 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^3$-Impute: Mask-guided Representation Learning for Missing Value Imputation
Oct 11, 2024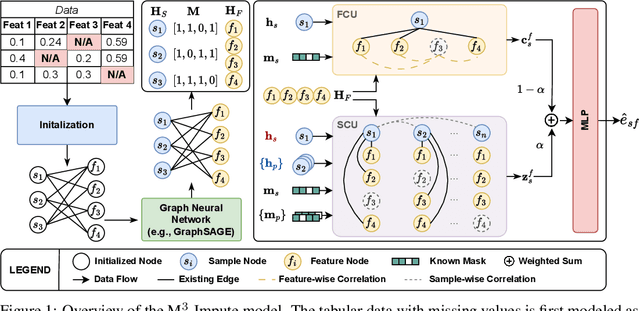
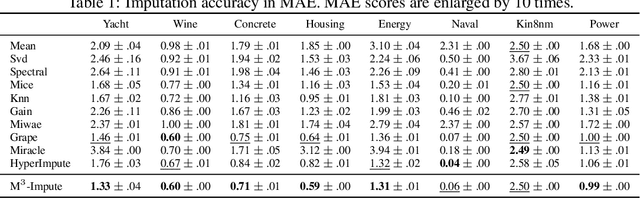
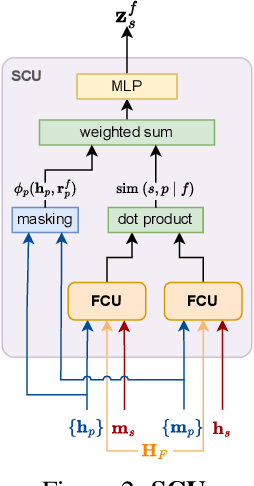
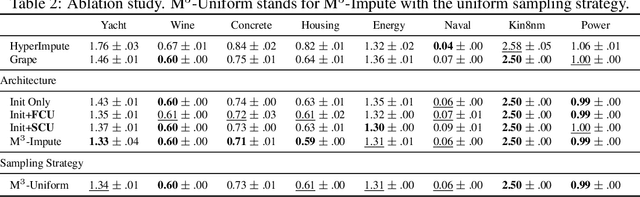
Missing values are a common problem that poses significant challenges to data analysis and machine learning. This problem necessitates the development of an effective imputation method to fill in the missing values accurately, thereby enhancing the overall quality and utility of the datasets. Existing imputation methods, however, fall short of explicitly considering the `missingness' information in the data during the embedding initialization stage and modeling the entangled feature and sample correlations during the learning process, thus leading to inferior performance. We propose M$^3$-Impute, which aims to explicitly leverage the missingness information and such correlations with novel masking schemes. M$^3$-Impute first models the data as a bipartite graph and uses a graph neural network to learn node embeddings, where the refined embedding initialization process directly incorporates the missingness information. They are then optimized through M$^3$-Impute's novel feature correlation unit (FRU) and sample correlation unit (SRU) that effectively captures feature and sample correlations for imputation. Experiment results on 25 benchmark datasets under three different missingness settings show the effectiveness of M$^3$-Impute by achieving 20 best and 4 second-best MAE scores on average.
A Fast Task Offloading Optimization Framework for IRS-Assisted Multi-Access Edge Computing System
Jul 17, 2023Terahertz communication networks and intelligent reflecting surfaces exhibit significant potential in advancing wireless networks, particularly within the domain of aerial-based multi-access edge computing systems. These technologies enable efficient offloading of computational tasks from user electronic devices to Unmanned Aerial Vehicles or local execution. For the generation of high-quality task-offloading allocations, conventional numerical optimization methods often struggle to solve challenging combinatorial optimization problems within the limited channel coherence time, thereby failing to respond quickly to dynamic changes in system conditions. To address this challenge, we propose a deep learning-based optimization framework called Iterative Order-Preserving policy Optimization (IOPO), which enables the generation of energy-efficient task-offloading decisions within milliseconds. Unlike exhaustive search methods, IOPO provides continuous updates to the offloading decisions without resorting to exhaustive search, resulting in accelerated convergence and reduced computational complexity, particularly when dealing with complex problems characterized by extensive solution spaces. Experimental results demonstrate that the proposed framework can generate energy-efficient task-offloading decisions within a very short time period, outperforming other benchmark methods.
Improving User Controlled Table-To-Text Generation Robustness
Feb 20, 2023



In this work we study user controlled table-to-text generation where users explore the content in a table by selecting cells and reading a natural language description thereof automatically produce by a natural language generator. Such generation models usually learn from carefully selected cell combinations (clean cell selections); however, in practice users may select unexpected, redundant, or incoherent cell combinations (noisy cell selections). In experiments, we find that models perform well on test sets coming from the same distribution as the train data but their performance drops when evaluated on realistic noisy user inputs. We propose a fine-tuning regime with additional user-simulated noisy cell selections. Models fine-tuned with the proposed regime gain 4.85 BLEU points on user noisy test cases and 1.4 on clean test cases; and achieve comparable state-of-the-art performance on the ToTTo dataset.
LenAtten: An Effective Length Controlling Unit For Text Summarization
Jun 01, 2021
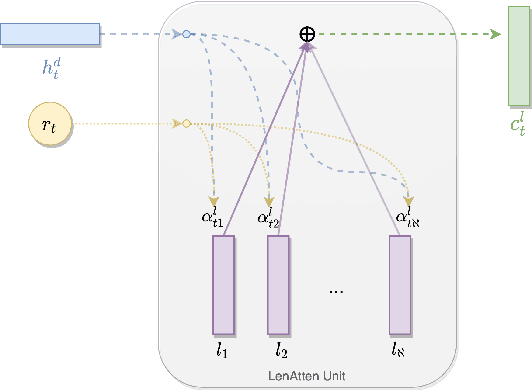
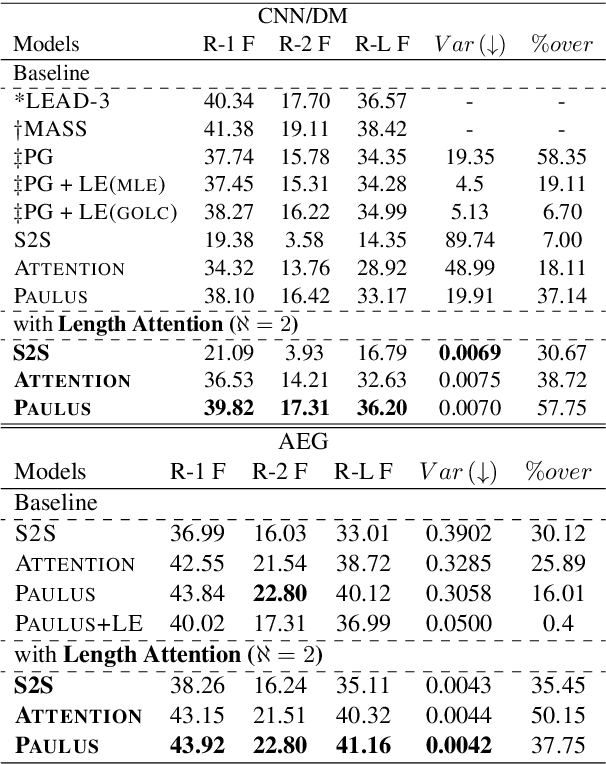
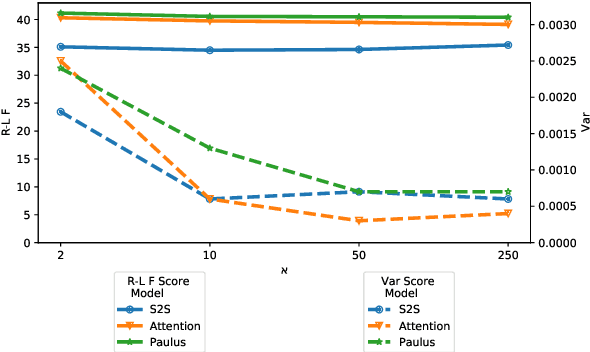
Fixed length summarization aims at generating summaries with a preset number of words or characters. Most recent researches incorporate length information with word embeddings as the input to the recurrent decoding unit, causing a compromise between length controllability and summary quality. In this work, we present an effective length controlling unit Length Attention (LenAtten) to break this trade-off. Experimental results show that LenAtten not only brings improvements in length controllability and ROGUE scores but also has great generalization ability. In the task of generating a summary with the target length, our model is 732 times better than the best-performing length controllable summarizer in length controllability on the CNN/Daily Mail dataset.