 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Need to Train Your RDB Foundation Model
Feb 14, 2026Relational databases (RDBs) contain vast amounts of heterogeneous tabular information that can be exploited for predictive modeling purposes. But since the space of potential targets is vast across enterprise settings, how can we \textit{avoid retraining} a new model each time we wish to predict a new quantity of interest? Foundation models based on in-context learning (ICL) offer a convenient option, but so far are largely restricted to single-table operability. In generalizing to multiple interrelated tables, it is essential to compress variably-sized RDB neighborhoods into fixed-length ICL samples for consumption by the decoder. However, the details here are critical: unlike existing supervised learning RDB pipelines, we provide theoretical and empirical evidence that ICL-specific compression should be constrained \emph{within} high-dimensional RDB columns where all entities share units and roles, not \textit{across} columns where the relevance of heterogeneous data types cannot possibly be determined without label information. Conditioned on this restriction, we then demonstrate that encoder expressiveness is actually not compromised by excluding trainable parameters. Hence we arrive at a principled family of RDB encoders that can be seamlessly paired with already-existing single-table ICL foundation models, whereby no training or fine-tuning is required. From a practical standpoint, we develop scalable SQL primitives to implement the encoder stage, resulting in an easy-to-use open-source RDB foundation model\footnote{\label{foot: RDBLearn_learn} https://github.com/HKUSHXLab/rdblearn} capable of robust performance on unseen datasets out of the box.
Synthesize, Retrieve, and Propagate: A Unified Predictive Modeling Framework for Relational Databases
Aug 10, 2025Relational databases (RDBs) have become the industry standard for storing massive and heterogeneous data. However, despite the widespread use of RDBs across various fields, the inherent structure of relational databases hinders their ability to benefit from flourishing deep learning methods. Previous research has primarily focused on exploiting the unary dependency among multiple tables in a relational database using the primary key - foreign key relationships, either joining multiple tables into a single table or constructing a graph among them, which leaves the implicit composite relations among different tables and a substantial potential of improvement for predictive modeling unexplored. In this paper, we propose SRP, a unified predictive modeling framework that synthesizes features using the unary dependency, retrieves related information to capture the composite dependency, and propagates messages across a constructed graph to learn adjacent patterns for prediction on relation databases. By introducing a new retrieval mechanism into RDB, SRP is designed to fully capture both the unary and the composite dependencies within a relational database, thereby enhancing the receptive field of tabular data prediction. In addition, we conduct a comprehensive analysis on the components of SRP, offering a nuanced understanding of model behaviors and practical guidelines for future applications. Extensive experiments on five real-world datasets demonstrate the effectiveness of SRP and its potential applicability in industrial scenarios. The code is released at https://github.com/NingLi670/SRP.
Griffin: Towards a Graph-Centric Relational Database Foundation Model
May 08, 2025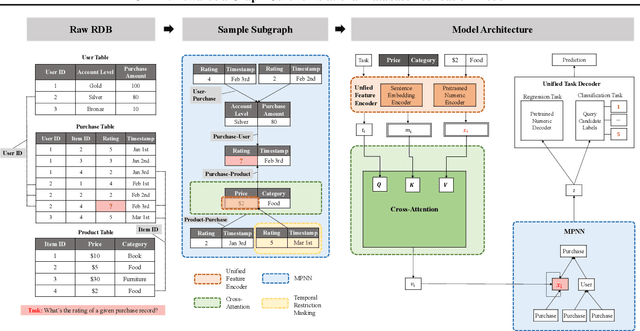
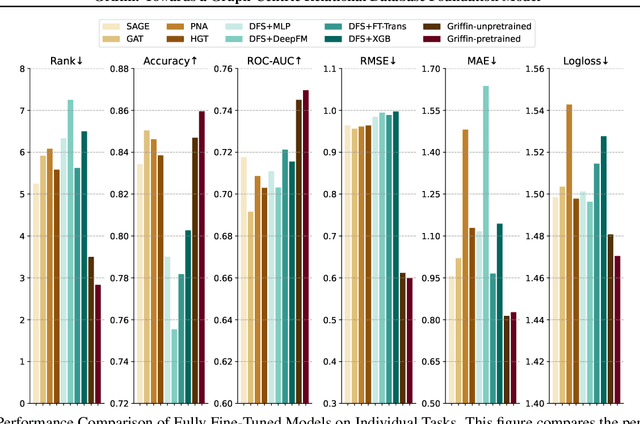

We introduce Griffin, the first foundation model attemptation designed specifically for Relational Databases (RDBs). Unlike previous smaller models focused on single RDB tasks, Griffin unifies the data encoder and task decoder to handle diverse tasks. Additionally, we enhance the architecture by incorporating a cross-attention module and a novel aggregator. Griffin utilizes pretraining on both single-table and RDB datasets, employing advanced encoders for categorical, numerical, and metadata features, along with innovative components such as cross-attention modules and enhanced message-passing neural networks (MPNNs) to capture the complexities of relational data. Evaluated on large-scale, heterogeneous, and temporal graphs extracted from RDBs across various domains (spanning over 150 million nodes), Griffin demonstrates superior or comparable performance to individually trained models, excels in low-data scenarios, and shows strong transferability with similarity and diversity in pretraining across new datasets and tasks, highlighting its potential as a universally applicable foundation model for RDBs. Code available at https://github.com/yanxwb/Griffin.
Prior-Fitted Networks Scale to Larger Datasets When Treated as Weak Learners
Mar 03, 2025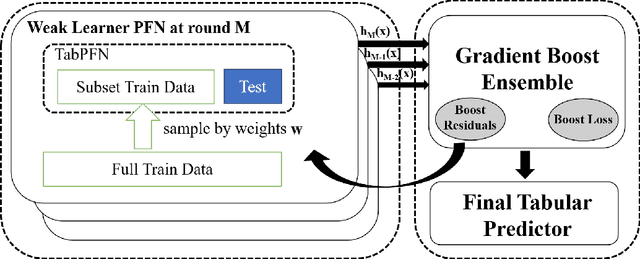

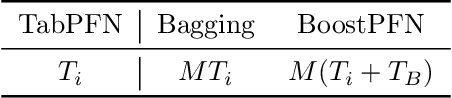
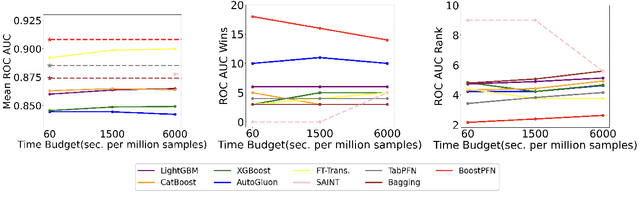
Prior-Fitted Networks (PFNs) have recently been proposed to efficiently perform tabular classification tasks. Although they achieve good performance on small datasets, they encounter limitations with larger datasets. These limitations include significant memory consumption and increased computational complexity, primarily due to the impracticality of incorporating all training samples as inputs within these networks. To address these challenges, we investigate the fitting assumption for PFNs and input samples. Building on this understanding, we propose \textit{BoostPFN} designed to enhance the performance of these networks, especially for large-scale datasets. We also theoretically validate the convergence of BoostPFN and our empirical results demonstrate that the BoostPFN method can outperform standard PFNs with the same size of training samples in large datasets and achieve a significant acceleration in training times compared to other established baselines in the field, including widely-used Gradient Boosting Decision Trees (GBDTs), deep learning methods and AutoML systems. High performance is maintained for up to 50x of the pre-training size of PFNs, substantially extending the limit of training samples. Through this work, we address the challenges of efficiently handling large datasets via PFN-based models, paving the way for faster and more effective tabular data classification training and prediction process. Code is available at Github.
ELF-Gym: Evaluating Large Language Models Generated Features for Tabular Prediction
Oct 13, 2024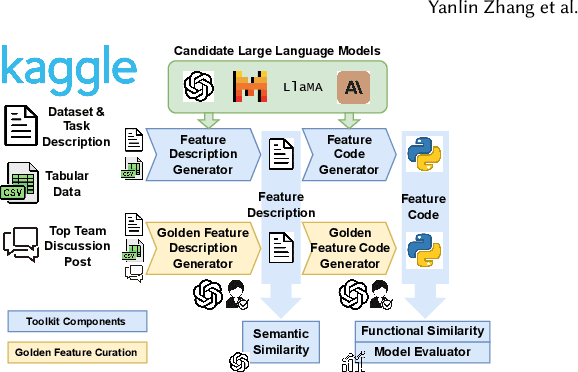
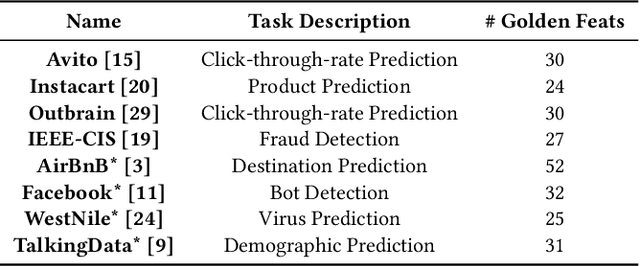
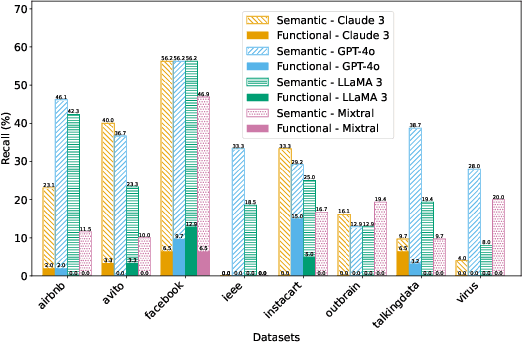
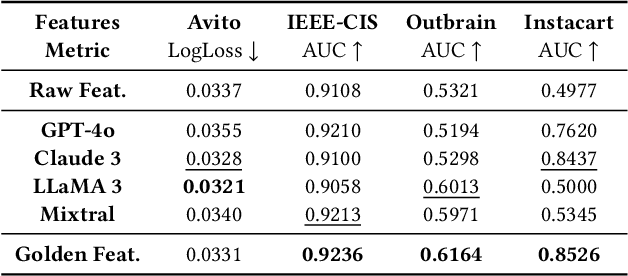
Crafting effective features is a crucial yet labor-intensive and domain-specific task within machine learning pipelines. Fortunately, recent advancements in Large Language Models (LLMs) have shown promise in automating various data science tasks, including feature engineering. But despite this potential, evaluations thus far are primarily based on the end performance of a complete ML pipeline, providing limited insight into precisely how LLMs behave relative to human experts in feature engineering. To address this gap, we propose ELF-Gym, a framework for Evaluating LLM-generated Features. We curated a new dataset from historical Kaggle competitions, including 251 "golden" features used by top-performing teams. ELF-Gym then quantitatively evaluates LLM-generated features by measuring their impact on downstream model performance as well as their alignment with expert-crafted features through semantic and functional similarity assessments. This approach provides a more comprehensive evaluation of disparities between LLMs and human experts, while offering valuable insights into specific areas where LLMs may have room for improvement. For example, using ELF-Gym we empirically demonstrate that, in the best-case scenario, LLMs can semantically capture approximately 56% of the golden features, but at the more demanding implementation level this overlap drops to 13%. Moreover, in other cases LLMs may fail completely, particularly on datasets that require complex features, indicating broad potential pathways for improvement.
A Chinese Continuous Sign Language Dataset Based on Complex Environments
Sep 18, 2024
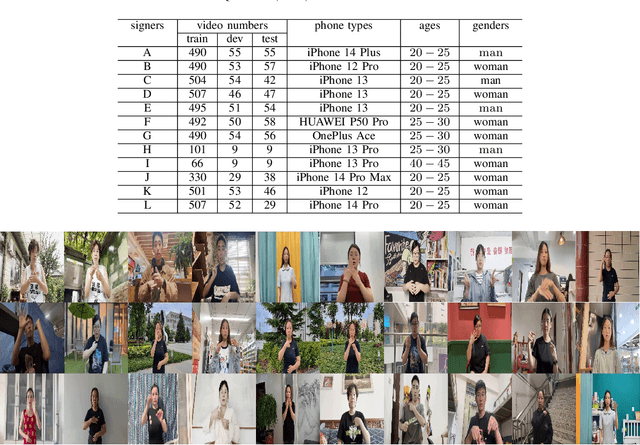
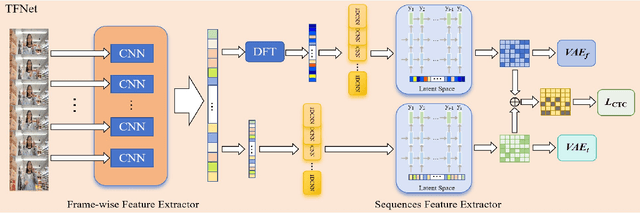
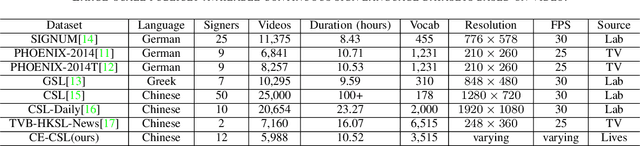
The current bottleneck in continuous sign language recognition (CSLR) research lies in the fact that most publicly available datasets are limited to laboratory environments or television program recordings, resulting in a single background environment with uniform lighting, which significantly deviates from the diversity and complexity found in real-life scenarios. To address this challenge, we have constructed a new, large-scale dataset for Chinese continuous sign language (CSL) based on complex environments, termed the complex environment - chinese sign language dataset (CE-CSL). This dataset encompasses 5,988 continuous CSL video clips collected from daily life scenes, featuring more than 70 different complex backgrounds to ensure representativeness and generalization capability. To tackle the impact of complex backgrounds on CSLR performance, we propose a time-frequency network (TFNet) model for continuous sign language recognition. This model extracts frame-level features and then utilizes both temporal and spectral information to separately derive sequence features before fusion, aiming to achieve efficient and accurate CSLR. Experimental results demonstrate that our approach achieves significant performance improvements on the CE-CSL, validating its effectiveness under complex background conditions. Additionally, our proposed method has also yielded highly competitive results when applied to three publicly available CSL datasets.
4DBInfer: A 4D Benchmarking Toolbox for Graph-Centric Predictive Modeling on Relational DBs
Apr 28, 2024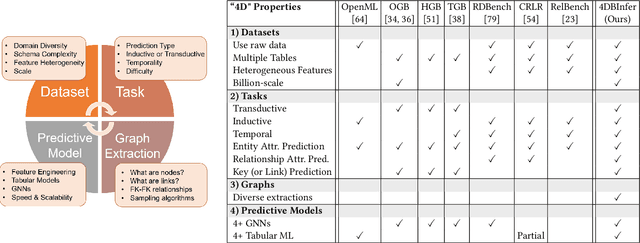
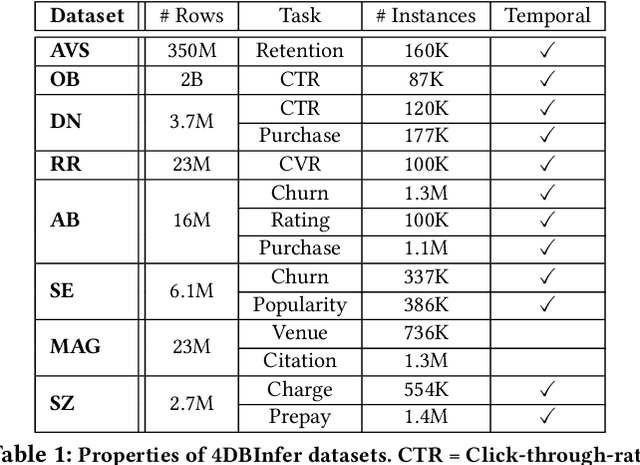
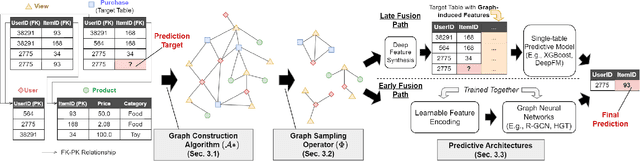
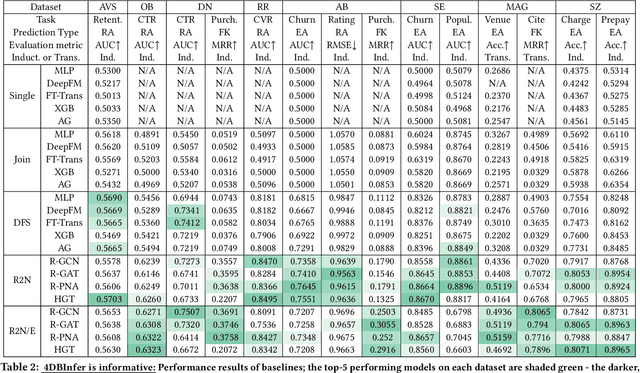
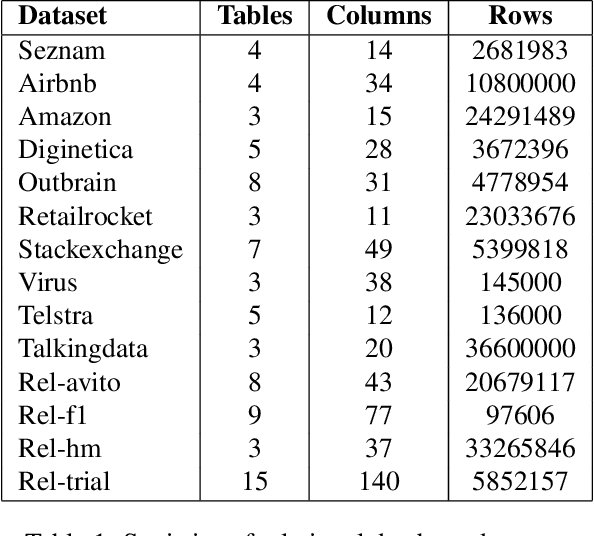
Although RDBs store vast amounts of rich, informative data spread across interconnected tables, the progress of predictive machine learning models as applied to such tasks arguably falls well behind advances in other domains such as computer vision or natural language processing. This deficit stems, at least in part, from the lack of established/public RDB benchmarks as needed for training and evaluation purposes. As a result, related model development thus far often defaults to tabular approaches trained on ubiquitous single-table benchmarks, or on the relational side, graph-based alternatives such as GNNs applied to a completely different set of graph datasets devoid of tabular characteristics. To more precisely target RDBs lying at the nexus of these two complementary regimes, we explore a broad class of baseline models predicated on: (i) converting multi-table datasets into graphs using various strategies equipped with efficient subsampling, while preserving tabular characteristics; and (ii) trainable models with well-matched inductive biases that output predictions based on these input subgraphs. Then, to address the dearth of suitable public benchmarks and reduce siloed comparisons, we assemble a diverse collection of (i) large-scale RDB datasets and (ii) coincident predictive tasks. From a delivery standpoint, we operationalize the above four dimensions (4D) of exploration within a unified, scalable open-source toolbox called 4DBInfer. We conclude by presenting evaluations using 4DBInfer, the results of which highlight the importance of considering each such dimension in the design of RDB predictive models, as well as the limitations of more naive approaches such as simply joining adjacent tables. Our source code is released at https://github.com/awslabs/multi-table-benchmark .
Continuous Sign Language Recognition Based on Motor attention mechanism and frame-level Self-distillation
Feb 29, 2024



Changes in facial expression, head movement, body movement and gesture movement are remarkable cues in sign language recognition, and most of the current continuous sign language recognition(CSLR) research methods mainly focus on static images in video sequences at the frame-level feature extraction stage, while ignoring the dynamic changes in the images. In this paper, we propose a novel motor attention mechanism to capture the distorted changes in local motion regions during sign language expression, and obtain a dynamic representation of image changes. And for the first time, we apply the self-distillation method to frame-level feature extraction for continuous sign language, which improves the feature expression without increasing the computational resources by self-distilling the features of adjacent stages and using the higher-order features as teachers to guide the lower-order features. The combination of the two constitutes our proposed holistic model of CSLR Based on motor attention mechanism and frame-level Self-Distillation (MAM-FSD), which improves the inference ability and robustness of the model. We conduct experiments on three publicly available datasets, and the experimental results show that our proposed method can effectively extract the sign language motion information in videos, improve the accuracy of CSLR and reach the state-of-the-art level.
GFS: Graph-based Feature Synthesis for Prediction over Relational Databases
Dec 04, 2023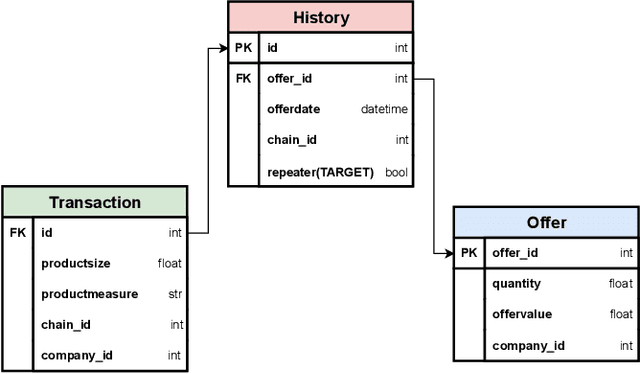
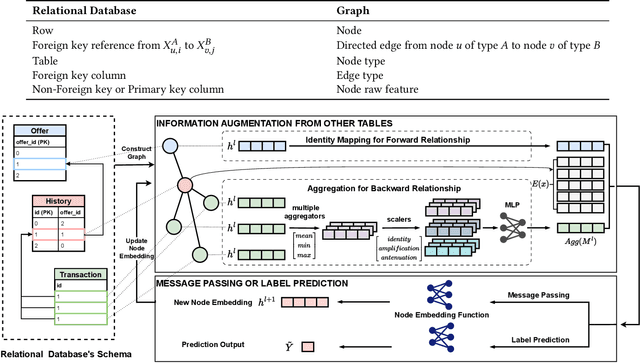
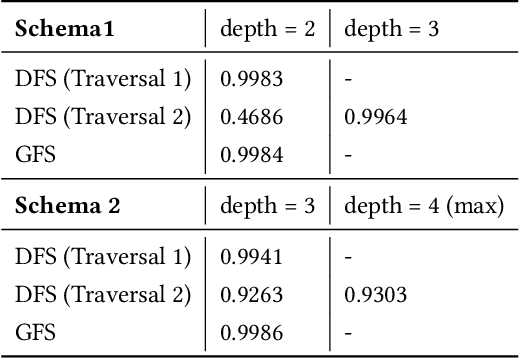
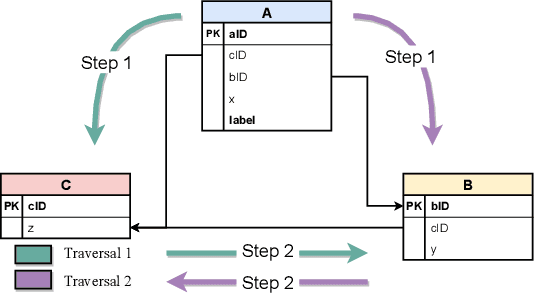
Relational databases are extensively utilized in a variety of modern information system applications, and they always carry valuable data patterns. There are a huge number of data mining or machine learning tasks conducted on relational databases. However, it is worth noting that there are limited machine learning models specifically designed for relational databases, as most models are primarily tailored for single table settings. Consequently, the prevalent approach for training machine learning models on data stored in relational databases involves performing feature engineering to merge the data from multiple tables into a single table and subsequently applying single table models. This approach not only requires significant effort in feature engineering but also destroys the inherent relational structure present in the data. To address these challenges, we propose a novel framework called Graph-based Feature Synthesis (GFS). GFS formulates the relational database as a heterogeneous graph, thereby preserving the relational structure within the data. By leveraging the inductive bias from single table models, GFS effectively captures the intricate relationships inherent in each table. Additionally, the whole framework eliminates the need for manual feature engineering. In the extensive experiment over four real-world multi-table relational databases, GFS outperforms previous methods designed for relational databases, demonstrating its superior performance.
GNNFlow: A Distributed Framework for Continuous Temporal GNN Learning on Dynamic Graphs
Nov 30, 2023



Graph Neural Networks (GNNs) play a crucial role in various fields. However, most existing deep graph learning frameworks assume pre-stored static graphs and do not support training on graph streams. In contrast, many real-world graphs are dynamic and contain time domain information. We introduce GNNFlow, a distributed framework that enables efficient continuous temporal graph representation learning on dynamic graphs on multi-GPU machines. GNNFlow introduces an adaptive time-indexed block-based data structure that effectively balances memory usage with graph update and sampling operation efficiency. It features a hybrid GPU-CPU graph data placement for rapid GPU-based temporal neighborhood sampling and kernel optimizations for enhanced sampling processes. A dynamic GPU cache for node and edge features is developed to maximize cache hit rates through reuse and restoration strategies. GNNFlow supports distributed training across multiple machines with static scheduling to ensure load balance. We implement GNNFlow based on DGL and PyTorch. Our experimental results show that GNNFlow provides up to 21.1x faster continuous learning than existing systems.