 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCould Thinking Multilingually Empower LLM Reasoning?
Apr 16, 2025Previous work indicates that large language models exhibit a significant "English bias", i.e. they often perform better when tasks are presented in English. Interestingly, we have observed that using certain other languages in reasoning tasks can yield better performance than English. However, this phenomenon remains under-explored. In this paper, we explore the upper bound of harnessing multilingualism in reasoning tasks, suggesting that multilingual reasoning promises significantly (by nearly 10 Acc@$k$ points) and robustly (tolerance for variations in translation quality and language choice) higher upper bounds than English-only reasoning. Besides analyzing the reason behind the upper bound and challenges in reaching it, we also find that common answer selection methods cannot achieve this upper bound, due to their limitations and biases. These insights could pave the way for future research aimed at fully harnessing the potential of multilingual reasoning in LLMs.
Generalizing From Short to Long: Effective Data Synthesis for Long-Context Instruction Tuning
Feb 21, 2025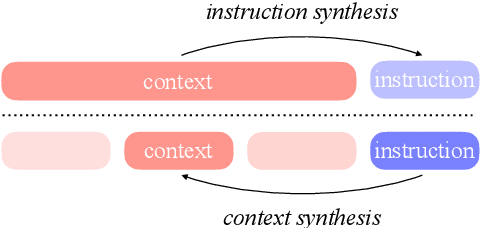

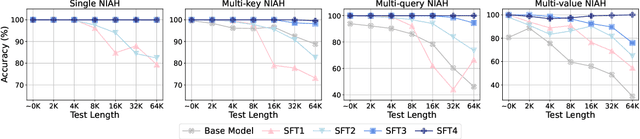
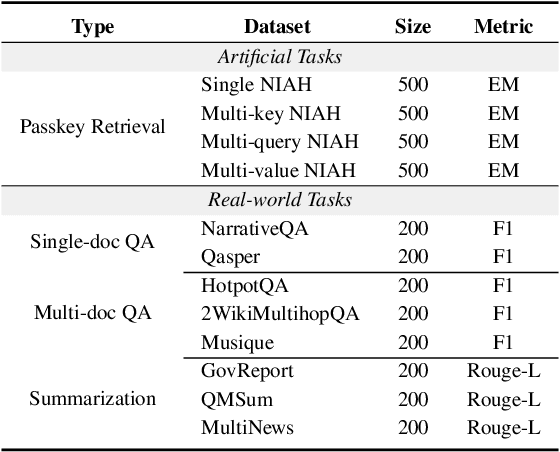
Long-context modelling for large language models (LLMs) has been a key area of recent research because many real world use cases require reasoning over longer inputs such as documents. The focus of research into modelling long context has been on how to model position and there has been little investigation into other important aspects of language modelling such as instruction tuning. Long context training examples are challenging and expensive to create and use. In this paper, we investigate how to design instruction data for the post-training phase of a long context pre-trained model: how much and what type of context is needed for optimal and efficient post-training. Our controlled study reveals that models instruction-tuned on short contexts can effectively generalize to longer ones, while also identifying other critical factors such as instruction difficulty and context composition. Based on these findings, we propose context synthesis, a novel data synthesis framework that leverages off-the-shelf LLMs to generate extended background contexts for high-quality instruction-answer pairs. Experiment results on the document-level benchmark (LongBench) demonstrate that our proposed approach outperforms previous instruction synthesis approaches and comes close to the performance of human-annotated long-context instruction data. The project will be available at: https://github.com/NJUNLP/context-synthesis.
BenchMAX: A Comprehensive Multilingual Evaluation Suite for Large Language Models
Feb 11, 2025Previous multilingual benchmarks focus primarily on simple understanding tasks, but for large language models(LLMs), we emphasize proficiency in instruction following, reasoning, long context understanding, code generation, and so on. However, measuring these advanced capabilities across languages is underexplored. To address the disparity, we introduce BenchMAX, a multi-way multilingual evaluation benchmark that allows for fair comparisons of these important abilities across languages. To maintain high quality, three distinct native-speaking annotators independently annotate each sample within all tasks after the data was machine-translated from English into 16 other languages. Additionally, we present a novel translation challenge stemming from dataset construction. Extensive experiments on BenchMAX reveal varying effectiveness of core capabilities across languages, highlighting performance gaps that cannot be bridged by simply scaling up model size. BenchMAX serves as a comprehensive multilingual evaluation platform, providing a promising test bed to promote the development of multilingual language models. The dataset and code are publicly accessible.
WanJuanSiLu: A High-Quality Open-Source Webtext Dataset for Low-Resource Languages
Jan 24, 2025



This paper introduces the open-source dataset WanJuanSiLu, designed to provide high-quality training corpora for low-resource languages, thereby advancing the research and development of multilingual models. To achieve this, we have developed a systematic data processing framework tailored for low-resource languages. This framework encompasses key stages such as data extraction, corpus cleaning, content deduplication, security filtering, quality evaluation, and theme classification. Through the implementation of this framework, we have significantly improved both the quality and security of the dataset, while maintaining its linguistic diversity. As of now, data for all five languages have been fully open-sourced. The dataset can be accessed at https://opendatalab.com/applyMultilingualCorpus, and GitHub repository is available at https://github.com/opendatalab/WanJuan3.0
A Chinese Continuous Sign Language Dataset Based on Complex Environments
Sep 18, 2024
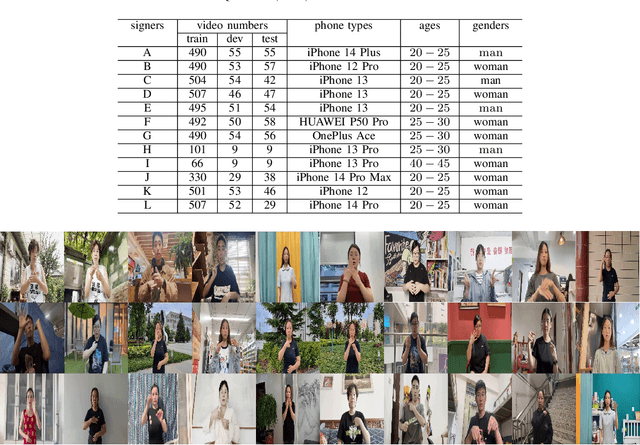
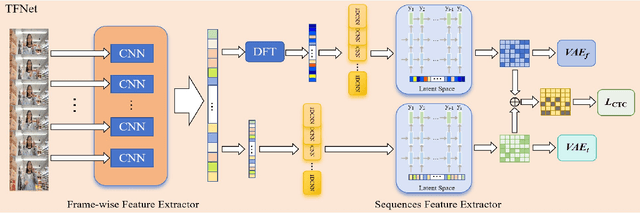
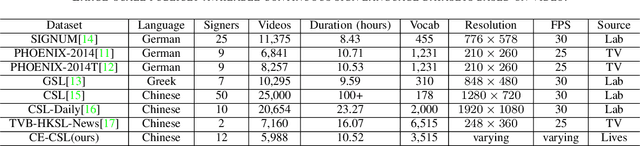
The current bottleneck in continuous sign language recognition (CSLR) research lies in the fact that most publicly available datasets are limited to laboratory environments or television program recordings, resulting in a single background environment with uniform lighting, which significantly deviates from the diversity and complexity found in real-life scenarios. To address this challenge, we have constructed a new, large-scale dataset for Chinese continuous sign language (CSL) based on complex environments, termed the complex environment - chinese sign language dataset (CE-CSL). This dataset encompasses 5,988 continuous CSL video clips collected from daily life scenes, featuring more than 70 different complex backgrounds to ensure representativeness and generalization capability. To tackle the impact of complex backgrounds on CSLR performance, we propose a time-frequency network (TFNet) model for continuous sign language recognition. This model extracts frame-level features and then utilizes both temporal and spectral information to separately derive sequence features before fusion, aiming to achieve efficient and accurate CSLR. Experimental results demonstrate that our approach achieves significant performance improvements on the CE-CSL, validating its effectiveness under complex background conditions. Additionally, our proposed method has also yielded highly competitive results when applied to three publicly available CSL datasets.
A Controlled Study on Long Context Extension and Generalization in LLMs
Sep 18, 2024



Broad textual understanding and in-context learning require language models that utilize full document contexts. Due to the implementation challenges associated with directly training long-context models, many methods have been proposed for extending models to handle long contexts. However, owing to differences in data and model classes, it has been challenging to compare these approaches, leading to uncertainty as to how to evaluate long-context performance and whether it differs from standard evaluation. We implement a controlled protocol for extension methods with a standardized evaluation, utilizing consistent base models and extension data. Our study yields several insights into long-context behavior. First, we reaffirm the critical role of perplexity as a general-purpose performance indicator even in longer-context tasks. Second, we find that current approximate attention methods systematically underperform across long-context tasks. Finally, we confirm that exact fine-tuning based methods are generally effective within the range of their extension, whereas extrapolation remains challenging. All codebases, models, and checkpoints will be made available open-source, promoting transparency and facilitating further research in this critical area of AI development.
LLaMAX: Scaling Linguistic Horizons of LLM by Enhancing Translation Capabilities Beyond 100 Languages
Jul 08, 2024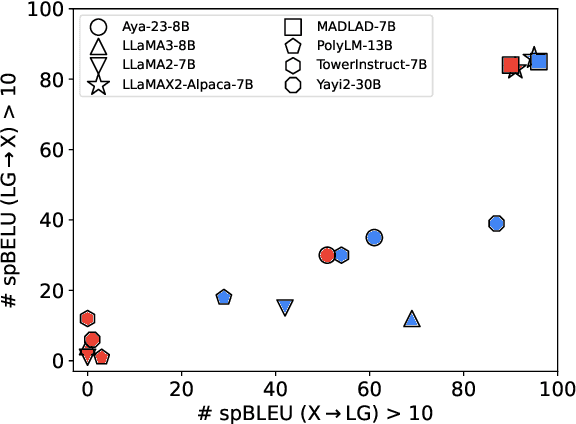
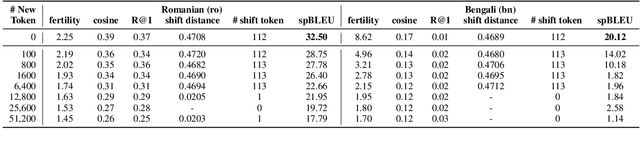
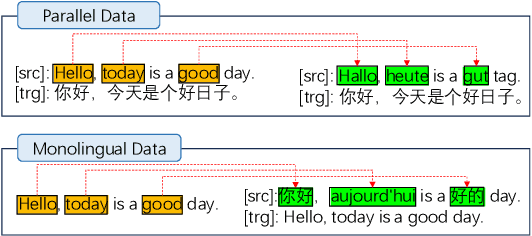
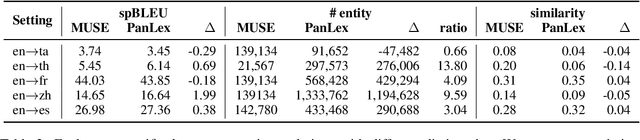
Large Language Models~(LLMs) demonstrate remarkable translation capabilities in high-resource language tasks, yet their performance in low-resource languages is hindered by insufficient multilingual data during pre-training. To address this, we dedicate 35,000 A100-SXM4-80GB GPU hours in conducting extensive multilingual continual pre-training on the LLaMA series models, enabling translation support across more than 100 languages. Through a comprehensive analysis of training strategies, such as vocabulary expansion and data augmentation, we develop LLaMAX. Remarkably, without sacrificing its generalization ability, LLaMAX achieves significantly higher translation performance compared to existing open-source LLMs~(by more than 10 spBLEU points) and performs on-par with specialized translation model~(M2M-100-12B) on the Flores-101 benchmark. Extensive experiments indicate that LLaMAX can serve as a robust multilingual foundation model. The code~\footnote{\url{https://github.com/CONE-MT/LLaMAX/.}} and models~\footnote{\url{https://huggingface.co/LLaMAX/.}} are publicly available.
MindMerger: Efficient Boosting LLM Reasoning in non-English Languages
May 27, 2024Reasoning capabilities are crucial for Large Language Models (LLMs), yet a notable gap exists between English and non-English languages. To bridge this disparity, some works fine-tune LLMs to relearn reasoning capabilities in non-English languages, while others replace non-English inputs with an external model's outputs such as English translation text to circumvent the challenge of LLM understanding non-English. Unfortunately, these methods often underutilize the built-in skilled reasoning and useful language understanding capabilities of LLMs. In order to better utilize the minds of reasoning and language understanding in LLMs, we propose a new method, namely MindMerger, which merges LLMs with the external language understanding capabilities from multilingual models to boost the multilingual reasoning performance. Furthermore, a two-step training scheme is introduced to first train to embeded the external capabilities into LLMs and then train the collaborative utilization of the external capabilities and the built-in capabilities in LLMs. Experiments on three multilingual reasoning datasets and a language understanding dataset demonstrate that MindMerger consistently outperforms all baselines, especially in low-resource languages. Without updating the parameters of LLMs, the average accuracy improved by 6.7% and 8.0% across all languages and low-resource languages on the MGSM dataset, respectively.
The Power of Question Translation Training in Multilingual Reasoning: Broadened Scope and Deepened Insights
May 02, 2024
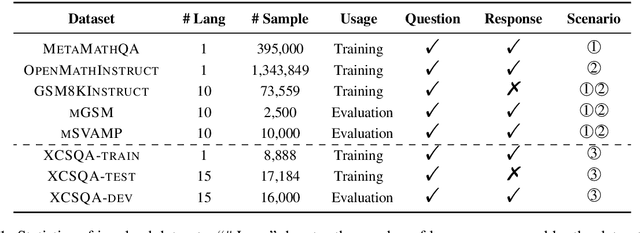


Bridging the significant gap between large language model's English and non-English performance presents a great challenge. While some previous studies attempt to mitigate this gap with translated training data, the recently proposed question alignment approach leverages the model's English expertise to improve multilingual performance with minimum usage of expensive, error-prone translation. In this paper, we explore how broadly this method can be applied by examining its effects in reasoning with executable code and reasoning with common sense. We also explore how to apply this approach efficiently to extremely large language models using proxy-tuning. Experiment results on multilingual reasoning benchmarks mGSM, mSVAMP and xCSQA demonstrate that the question alignment approach can be used to boost multilingual performance across diverse reasoning scenarios, model families, and sizes. For instance, when applied to the LLaMA2 models, our method brings an average accuracy improvements of 12.2% on mGSM even with the 70B model. To understand the mechanism of its success, we analyze representation space, chain-of-thought and translation data scales, which reveals how question translation training strengthens language alignment within LLMs and shapes their working patterns.
A Survey of Neural Code Intelligence: Paradigms, Advances and Beyond
Mar 21, 2024Neural Code Intelligence -- leveraging deep learning to understand, generate, and optimize code -- holds immense potential for transformative impacts on the whole society. Bridging the gap between Natural Language and Programming Language, this domain has drawn significant attention from researchers in both research communities over the past few years. This survey presents a systematic and chronological review of the advancements in code intelligence, encompassing over 50 representative models and their variants, more than 20 categories of tasks, and an extensive coverage of over 680 related works. We follow the historical progression to trace the paradigm shifts across different research phases (e.g., from modeling code with recurrent neural networks to the era of Large Language Models). Concurrently, we highlight the major technical transitions in models, tasks, and evaluations spanning through different stages. For applications, we also observe a co-evolving shift. It spans from initial endeavors to tackling specific scenarios, through exploring a diverse array of tasks during its rapid expansion, to currently focusing on tackling increasingly complex and varied real-world challenges. Building on our examination of the developmental trajectories, we further investigate the emerging synergies between code intelligence and broader machine intelligence, uncovering new cross-domain opportunities and illustrating the substantial influence of code intelligence across various domains. Finally, we delve into both the opportunities and challenges associated with this field, alongside elucidating our insights on the most promising research directions. An ongoing, dynamically updated project and resources associated with this survey have been released at https://github.com/QiushiSun/NCISurvey.