 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Chinese Continuous Sign Language Dataset Based on Complex Environments
Sep 18, 2024
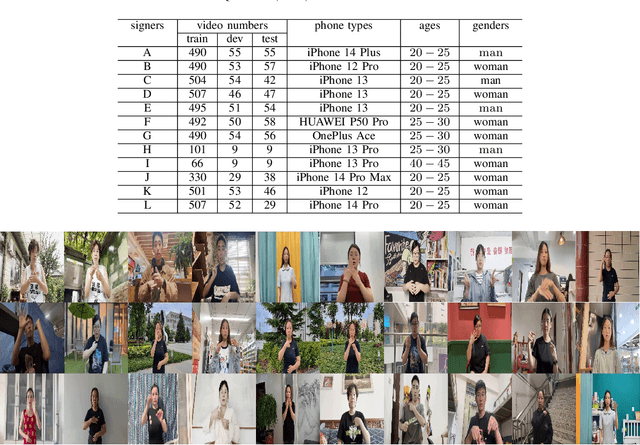
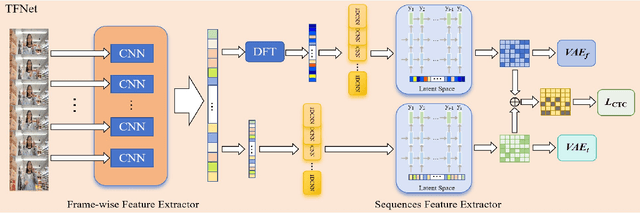
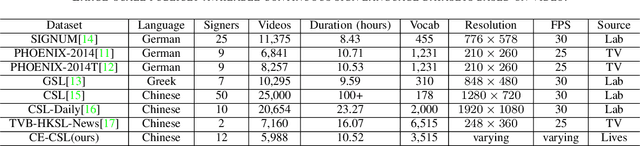
The current bottleneck in continuous sign language recognition (CSLR) research lies in the fact that most publicly available datasets are limited to laboratory environments or television program recordings, resulting in a single background environment with uniform lighting, which significantly deviates from the diversity and complexity found in real-life scenarios. To address this challenge, we have constructed a new, large-scale dataset for Chinese continuous sign language (CSL) based on complex environments, termed the complex environment - chinese sign language dataset (CE-CSL). This dataset encompasses 5,988 continuous CSL video clips collected from daily life scenes, featuring more than 70 different complex backgrounds to ensure representativeness and generalization capability. To tackle the impact of complex backgrounds on CSLR performance, we propose a time-frequency network (TFNet) model for continuous sign language recognition. This model extracts frame-level features and then utilizes both temporal and spectral information to separately derive sequence features before fusion, aiming to achieve efficient and accurate CSLR. Experimental results demonstrate that our approach achieves significant performance improvements on the CE-CSL, validating its effectiveness under complex background conditions. Additionally, our proposed method has also yielded highly competitive results when applied to three publicly available CSL datasets.
Continuous Sign Language Recognition Based on Motor attention mechanism and frame-level Self-distillation
Feb 29, 2024



Changes in facial expression, head movement, body movement and gesture movement are remarkable cues in sign language recognition, and most of the current continuous sign language recognition(CSLR) research methods mainly focus on static images in video sequences at the frame-level feature extraction stage, while ignoring the dynamic changes in the images. In this paper, we propose a novel motor attention mechanism to capture the distorted changes in local motion regions during sign language expression, and obtain a dynamic representation of image changes. And for the first time, we apply the self-distillation method to frame-level feature extraction for continuous sign language, which improves the feature expression without increasing the computational resources by self-distilling the features of adjacent stages and using the higher-order features as teachers to guide the lower-order features. The combination of the two constitutes our proposed holistic model of CSLR Based on motor attention mechanism and frame-level Self-Distillation (MAM-FSD), which improves the inference ability and robustness of the model. We conduct experiments on three publicly available datasets, and the experimental results show that our proposed method can effectively extract the sign language motion information in videos, improve the accuracy of CSLR and reach the state-of-the-art level.
Continuous sign language recognition based on cross-resolution knowledge distillation
Mar 13, 2023



The goal of continuous sign language recognition(CSLR) research is to apply CSLR models as a communication tool in real life, and the real-time requirement of the models is important. In this paper, we address the model real-time problem through cross-resolution knowledge distillation. In our study, we found that keeping the frame-level feature scales consistent between the output of the student network and the teacher network is better than recovering the frame-level feature sizes for feature distillation. Based on this finding, we propose a new frame-level feature extractor that keeps the output frame-level features at the same scale as the output of by the teacher network. We further combined with the TSCM+2D hybrid convolution proposed in our previous study to form a new lightweight end-to-end CSLR network-Low resolution input net(LRINet). It is then used to combine cross-resolution knowledge distillation and traditional knowledge distillation methods to form a CSLR model based on cross-resolution knowledge distillation (CRKD). The CRKD uses high-resolution frames as input to the teacher network for training, locks the weights after training, and then uses low-resolution frames as input to the student network LRINet to perform knowledge distillation on frame-level features and classification features respectively. Experiments on two large-scale continuous sign language datasets have proved the effectiveness of CRKD. Compared with the model with high-resolution data as input, the calculation amount, parameter amount and inference time of the model have been significantly reduced under the same experimental conditions, while ensuring the accuracy of the model, and has achieved very competitive results in comparison with other advanced methods.
Temporal superimposed crossover module for effective continuous sign language
Nov 07, 2022The ultimate goal of continuous sign language recognition(CSLR) is to facilitate the communication between special people and normal people, which requires a certain degree of real-time and deploy-ability of the model. However, in the previous research on CSLR, little attention has been paid to the real-time and deploy-ability. In order to improve the real-time and deploy-ability of the model, this paper proposes a zero parameter, zero computation temporal superposition crossover module(TSCM), and combines it with 2D convolution to form a "TSCM+2D convolution" hybrid convolution, which enables 2D convolution to have strong spatial-temporal modelling capability with zero parameter increase and lower deployment cost compared with other spatial-temporal convolutions. The overall CSLR model based on TSCM is built on the improved ResBlockT network in this paper. The hybrid convolution of "TSCM+2D convolution" is applied to the ResBlock of the ResNet network to form the new ResBlockT, and random gradient stop and multi-level CTC loss are introduced to train the model, which reduces the final recognition WER while reducing the training memory usage, and extends the ResNet network from image classification task to video recognition task. In addition, this study is the first in CSLR to use only 2D convolution extraction of sign language video temporal-spatial features for end-to-end learning for recognition. Experiments on two large-scale continuous sign language datasets demonstrate the effectiveness of the proposed method and achieve highly competitive results.
Continuous Sign Language Recognition via Temporal Super-Resolution Network
Jul 03, 2022
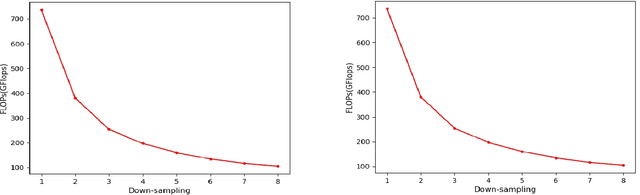
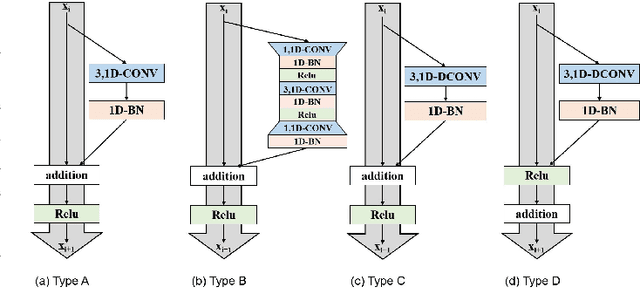
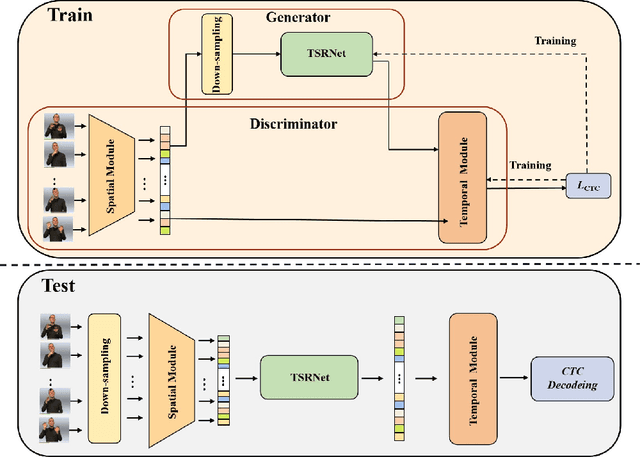
Aiming at the problem that the spatial-temporal hierarchical continuous sign language recognition model based on deep learning has a large amount of computation, which limits the real-time application of the model, this paper proposes a temporal super-resolution network(TSRNet). The data is reconstructed into a dense feature sequence to reduce the overall model computation while keeping the final recognition accuracy loss to a minimum. The continuous sign language recognition model(CSLR) via TSRNet mainly consists of three parts: frame-level feature extraction, time series feature extraction and TSRNet, where TSRNet is located between frame-level feature extraction and time-series feature extraction, which mainly includes two branches: detail descriptor and rough descriptor. The sparse frame-level features are fused through the features obtained by the two designed branches as the reconstructed dense frame-level feature sequence, and the connectionist temporal classification(CTC) loss is used for training and optimization after the time-series feature extraction part. To better recover semantic-level information, the overall model is trained with the self-generating adversarial training method proposed in this paper to reduce the model error rate. The training method regards the TSRNet as the generator, and the frame-level processing part and the temporal processing part as the discriminator. In addition, in order to unify the evaluation criteria of model accuracy loss under different benchmarks, this paper proposes word error rate deviation(WERD), which takes the error rate between the estimated word error rate (WER) and the reference WER obtained by the reconstructed frame-level feature sequence and the complete original frame-level feature sequence as the WERD. Experiments on two large-scale sign language datasets demonstrate the effectiveness of the proposed model.
Multi-scale temporal network for continuous sign language recognition
Apr 08, 2022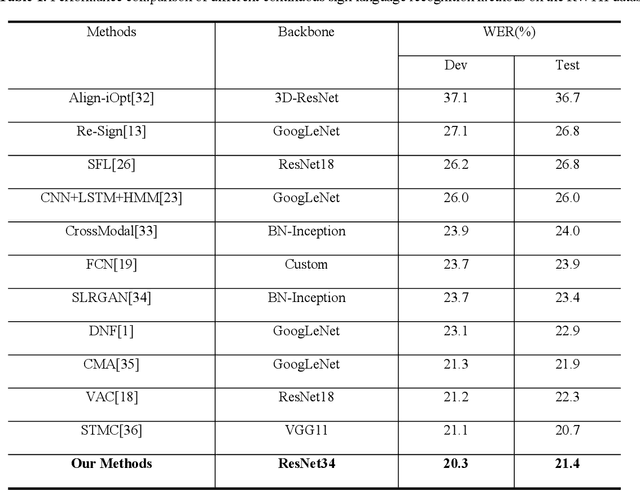
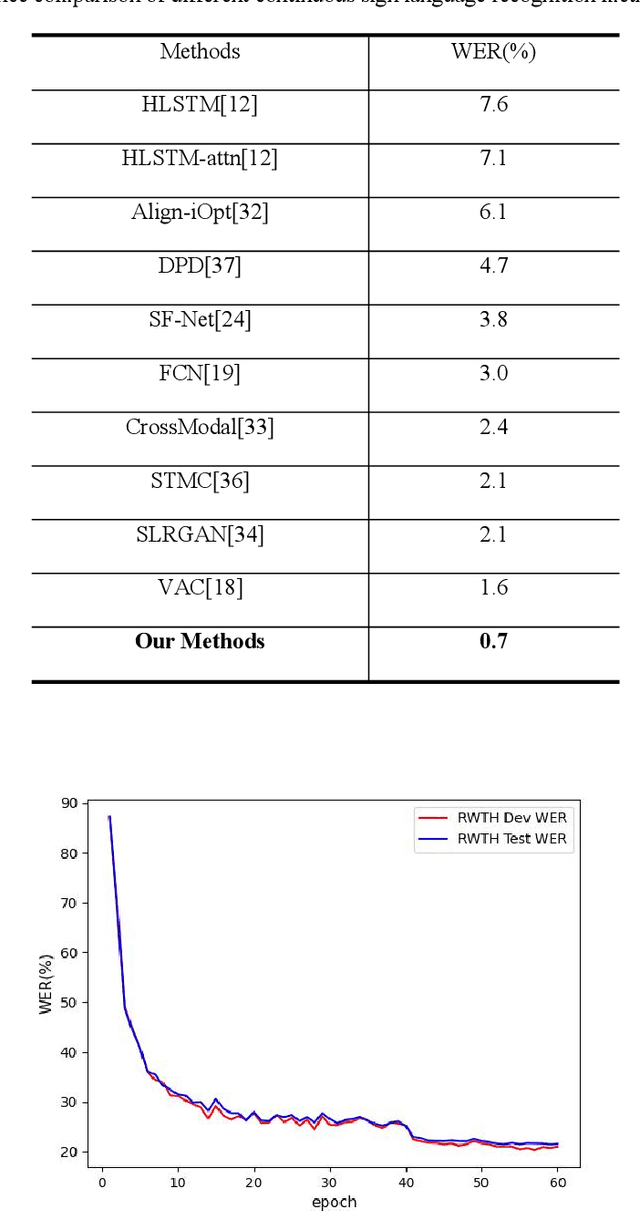
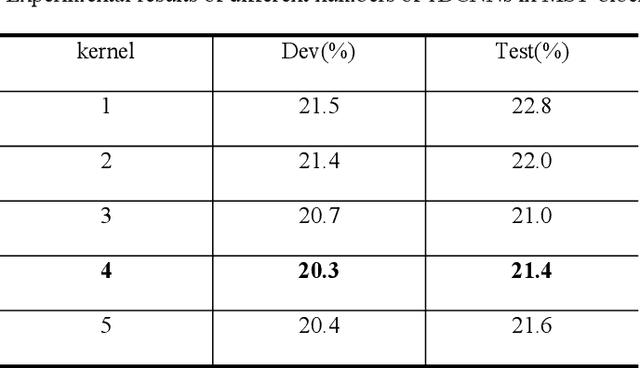

Continuous Sign Language Recognition (CSLR) is a challenging research task due to the lack of accurate annotation on the temporal sequence of sign language data. The recent popular usage is a hybrid model based on "CNN + RNN" for CSLR. However, when extracting temporal features in these works, most of the methods using a fixed temporal receptive field and cannot extract the temporal features well for each sign language word. In order to obtain more accurate temporal features, this paper proposes a multi-scale temporal network (MSTNet). The network mainly consists of three parts. The Resnet and two fully connected (FC) layers constitute the frame-wise feature extraction part. The time-wise feature extraction part performs temporal feature learning by first extracting temporal receptive field features of different scales using the proposed multi-scale temporal block (MST-block) to improve the temporal modeling capability, and then further encoding the temporal features of different scales by the transformers module to obtain more accurate temporal features. Finally, the proposed multi-level Connectionist Temporal Classification (CTC) loss part is used for training to obtain recognition results. The multi-level CTC loss enables better learning and updating of the shallow network parameters in CNN, and the method has no parameter increase and can be flexibly embedded in other models. Experimental results on two publicly available datasets demonstrate that our method can effectively extract sign language features in an end-to-end manner without any prior knowledge, improving the accuracy of CSLR and reaching the state-of-the-art.