 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Need to Train Your RDB Foundation Model
Feb 14, 2026Relational databases (RDBs) contain vast amounts of heterogeneous tabular information that can be exploited for predictive modeling purposes. But since the space of potential targets is vast across enterprise settings, how can we \textit{avoid retraining} a new model each time we wish to predict a new quantity of interest? Foundation models based on in-context learning (ICL) offer a convenient option, but so far are largely restricted to single-table operability. In generalizing to multiple interrelated tables, it is essential to compress variably-sized RDB neighborhoods into fixed-length ICL samples for consumption by the decoder. However, the details here are critical: unlike existing supervised learning RDB pipelines, we provide theoretical and empirical evidence that ICL-specific compression should be constrained \emph{within} high-dimensional RDB columns where all entities share units and roles, not \textit{across} columns where the relevance of heterogeneous data types cannot possibly be determined without label information. Conditioned on this restriction, we then demonstrate that encoder expressiveness is actually not compromised by excluding trainable parameters. Hence we arrive at a principled family of RDB encoders that can be seamlessly paired with already-existing single-table ICL foundation models, whereby no training or fine-tuning is required. From a practical standpoint, we develop scalable SQL primitives to implement the encoder stage, resulting in an easy-to-use open-source RDB foundation model\footnote{\label{foot: RDBLearn_learn} https://github.com/HKUSHXLab/rdblearn} capable of robust performance on unseen datasets out of the box.
Synthesize, Retrieve, and Propagate: A Unified Predictive Modeling Framework for Relational Databases
Aug 10, 2025Relational databases (RDBs) have become the industry standard for storing massive and heterogeneous data. However, despite the widespread use of RDBs across various fields, the inherent structure of relational databases hinders their ability to benefit from flourishing deep learning methods. Previous research has primarily focused on exploiting the unary dependency among multiple tables in a relational database using the primary key - foreign key relationships, either joining multiple tables into a single table or constructing a graph among them, which leaves the implicit composite relations among different tables and a substantial potential of improvement for predictive modeling unexplored. In this paper, we propose SRP, a unified predictive modeling framework that synthesizes features using the unary dependency, retrieves related information to capture the composite dependency, and propagates messages across a constructed graph to learn adjacent patterns for prediction on relation databases. By introducing a new retrieval mechanism into RDB, SRP is designed to fully capture both the unary and the composite dependencies within a relational database, thereby enhancing the receptive field of tabular data prediction. In addition, we conduct a comprehensive analysis on the components of SRP, offering a nuanced understanding of model behaviors and practical guidelines for future applications. Extensive experiments on five real-world datasets demonstrate the effectiveness of SRP and its potential applicability in industrial scenarios. The code is released at https://github.com/NingLi670/SRP.
Explicit Preference Optimization: No Need for an Implicit Reward Model
Jun 09, 2025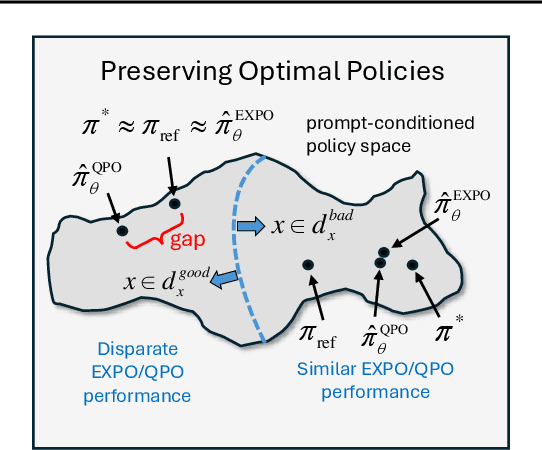
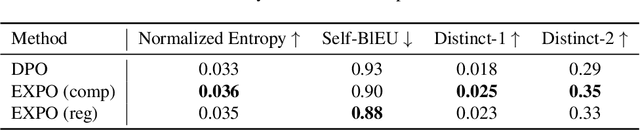
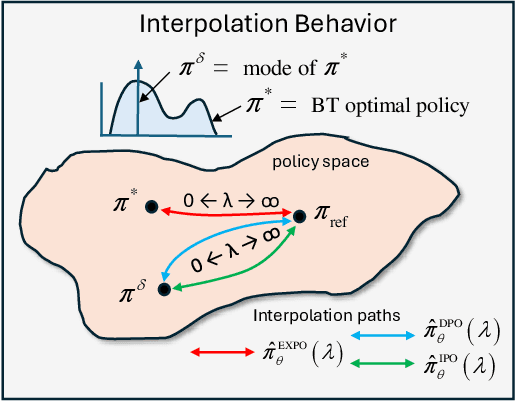
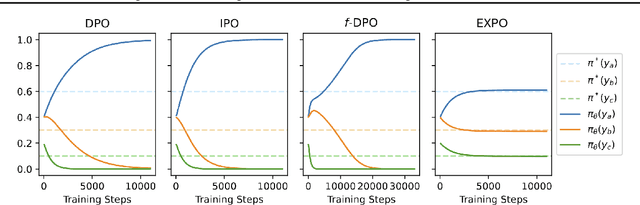
The generated responses of large language models (LLMs) are often fine-tuned to human preferences through a process called reinforcement learning from human feedback (RLHF). As RLHF relies on a challenging training sequence, whereby a separate reward model is independently learned and then later applied to LLM policy updates, ongoing research effort has targeted more straightforward alternatives. In this regard, direct preference optimization (DPO) and its many offshoots circumvent the need for a separate reward training step. Instead, through the judicious use of a reparameterization trick that induces an \textit{implicit} reward, DPO and related methods consolidate learning to the minimization of a single loss function. And yet despite demonstrable success in some real-world settings, we prove that DPO-based objectives are nonetheless subject to sub-optimal regularization and counter-intuitive interpolation behaviors, underappreciated artifacts of the reparameterizations upon which they are based. To this end, we introduce an \textit{explicit} preference optimization framework termed EXPO that requires no analogous reparameterization to achieve an implicit reward. Quite differently, we merely posit intuitively-appealing regularization factors from scratch that transparently avoid the potential pitfalls of key DPO variants, provably satisfying regularization desiderata that prior methods do not. Empirical results serve to corroborate our analyses and showcase the efficacy of EXPO.
Sparse Autoencoders, Again?
Jun 06, 2025



Is there really much more to say about sparse autoencoders (SAEs)? Autoencoders in general, and SAEs in particular, represent deep architectures that are capable of modeling low-dimensional latent structure in data. Such structure could reflect, among other things, correlation patterns in large language model activations, or complex natural image manifolds. And yet despite the wide-ranging applicability, there have been relatively few changes to SAEs beyond the original recipe from decades ago, namely, standard deep encoder/decoder layers trained with a classical/deterministic sparse regularizer applied within the latent space. One possible exception is the variational autoencoder (VAE), which adopts a stochastic encoder module capable of producing sparse representations when applied to manifold data. In this work we formalize underappreciated weaknesses with both canonical SAEs, as well as analogous VAEs applied to similar tasks, and propose a hybrid alternative model that circumvents these prior limitations. In terms of theoretical support, we prove that global minima of our proposed model recover certain forms of structured data spread across a union of manifolds. Meanwhile, empirical evaluations on synthetic and real-world datasets substantiate the efficacy of our approach in accurately estimating underlying manifold dimensions and producing sparser latent representations without compromising reconstruction error. In general, we are able to exceed the performance of equivalent-capacity SAEs and VAEs, as well as recent diffusion models where applicable, within domains such as images and language model activation patterns.
Griffin: Towards a Graph-Centric Relational Database Foundation Model
May 08, 2025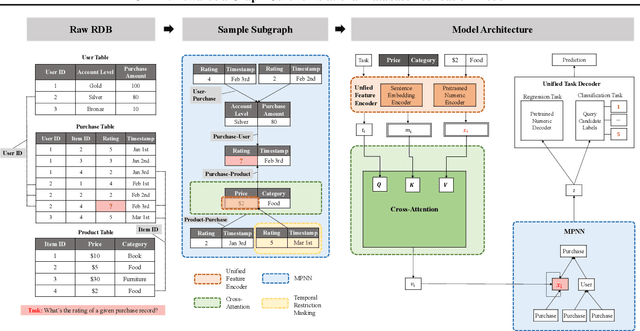
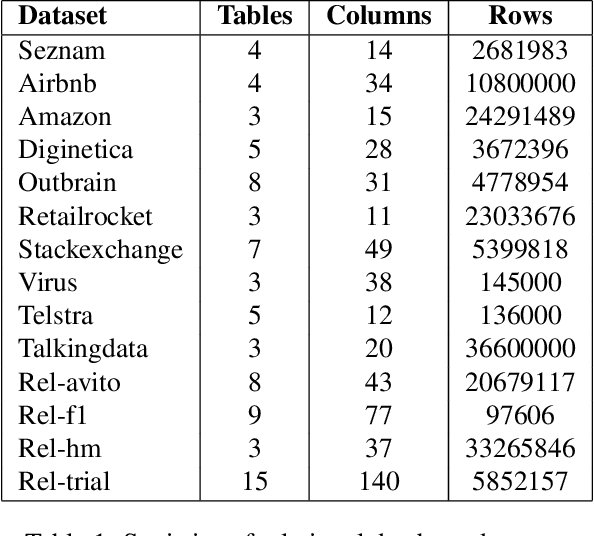
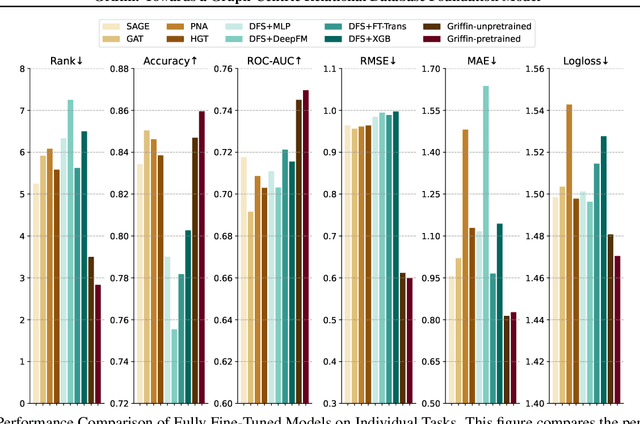

We introduce Griffin, the first foundation model attemptation designed specifically for Relational Databases (RDBs). Unlike previous smaller models focused on single RDB tasks, Griffin unifies the data encoder and task decoder to handle diverse tasks. Additionally, we enhance the architecture by incorporating a cross-attention module and a novel aggregator. Griffin utilizes pretraining on both single-table and RDB datasets, employing advanced encoders for categorical, numerical, and metadata features, along with innovative components such as cross-attention modules and enhanced message-passing neural networks (MPNNs) to capture the complexities of relational data. Evaluated on large-scale, heterogeneous, and temporal graphs extracted from RDBs across various domains (spanning over 150 million nodes), Griffin demonstrates superior or comparable performance to individually trained models, excels in low-data scenarios, and shows strong transferability with similarity and diversity in pretraining across new datasets and tasks, highlighting its potential as a universally applicable foundation model for RDBs. Code available at https://github.com/yanxwb/Griffin.
Prior-Fitted Networks Scale to Larger Datasets When Treated as Weak Learners
Mar 03, 2025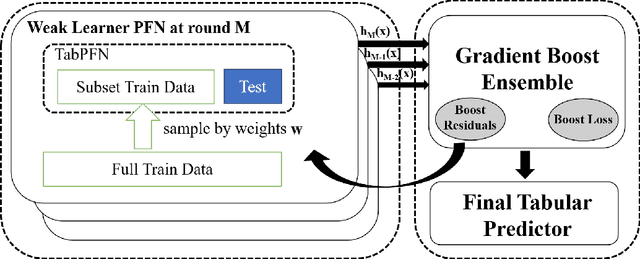

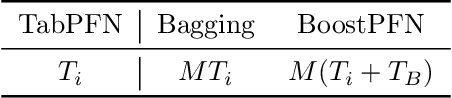
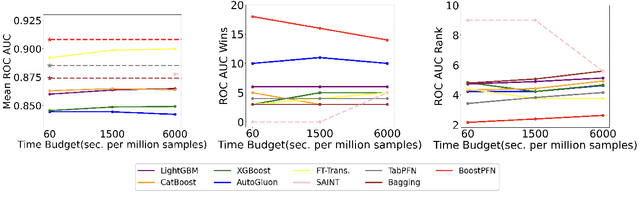
Prior-Fitted Networks (PFNs) have recently been proposed to efficiently perform tabular classification tasks. Although they achieve good performance on small datasets, they encounter limitations with larger datasets. These limitations include significant memory consumption and increased computational complexity, primarily due to the impracticality of incorporating all training samples as inputs within these networks. To address these challenges, we investigate the fitting assumption for PFNs and input samples. Building on this understanding, we propose \textit{BoostPFN} designed to enhance the performance of these networks, especially for large-scale datasets. We also theoretically validate the convergence of BoostPFN and our empirical results demonstrate that the BoostPFN method can outperform standard PFNs with the same size of training samples in large datasets and achieve a significant acceleration in training times compared to other established baselines in the field, including widely-used Gradient Boosting Decision Trees (GBDTs), deep learning methods and AutoML systems. High performance is maintained for up to 50x of the pre-training size of PFNs, substantially extending the limit of training samples. Through this work, we address the challenges of efficiently handling large datasets via PFN-based models, paving the way for faster and more effective tabular data classification training and prediction process. Code is available at Github.
ELF-Gym: Evaluating Large Language Models Generated Features for Tabular Prediction
Oct 13, 2024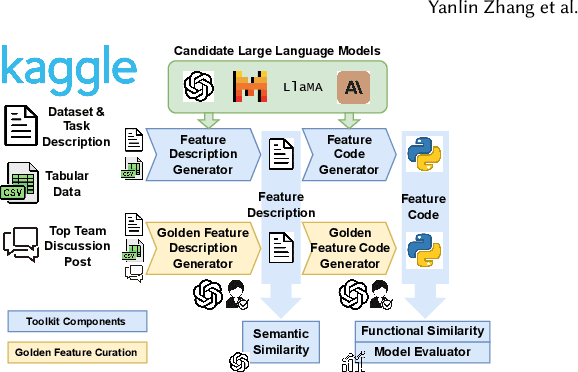
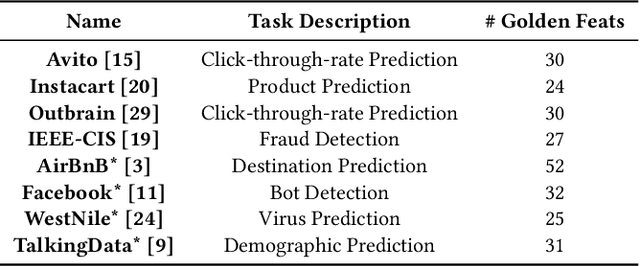
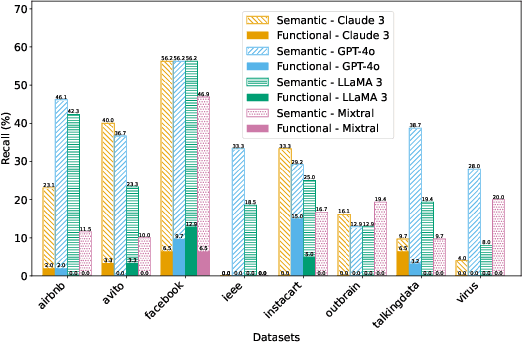
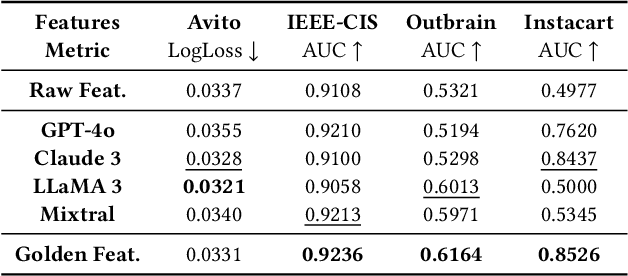
Crafting effective features is a crucial yet labor-intensive and domain-specific task within machine learning pipelines. Fortunately, recent advancements in Large Language Models (LLMs) have shown promise in automating various data science tasks, including feature engineering. But despite this potential, evaluations thus far are primarily based on the end performance of a complete ML pipeline, providing limited insight into precisely how LLMs behave relative to human experts in feature engineering. To address this gap, we propose ELF-Gym, a framework for Evaluating LLM-generated Features. We curated a new dataset from historical Kaggle competitions, including 251 "golden" features used by top-performing teams. ELF-Gym then quantitatively evaluates LLM-generated features by measuring their impact on downstream model performance as well as their alignment with expert-crafted features through semantic and functional similarity assessments. This approach provides a more comprehensive evaluation of disparities between LLMs and human experts, while offering valuable insights into specific areas where LLMs may have room for improvement. For example, using ELF-Gym we empirically demonstrate that, in the best-case scenario, LLMs can semantically capture approximately 56% of the golden features, but at the more demanding implementation level this overlap drops to 13%. Moreover, in other cases LLMs may fail completely, particularly on datasets that require complex features, indicating broad potential pathways for improvement.
Neural Message Passing Induced by Energy-Constrained Diffusion
Sep 13, 2024



Learning representations for structured data with certain geometries (observed or unobserved) is a fundamental challenge, wherein message passing neural networks (MPNNs) have become a de facto class of model solutions. In this paper, we propose an energy-constrained diffusion model as a principled interpretable framework for understanding the mechanism of MPNNs and navigating novel architectural designs. The model, inspired by physical systems, combines the inductive bias of diffusion on manifolds with layer-wise constraints of energy minimization. As shown by our analysis, the diffusion operators have a one-to-one correspondence with the energy functions implicitly descended by the diffusion process, and the finite-difference iteration for solving the energy-constrained diffusion system induces the propagation layers of various types of MPNNs operated on observed or latent structures. On top of these findings, we devise a new class of neural message passing models, dubbed as diffusion-inspired Transformers, whose global attention layers are induced by the principled energy-constrained diffusion. Across diverse datasets ranging from real-world networks to images and physical particles, we show that the new model can yield promising performance for cases where the data structures are observed (as a graph), partially observed or completely unobserved.
SGFormer: Single-Layer Graph Transformers with Approximation-Free Linear Complexity
Sep 13, 2024



Learning representations on large graphs is a long-standing challenge due to the inter-dependence nature. Transformers recently have shown promising performance on small graphs thanks to its global attention for capturing all-pair interactions beyond observed structures. Existing approaches tend to inherit the spirit of Transformers in language and vision tasks, and embrace complicated architectures by stacking deep attention-based propagation layers. In this paper, we attempt to evaluate the necessity of adopting multi-layer attentions in Transformers on graphs, which considerably restricts the efficiency. Specifically, we analyze a generic hybrid propagation layer, comprised of all-pair attention and graph-based propagation, and show that multi-layer propagation can be reduced to one-layer propagation, with the same capability for representation learning. It suggests a new technical path for building powerful and efficient Transformers on graphs, particularly through simplifying model architectures without sacrificing expressiveness. As exemplified by this work, we propose a Simplified Single-layer Graph Transformers (SGFormer), whose main component is a single-layer global attention that scales linearly w.r.t. graph sizes and requires none of any approximation for accommodating all-pair interactions. Empirically, SGFormer successfully scales to the web-scale graph ogbn-papers100M, yielding orders-of-magnitude inference acceleration over peer Transformers on medium-sized graphs, and demonstrates competitiveness with limited labeled data.
New Desiderata for Direct Preference Optimization
Jul 12, 2024



Large language models in the past have typically relied on some form of reinforcement learning with human feedback (RLHF) to better align model responses with human preferences. However, because of oft-observed instabilities when implementing these RLHF pipelines, various reparameterization techniques have recently been introduced to sidestep the need for separately learning an RL reward model. Instead, directly fine-tuning for human preferences is achieved via the minimization of a single closed-form training objective, a process originally referred to as direct preference optimization (DPO) and followed by several notable descendants. Although effective in certain real-world settings, we introduce new evaluation criteria that serve to highlight unresolved shortcomings in the ability of existing DPO methods to interpolate between a pre-trained reference model and empirical measures of human preferences, as well as unavoidable trade-offs in how low- and high-quality responses are regularized and constraints are handled. Our insights then motivate an alternative DPO-like loss that provably mitigates these limitations. Empirical results serve to corroborate notable aspects of our analyses.