 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-CRITIC: A Holistic Evaluation of Large Multimodal Models as Multimodal Critique
Nov 12, 2025



The ability of critique is vital for models to self-improve and serve as reliable AI assistants. While extensively studied in language-only settings, multimodal critique of Large Multimodal Models (LMMs) remains underexplored despite their growing capabilities in tasks like captioning and visual reasoning. In this work, we introduce MM-CRITIC, a holistic benchmark for evaluating the critique ability of LMMs across multiple dimensions: basic, correction, and comparison. Covering 8 main task types and over 500 tasks, MM-CRITIC collects responses from various LMMs with different model sizes and is composed of 4471 samples. To enhance the evaluation reliability, we integrate expert-informed ground answers into scoring rubrics that guide GPT-4o in annotating responses and generating reference critiques, which serve as anchors for trustworthy judgments. Extensive experiments validate the effectiveness of MM-CRITIC and provide a comprehensive assessment of leading LMMs' critique capabilities under multiple dimensions. Further analysis reveals some key insights, including the correlation between response quality and critique, and varying critique difficulty across evaluation dimensions. Our code is available at https://github.com/MichealZeng0420/MM-Critic.
Hybrid Learning for Cold-Start-Aware Microservice Scheduling in Dynamic Edge Environments
May 28, 2025With the rapid growth of IoT devices and their diverse workloads, container-based microservices deployed at edge nodes have become a lightweight and scalable solution. However, existing microservice scheduling algorithms often assume static resource availability, which is unrealistic when multiple containers are assigned to an edge node. Besides, containers suffer from cold-start inefficiencies during early-stage training in currently popular reinforcement learning (RL) algorithms. In this paper, we propose a hybrid learning framework that combines offline imitation learning (IL) with online Soft Actor-Critic (SAC) optimization to enable a cold-start-aware microservice scheduling with dynamic allocation for computing resources. We first formulate a delay-and-energy-aware scheduling problem and construct a rule-based expert to generate demonstration data for behavior cloning. Then, a GRU-enhanced policy network is designed in the policy network to extract the correlation among multiple decisions by separately encoding slow-evolving node states and fast-changing microservice features, and an action selection mechanism is given to speed up the convergence. Extensive experiments show that our method significantly accelerates convergence and achieves superior final performance. Compared with baselines, our algorithm improves the total objective by $50\%$ and convergence speed by $70\%$, and demonstrates the highest stability and robustness across various edge configurations.
Empowering Edge Intelligence: A Comprehensive Survey on On-Device AI Models
Mar 08, 2025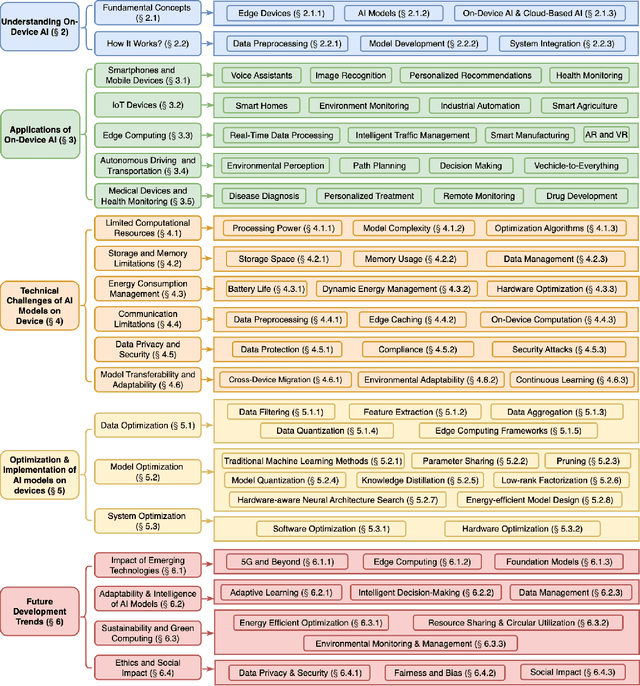



The rapid advancement of artificial intelligence (AI) technologies has led to an increasing deployment of AI models on edge and terminal devices, driven by the proliferation of the Internet of Things (IoT) and the need for real-time data processing. This survey comprehensively explores the current state, technical challenges, and future trends of on-device AI models. We define on-device AI models as those designed to perform local data processing and inference, emphasizing their characteristics such as real-time performance, resource constraints, and enhanced data privacy. The survey is structured around key themes, including the fundamental concepts of AI models, application scenarios across various domains, and the technical challenges faced in edge environments. We also discuss optimization and implementation strategies, such as data preprocessing, model compression, and hardware acceleration, which are essential for effective deployment. Furthermore, we examine the impact of emerging technologies, including edge computing and foundation models, on the evolution of on-device AI models. By providing a structured overview of the challenges, solutions, and future directions, this survey aims to facilitate further research and application of on-device AI, ultimately contributing to the advancement of intelligent systems in everyday life.
Accelerating AIGC Services with Latent Action Diffusion Scheduling in Edge Networks
Dec 24, 2024



Artificial Intelligence Generated Content (AIGC) has gained significant popularity for creating diverse content. Current AIGC models primarily focus on content quality within a centralized framework, resulting in a high service delay and negative user experiences. However, not only does the workload of an AIGC task depend on the AIGC model's complexity rather than the amount of data, but the large model and its multi-layer encoder structure also result in a huge demand for computational and memory resources. These unique characteristics pose new challenges in its modeling, deployment, and scheduling at edge networks. Thus, we model an offloading problem among edges for providing real AIGC services and propose LAD-TS, a novel Latent Action Diffusion-based Task Scheduling method that orchestrates multiple edge servers for expedited AIGC services. The LAD-TS generates a near-optimal offloading decision by leveraging the diffusion model's conditional generation capability and the reinforcement learning's environment interaction ability, thereby minimizing the service delays under multiple resource constraints. Meanwhile, a latent action diffusion strategy is designed to guide decision generation by utilizing historical action probability, enabling rapid achievement of near-optimal decisions. Furthermore, we develop DEdgeAI, a prototype edge system with a refined AIGC model deployment to implement and evaluate our LAD-TS method. DEdgeAI provides a real AIGC service for users, demonstrating up to 29.18% shorter service delays than the current five representative AIGC platforms. We release our open-source code at https://github.com/ChangfuXu/DEdgeAI/.
Online Influence Maximization: Concept and Algorithm
Nov 30, 2023In this survey, we offer an extensive overview of the Online Influence Maximization (IM) problem by covering both theoretical aspects and practical applications. For the integrity of the article and because the online algorithm takes an offline oracle as a subroutine, we first make a clear definition of the Offline IM problem and summarize those commonly used Offline IM algorithms, which include traditional approximation or heuristic algorithms and ML-based algorithms. Then, we give a standard definition of the Online IM problem and a basic Combinatorial Multi-Armed Bandit (CMAB) framework, CMAB-T. Here, we summarize three types of feedback in the CMAB model and discuss in detail how to study the Online IM problem based on the CMAB-T model. This paves the way for solving the Online IM problem by using online learning methods. Furthermore, we have covered almost all Online IM algorithms up to now, focusing on characteristics and theoretical guarantees of online algorithms for different feedback types. Here, we elaborately explain their working principle and how to obtain regret bounds. Besides, we also collect plenty of innovative ideas about problem definition and algorithm designs and pioneering works for variants of the Online IM problem and their corresponding algorithms. Finally, we encapsulate current challenges and outline prospective research directions from four distinct perspectives.
DSCom: A Data-Driven Self-Adaptive Community-Based Framework for Influence Maximization in Social Networks
Nov 18, 2023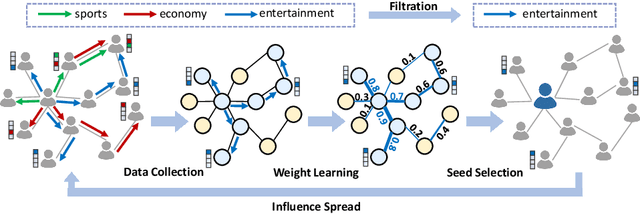
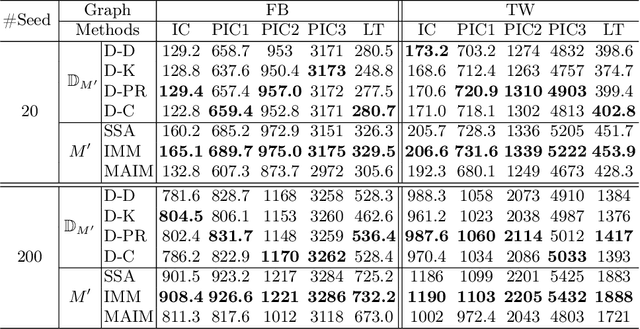
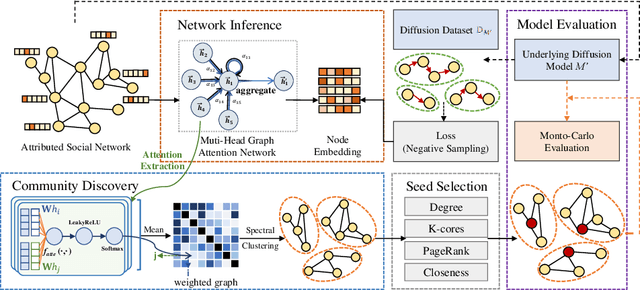

Influence maximization aims to find a subset of seeds that maximize the influence spread under a given budget. In this paper, we mainly address the data-driven version of this problem, where the diffusion model is not given but needs to be inferred from the history cascades. Several previous works have addressed this topic in a statistical way and provided efficient algorithms with theoretical guarantee. However, in their settings, though the diffusion parameters are inferred, they still need users to preset the diffusion model, which can be an intractable problem in real-world practices. In this paper, we reformulate the problem on the attributed network and leverage the node attributes to estimate the closeness between the connected nodes. Specifically, we propose a machine learning-based framework, named DSCom, to address this problem in a heuristic way. Under this framework, we first infer the users' relationship from the diffusion dataset through attention mechanism and then leverage spectral clustering to overcome the influence overlap problem in the lack of exact diffusion formula. Compared to the previous theoretical works, we carefully designed empirical experiments with parameterized diffusion models based on real-world social networks, which prove the efficiency and effectiveness of our algorithm.
A Modified EXP3 and Its Adaptive Variant in Adversarial Bandits with Multi-User Delayed Feedback
Oct 17, 2023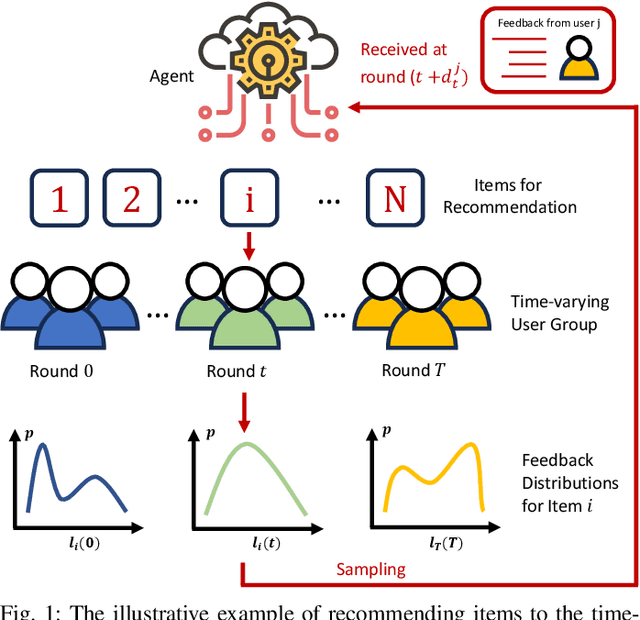
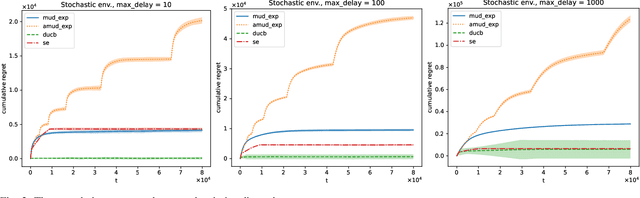
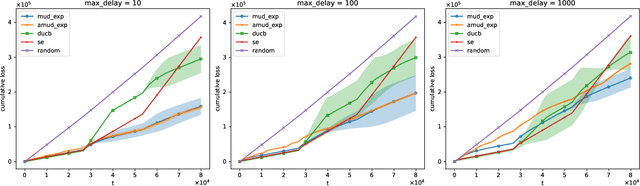
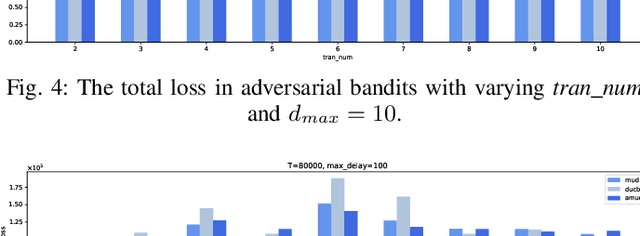
For the adversarial multi-armed bandit problem with delayed feedback, we consider that the delayed feedback results are from multiple users and are unrestricted on internal distribution. As the player picks an arm, feedback from multiple users may not be received instantly yet after an arbitrary delay of time which is unknown to the player in advance. For different users in a round, the delays in feedback have no latent correlation. Thus, we formulate an adversarial multi-armed bandit problem with multi-user delayed feedback and design a modified EXP3 algorithm named MUD-EXP3, which makes a decision at each round by considering the importance-weighted estimator of the received feedback from different users. On the premise of known terminal round index $T$, the number of users $M$, the number of arms $N$, and upper bound of delay $d_{max}$, we prove a regret of $\mathcal{O}(\sqrt{TM^2\ln{N}(N\mathrm{e}+4d_{max})})$. Furthermore, for the more common case of unknown $T$, an adaptive algorithm named AMUD-EXP3 is proposed with a sublinear regret with respect to $T$. Finally, extensive experiments are conducted to indicate the correctness and effectiveness of our algorithms.
A Fast Task Offloading Optimization Framework for IRS-Assisted Multi-Access Edge Computing System
Jul 17, 2023Terahertz communication networks and intelligent reflecting surfaces exhibit significant potential in advancing wireless networks, particularly within the domain of aerial-based multi-access edge computing systems. These technologies enable efficient offloading of computational tasks from user electronic devices to Unmanned Aerial Vehicles or local execution. For the generation of high-quality task-offloading allocations, conventional numerical optimization methods often struggle to solve challenging combinatorial optimization problems within the limited channel coherence time, thereby failing to respond quickly to dynamic changes in system conditions. To address this challenge, we propose a deep learning-based optimization framework called Iterative Order-Preserving policy Optimization (IOPO), which enables the generation of energy-efficient task-offloading decisions within milliseconds. Unlike exhaustive search methods, IOPO provides continuous updates to the offloading decisions without resorting to exhaustive search, resulting in accelerated convergence and reduced computational complexity, particularly when dealing with complex problems characterized by extensive solution spaces. Experimental results demonstrate that the proposed framework can generate energy-efficient task-offloading decisions within a very short time period, outperforming other benchmark methods.
FedCL: Federated Multi-Phase Curriculum Learning to Synchronously Correlate User Heterogeneity
Nov 14, 2022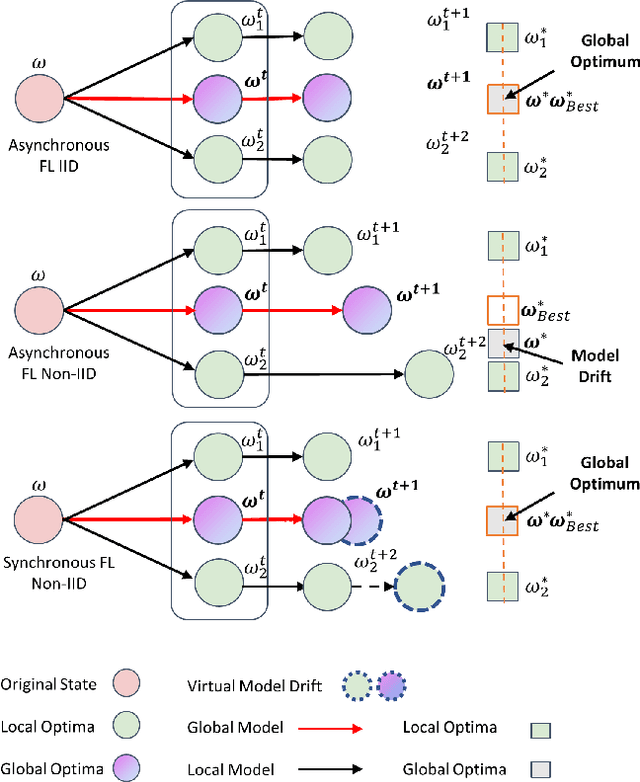

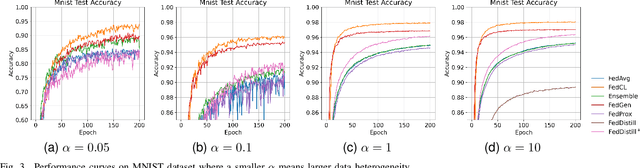

Federated Learning (FL) is a new decentralized learning used for training machine learning algorithms where a global model iteratively gathers the parameters of local models but does not access their local data. A key challenge in FL is to handle the heterogeneity of local data distribution, resulting in a drifted global model, which is hard to converge. To cope with this challenge, current methods adopt different strategies like knowledge distillation, weighted model aggregation, and multi-task learning, as regulation. We refer to these approaches as asynchronous FL since they align user models in either a local or post-hoc manner where model drift has already happened or has been underestimated. In this paper, we propose an active and synchronous correlation approach to solve the challenge of user heterogeneity in FL. Specifically, we aim to approximate FL as the standard deep learning by actively and synchronously scheduling user learning pace in each round with a dynamic multi-phase curriculum. A global curriculum ensembles all user curriculum on its server by the auto-regressive auto-encoder. Then the global curriculum is divided into multiple phases and broadcast to users to measure and align the domain-agnostic learning pace. Empirical studies demonstrate that our approach equips FL with state-of-the-art generalization performance over existing asynchronous approaches, even facing severe user heterogeneity.
A Survey on Influence Maximization: From an ML-Based Combinatorial Optimization
Nov 06, 2022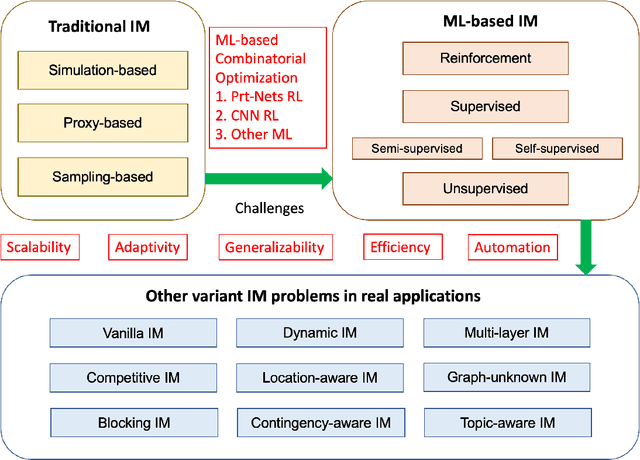
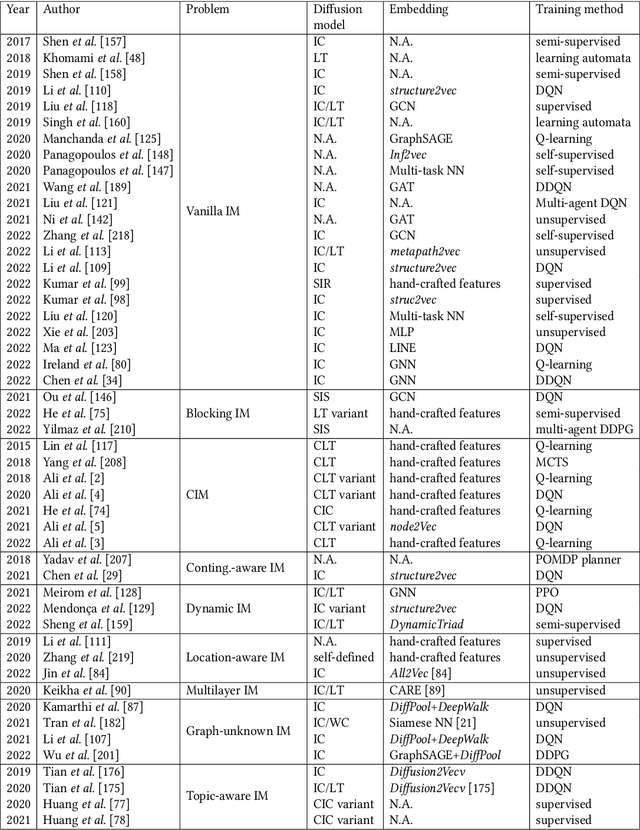
Influence Maximization (IM) is a classical combinatorial optimization problem, which can be widely used in mobile networks, social computing, and recommendation systems. It aims at selecting a small number of users such that maximizing the influence spread across the online social network. Because of its potential commercial and academic value, there are a lot of researchers focusing on studying the IM problem from different perspectives. The main challenge comes from the NP-hardness of the IM problem and \#P-hardness of estimating the influence spread, thus traditional algorithms for overcoming them can be categorized into two classes: heuristic algorithms and approximation algorithms. However, there is no theoretical guarantee for heuristic algorithms, and the theoretical design is close to the limit. Therefore, it is almost impossible to further optimize and improve their performance. With the rapid development of artificial intelligence, the technology based on Machine Learning (ML) has achieved remarkable achievements in many fields. In view of this, in recent years, a number of new methods have emerged to solve combinatorial optimization problems by using ML-based techniques. These methods have the advantages of fast solving speed and strong generalization ability to unknown graphs, which provide a brand-new direction for solving combinatorial optimization problems. Therefore, we abandon the traditional algorithms based on iterative search and review the recent development of ML-based methods, especially Deep Reinforcement Learning, to solve the IM problem and other variants in social networks. We focus on summarizing the relevant background knowledge, basic principles, common methods, and applied research. Finally, the challenges that need to be solved urgently in future IM research are pointed out.