 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Chinese Continuous Sign Language Dataset Based on Complex Environments
Paper and Code

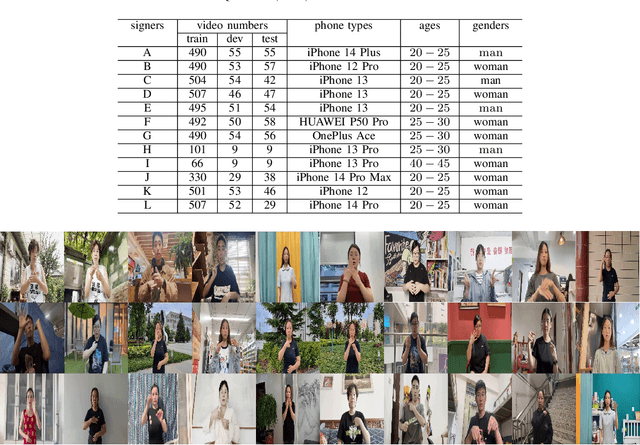
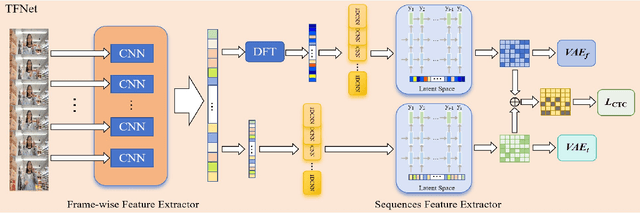
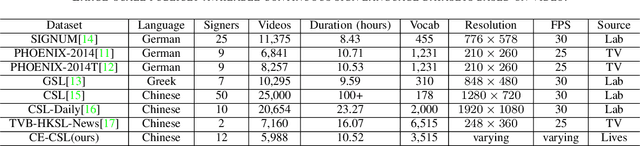
The current bottleneck in continuous sign language recognition (CSLR) research lies in the fact that most publicly available datasets are limited to laboratory environments or television program recordings, resulting in a single background environment with uniform lighting, which significantly deviates from the diversity and complexity found in real-life scenarios. To address this challenge, we have constructed a new, large-scale dataset for Chinese continuous sign language (CSL) based on complex environments, termed the complex environment - chinese sign language dataset (CE-CSL). This dataset encompasses 5,988 continuous CSL video clips collected from daily life scenes, featuring more than 70 different complex backgrounds to ensure representativeness and generalization capability. To tackle the impact of complex backgrounds on CSLR performance, we propose a time-frequency network (TFNet) model for continuous sign language recognition. This model extracts frame-level features and then utilizes both temporal and spectral information to separately derive sequence features before fusion, aiming to achieve efficient and accurate CSLR. Experimental results demonstrate that our approach achieves significant performance improvements on the CE-CSL, validating its effectiveness under complex background conditions. Additionally, our proposed method has also yielded highly competitive results when applied to three publicly available CSL datasets.