 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Elicits Contextual Learning of Unseen Language Translation
Jun 04, 2026Prior work has shown that large language models (LLMs) can translate unseen or low-resource languages by undergoing continued training or even by encoding a grammar book in their context. However, both methods typically overfit specific languages, with limited zero-shot transfer at test time. To translate extremely low-resource languages at scale, we argue that LLMs must acquire the meta-skill of utilizing in-context linguistic knowledge rather than memorizing specific languages. In this paper, we propose a reinforcement learning (RL) approach to unseen language translation given rich linguistic context, using a surface-level translation metric (chrF) as the reward. Empirically, despite the lightweight reward, our RL-trained models effectively extract and apply relevant linguistic information from the provided context, leading to better translations on completely unseen languages than in-context learning or supervised fine-tuning. Our analyses suggest that outcome-based RL can extend beyond conventional reasoning tasks like math and coding to serve as a recipe for language learning from context.
DeReason: A Difficulty-Aware Curriculum Improves Decoupled SFT-then-RL Training for General Reasoning
Mar 11, 2026Reinforcement learning with Verifiable Rewards (RLVR) has emerged as a powerful paradigm for eliciting reasoning capabilities in large language models, particularly in mathematics and coding. While recent efforts have extended this paradigm to broader general scientific (STEM) domains, the complex interplay between supervised fine-tuning (SFT) and RL in these contexts remains underexplored. In this paper, we conduct controlled experiments revealing a critical challenge: for general STEM domains, RL applied directly to base models is highly sample-inefficient and is consistently surpassed by supervised fine-tuning (SFT) on moderate-quality responses. Yet sequential SFT followed by RL can further improve performance, suggesting that the two stages play complementary roles, and that how training data is allocated between them matters. Therefore, we propose DeReason, a difficulty-based data decoupling strategy for general reasoning. DeReason partitions training data by reasoning intensity estimated via LLM-based scoring into reasoning-intensive and non-reasoning-intensive subsets. It allocates broad-coverage, non-reasoning-intensive problems to SFT to establish foundational domain knowledge, and reserves a focused subset of difficult problems for RL to cultivate complex reasoning. We demonstrate that this principled decoupling yields better performance than randomly splitting the data for sequential SFT and RL. Extensive experiments on general STEM and mathematical benchmarks demonstrate that our decoupled curriculum training significantly outperforms SFT-only, RL-only, and random-split baselines. Our work provides a systematic study of the interplay between SFT and RL for general reasoning, offering a highly effective and generalized post-training recipe.
LNE-Blocking: An Efficient Framework for Contamination Mitigation Evaluation on Large Language Models
Sep 18, 2025The problem of data contamination is now almost inevitable during the development of large language models (LLMs), with the training data commonly integrating those evaluation benchmarks even unintentionally. This problem subsequently makes it hard to benchmark LLMs fairly. Instead of constructing contamination-free datasets (quite hard), we propose a novel framework, \textbf{LNE-Blocking}, to restore model performance prior to contamination on potentially leaked datasets. Our framework consists of two components: contamination detection and disruption operation. For the prompt, the framework first uses the contamination detection method, \textbf{LNE}, to assess the extent of contamination in the model. Based on this, it adjusts the intensity of the disruption operation, \textbf{Blocking}, to elicit non-memorized responses from the model. Our framework is the first to efficiently restore the model's greedy decoding performance. This comes with a strong performance on multiple datasets with potential leakage risks, and it consistently achieves stable recovery results across different models and varying levels of data contamination. We release the code at https://github.com/RuijieH/LNE-Blocking to facilitate research.
CHARM: Calibrating Reward Models With Chatbot Arena Scores
Apr 14, 2025Reward models (RMs) play a crucial role in Reinforcement Learning from Human Feedback by serving as proxies for human preferences in aligning large language models. In this paper, we identify a model preference bias in RMs, where they systematically assign disproportionately high scores to responses from certain policy models. This bias distorts ranking evaluations and leads to unfair judgments. To address this issue, we propose a calibration method named CHatbot Arena calibrated Reward Modeling (CHARM) that leverages Elo scores from the Chatbot Arena leaderboard to mitigate RM overvaluation. We also introduce a Mismatch Degree metric to measure this preference bias. Our approach is computationally efficient, requiring only a small preference dataset for continued training of the RM. We conduct extensive experiments on reward model benchmarks and human preference alignment. Results demonstrate that our calibrated RMs (1) achieve improved evaluation accuracy on RM-Bench and the Chat-Hard domain of RewardBench, and (2) exhibit a stronger correlation with human preferences by producing scores more closely aligned with Elo rankings. By mitigating model preference bias, our method provides a generalizable and efficient solution for building fairer and more reliable reward models.
Source-primed Multi-turn Conversation Helps Large Language Models Translate Documents
Mar 13, 2025LLMs have paved the way for truly simple document-level machine translation, but challenges such as omission errors remain. In this paper, we study a simple method for handling document-level machine translation, by leveraging previous contexts in a multi-turn conversational manner. Specifically, by decomposing documents into segments and iteratively translating them while maintaining previous turns, this method ensures coherent translations without additional training, and can fully re-use the KV cache of previous turns thus minimizing computational overhead. We further propose a `source-primed' method that first provides the whole source document before multi-turn translation. We empirically show this multi-turn method outperforms both translating entire documents in a single turn and translating each segment independently according to multiple automatic metrics in representative LLMs, establishing a strong baseline for document-level translation using LLMs.
Generalizing From Short to Long: Effective Data Synthesis for Long-Context Instruction Tuning
Feb 21, 2025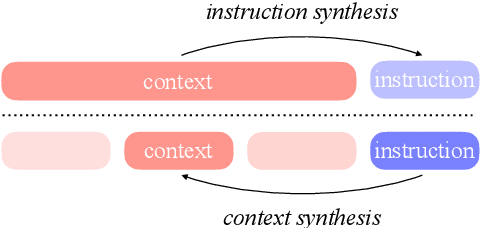

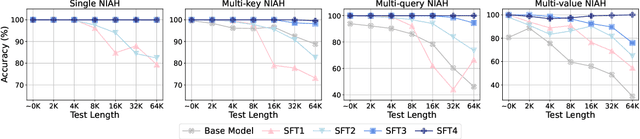
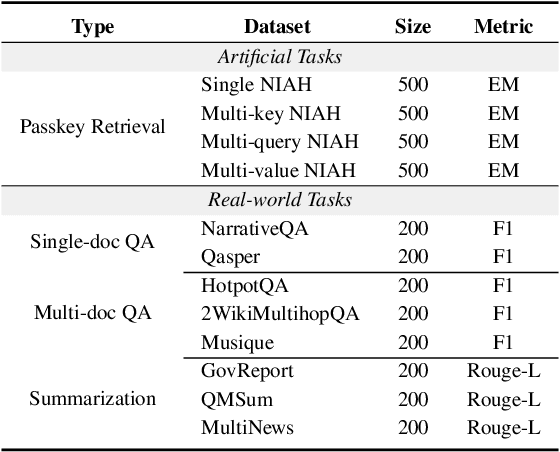
Long-context modelling for large language models (LLMs) has been a key area of recent research because many real world use cases require reasoning over longer inputs such as documents. The focus of research into modelling long context has been on how to model position and there has been little investigation into other important aspects of language modelling such as instruction tuning. Long context training examples are challenging and expensive to create and use. In this paper, we investigate how to design instruction data for the post-training phase of a long context pre-trained model: how much and what type of context is needed for optimal and efficient post-training. Our controlled study reveals that models instruction-tuned on short contexts can effectively generalize to longer ones, while also identifying other critical factors such as instruction difficulty and context composition. Based on these findings, we propose context synthesis, a novel data synthesis framework that leverages off-the-shelf LLMs to generate extended background contexts for high-quality instruction-answer pairs. Experiment results on the document-level benchmark (LongBench) demonstrate that our proposed approach outperforms previous instruction synthesis approaches and comes close to the performance of human-annotated long-context instruction data. The project will be available at: https://github.com/NJUNLP/context-synthesis.
BenchMAX: A Comprehensive Multilingual Evaluation Suite for Large Language Models
Feb 11, 2025Previous multilingual benchmarks focus primarily on simple understanding tasks, but for large language models(LLMs), we emphasize proficiency in instruction following, reasoning, long context understanding, code generation, and so on. However, measuring these advanced capabilities across languages is underexplored. To address the disparity, we introduce BenchMAX, a multi-way multilingual evaluation benchmark that allows for fair comparisons of these important abilities across languages. To maintain high quality, three distinct native-speaking annotators independently annotate each sample within all tasks after the data was machine-translated from English into 16 other languages. Additionally, we present a novel translation challenge stemming from dataset construction. Extensive experiments on BenchMAX reveal varying effectiveness of core capabilities across languages, highlighting performance gaps that cannot be bridged by simply scaling up model size. BenchMAX serves as a comprehensive multilingual evaluation platform, providing a promising test bed to promote the development of multilingual language models. The dataset and code are publicly accessible.
Fine-tuning Large Language Models with Sequential Instructions
Mar 12, 2024



Large language models (LLMs) struggle to follow a sequence of instructions in a single query as they may ignore or misinterpret part of it. This impairs their performance in complex problems whose solution requires multiple intermediate steps, such as multilingual (translate then answer) and multimodal (caption then answer) tasks. We empirically verify this with open-source LLMs as large as LLaMA-2 70B and Mixtral-8x7B. Targeting the scarcity of sequential instructions in present-day data, we propose sequential instruction tuning, a simple yet effective strategy to automatically augment instruction tuning data and equip LLMs with the ability to execute multiple sequential instructions. After exploring interleaving instructions in existing datasets, such as Alpaca, with a wide range of intermediate tasks, we find that sequential instruction-tuned models consistently outperform the conventional instruction-tuned baselines in downstream tasks involving reasoning, multilingual, and multimodal abilities. To shed further light on our technique, we analyse how adversarial intermediate texts, unseen tasks, prompt verbalization, number of tasks, and prompt length affect SIT. We hope that this method will open new research avenues on instruction tuning for complex tasks.
CLEAN-EVAL: Clean Evaluation on Contaminated Large Language Models
Nov 15, 2023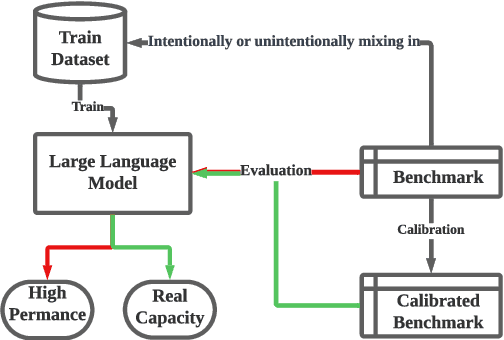
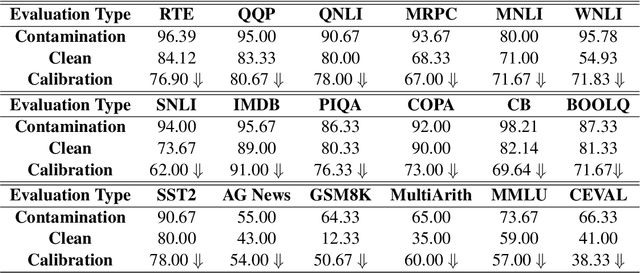
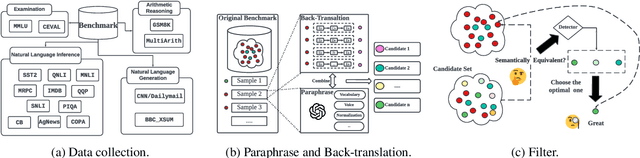

We are currently in an era of fierce competition among various large language models (LLMs) continuously pushing the boundaries of benchmark performance. However, genuinely assessing the capabilities of these LLMs has become a challenging and critical issue due to potential data contamination, and it wastes dozens of time and effort for researchers and engineers to download and try those contaminated models. To save our precious time, we propose a novel and useful method, Clean-Eval, which mitigates the issue of data contamination and evaluates the LLMs in a cleaner manner. Clean-Eval employs an LLM to paraphrase and back-translate the contaminated data into a candidate set, generating expressions with the same meaning but in different surface forms. A semantic detector is then used to filter the generated low-quality samples to narrow down this candidate set. The best candidate is finally selected from this set based on the BLEURT score. According to human assessment, this best candidate is semantically similar to the original contamination data but expressed differently. All candidates can form a new benchmark to evaluate the model. Our experiments illustrate that Clean-Eval substantially restores the actual evaluation results on contaminated LLMs under both few-shot learning and fine-tuning scenarios.
Meta-Learning For Vision-and-Language Cross-lingual Transfer
May 24, 2023Current pre-trained vison-language models (PVLMs) achieve excellent performance on a range of multi-modal datasets. Recent work has aimed at building multilingual models, and a range of novel multilingual multi-modal datasets have been proposed. Current PVLMs typically perform poorly on these datasets when used for multi-modal zero-shot or few-shot cross-lingual transfer, especially for low-resource languages. To alleviate this problem, we propose a novel meta-learning fine-tuning framework. Our framework makes current PVLMs rapidly adaptive to new languages in vision-language scenarios by designing MAML in a cross-lingual multi-modal manner. Experiments show that our method boosts the performance of current state-of-the-art PVLMs in both zero-shot and few-shot cross-lingual transfer on a range of vision-language understanding tasks and datasets (XVNLI, xGQA, MaRVL, xFlicker&Co