 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGFS: Graph-based Feature Synthesis for Prediction over Relational Databases
Paper and Code
Dec 04, 2023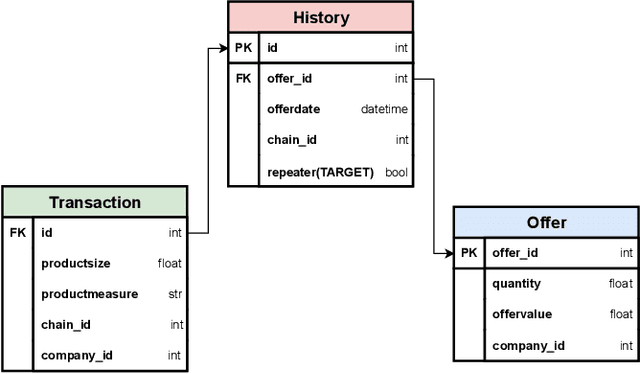
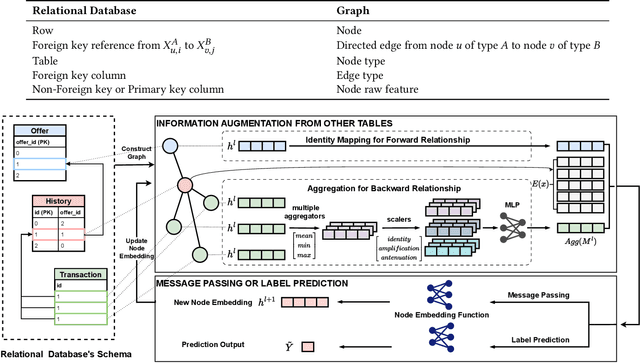
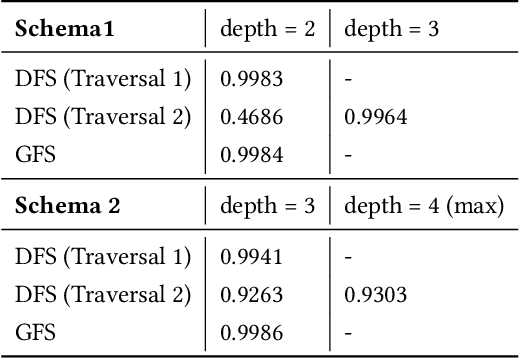
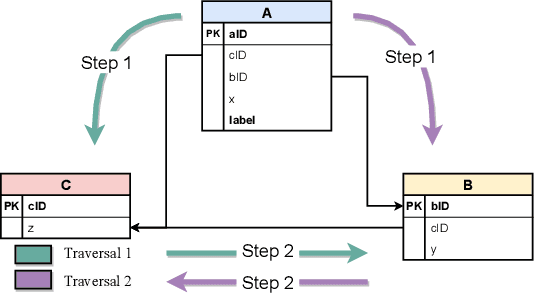
Relational databases are extensively utilized in a variety of modern information system applications, and they always carry valuable data patterns. There are a huge number of data mining or machine learning tasks conducted on relational databases. However, it is worth noting that there are limited machine learning models specifically designed for relational databases, as most models are primarily tailored for single table settings. Consequently, the prevalent approach for training machine learning models on data stored in relational databases involves performing feature engineering to merge the data from multiple tables into a single table and subsequently applying single table models. This approach not only requires significant effort in feature engineering but also destroys the inherent relational structure present in the data. To address these challenges, we propose a novel framework called Graph-based Feature Synthesis (GFS). GFS formulates the relational database as a heterogeneous graph, thereby preserving the relational structure within the data. By leveraging the inductive bias from single table models, GFS effectively captures the intricate relationships inherent in each table. Additionally, the whole framework eliminates the need for manual feature engineering. In the extensive experiment over four real-world multi-table relational databases, GFS outperforms previous methods designed for relational databases, demonstrating its superior performance.