 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Optical Flow and Textual Prompts Collaborate to Assist in Audio-Visual Semantic Segmentation?
Jan 13, 2026Audio-visual semantic segmentation (AVSS) represents an extension of the audio-visual segmentation (AVS) task, necessitating a semantic understanding of audio-visual scenes beyond merely identifying sound-emitting objects at the visual pixel level. Contrary to a previous methodology, by decomposing the AVSS task into two discrete subtasks by initially providing a prompted segmentation mask to facilitate subsequent semantic analysis, our approach innovates on this foundational strategy. We introduce a novel collaborative framework, \textit{S}tepping \textit{S}tone \textit{P}lus (SSP), which integrates optical flow and textual prompts to assist the segmentation process. In scenarios where sound sources frequently coexist with moving objects, our pre-mask technique leverages optical flow to capture motion dynamics, providing essential temporal context for precise segmentation. To address the challenge posed by stationary sound-emitting objects, such as alarm clocks, SSP incorporates two specific textual prompts: one identifies the category of the sound-emitting object, and the other provides a broader description of the scene. Additionally, we implement a visual-textual alignment module (VTA) to facilitate cross-modal integration, delivering more coherent and contextually relevant semantic interpretations. Our training regimen involves a post-mask technique aimed at compelling the model to learn the diagram of the optical flow. Experimental results demonstrate that SSP outperforms existing AVS methods, delivering efficient and precise segmentation results.
Enhancing Rotation-Invariant 3D Learning with Global Pose Awareness and Attention Mechanisms
Nov 11, 2025Recent advances in rotation-invariant (RI) learning for 3D point clouds typically replace raw coordinates with handcrafted RI features to ensure robustness under arbitrary rotations. However, these approaches often suffer from the loss of global pose information, making them incapable of distinguishing geometrically similar but spatially distinct structures. We identify that this limitation stems from the restricted receptive field in existing RI methods, leading to Wing-tip feature collapse, a failure to differentiate symmetric components (e.g., left and right airplane wings) due to indistinguishable local geometries. To overcome this challenge, we introduce the Shadow-informed Pose Feature (SiPF), which augments local RI descriptors with a globally consistent reference point (referred to as the 'shadow') derived from a learned shared rotation. This mechanism enables the model to preserve global pose awareness while maintaining rotation invariance. We further propose Rotation-invariant Attention Convolution (RIAttnConv), an attention-based operator that integrates SiPFs into the feature aggregation process, thereby enhancing the model's capacity to distinguish structurally similar components. Additionally, we design a task-adaptive shadow locating module based on the Bingham distribution over unit quaternions, which dynamically learns the optimal global rotation for constructing consistent shadows. Extensive experiments on 3D classification and part segmentation benchmarks demonstrate that our approach substantially outperforms existing RI methods, particularly in tasks requiring fine-grained spatial discrimination under arbitrary rotations.
Accelerating AIGC Services with Latent Action Diffusion Scheduling in Edge Networks
Dec 24, 2024



Artificial Intelligence Generated Content (AIGC) has gained significant popularity for creating diverse content. Current AIGC models primarily focus on content quality within a centralized framework, resulting in a high service delay and negative user experiences. However, not only does the workload of an AIGC task depend on the AIGC model's complexity rather than the amount of data, but the large model and its multi-layer encoder structure also result in a huge demand for computational and memory resources. These unique characteristics pose new challenges in its modeling, deployment, and scheduling at edge networks. Thus, we model an offloading problem among edges for providing real AIGC services and propose LAD-TS, a novel Latent Action Diffusion-based Task Scheduling method that orchestrates multiple edge servers for expedited AIGC services. The LAD-TS generates a near-optimal offloading decision by leveraging the diffusion model's conditional generation capability and the reinforcement learning's environment interaction ability, thereby minimizing the service delays under multiple resource constraints. Meanwhile, a latent action diffusion strategy is designed to guide decision generation by utilizing historical action probability, enabling rapid achievement of near-optimal decisions. Furthermore, we develop DEdgeAI, a prototype edge system with a refined AIGC model deployment to implement and evaluate our LAD-TS method. DEdgeAI provides a real AIGC service for users, demonstrating up to 29.18% shorter service delays than the current five representative AIGC platforms. We release our open-source code at https://github.com/ChangfuXu/DEdgeAI/.
Leveraging CORAL-Correlation Consistency Network for Semi-Supervised Left Atrium MRI Segmentation
Oct 21, 2024
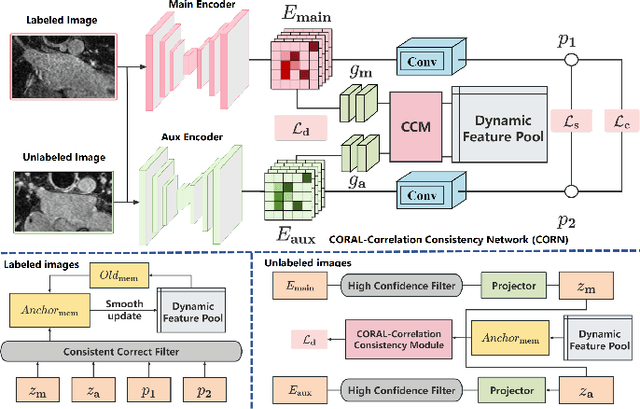
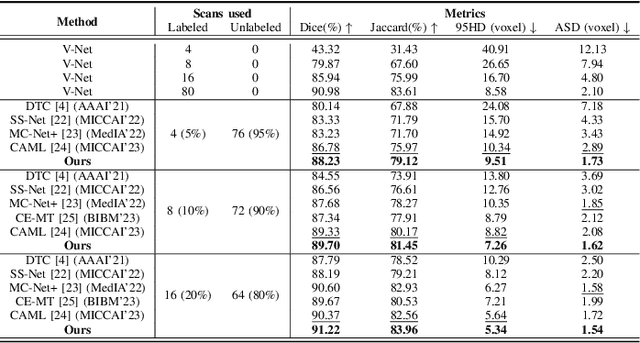
Semi-supervised learning (SSL) has been widely used to learn from both a few labeled images and many unlabeled images to overcome the scarcity of labeled samples in medical image segmentation. Most current SSL-based segmentation methods use pixel values directly to identify similar features in labeled and unlabeled data. They usually fail to accurately capture the intricate attachment structures in the left atrium, such as the areas of inconsistent density or exhibit outward curvatures, adding to the complexity of the task. In this paper, we delve into this issue and introduce an effective solution, CORAL(Correlation-Aligned)-Correlation Consistency Network (CORN), to capture the global structure shape and local details of Left Atrium. Diverging from previous methods focused on each local pixel value, the CORAL-Correlation Consistency Module (CCM) in the CORN leverages second-order statistical information to capture global structural features by minimizing the distribution discrepancy between labeled and unlabeled samples in feature space. Yet, direct construction of features from unlabeled data frequently results in ``Sample Selection Bias'', leading to flawed supervision. We thus further propose the Dynamic Feature Pool (DFP) for the CCM, which utilizes a confidence-based filtering strategy to remove incorrectly selected features and regularize both teacher and student models by constraining the similarity matrix to be consistent. Extensive experiments on the Left Atrium dataset have shown that the proposed CORN outperforms previous state-of-the-art semi-supervised learning methods.