specifically, we formulate a geometric transport formula for measuring the cost of mapping multi-modal features (e.g., continuous atom coordinates and categorical atom types) between a base distribution and a target data distribution. Our formula is solved within a unified, equivalent, and smooth representation space. This is achieved by transforming the multi-modal features into a continuous latent space with equivalent networks. In addition, we find that identifying optimal distributional coupling is necessary for fast and effective transport between any two distributions. We further propose a flow refinement and purification mechanism for optimal coupling identification. By doing so, GOAT can turn arbitrary distribution couplings into new deterministic couplings, leading to a unified optimal transport path for fast 3D molecule generation. The purification filters the subpar molecules to ensure the ultimate generation performance. We theoretically prove the proposed method indeed reduced the transport cost. Finally, extensive experiments show that GOAT enjoys the efficiency of solving geometric optimal transport, leading to a double speedup compared to the sub-optimal method while achieving the best generation quality regarding validity, uniqueness, and novelty.