 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE: A Self-Evolving Agentic Graph-Memory Engine for Structure-Aware Associative Memory
May 12, 2026Long-term memory is becoming a central bottleneck for language agents. Exsting RAG and GraphRAG systems largely treat memory graphs as static retrieval middleware, which limits their ability to recover complete evidence chains from partial cues, exploit reusable graph-structrual roles, and improve the memory itself through downstream feedback. We introduce SAGE, a Self-evolving Agentic Graph-memory Engine that models graph memory as a dynamic long-term memory substrate. SAGE couples two roles: a memory writer that incrementally constucts structured graph memory from interaction histories, and a Graph Foundation Model-based memory reader to perform retrieval and provide feedback to the memory writer. We provide rigorooous theoretical annalyses supporting the framework. Across multi-hop QA, open-domain retireval, domain-specific review QA, and long-term agent-memory benchmarks, SAGE improves evidence recovery, answer grounding, and retrieval efficiency: after two self-evolution rounds, it achieves the best average rank on multi-hop QA; in zero-shot open-domain transfer, it reaches 82.5/91.6 Recall@2/5 on NQ. Further results on LongMemEval and HaluMem show that traning and reader-writer feedback improve multiple long-term memory and hallucination-diagnostic metrics, suggesting that self-evolving, structure-aware graph memory is a promising foundation for robust long-horizon language agents.
Position: How can Graphs Help Large Language Models?
May 04, 2026With the rapid advancement of large language models (LLMs), classic graph learning tasks have greatly benefited from LLMs, including improved encoding of textual features, more efficient construction of graphs from text, and enhanced reasoning over knowledge graphs. In this paper, we ask a complementary question: How can graphs help LLMs? We address this question from three perspectives: 1) graphs provide an up-to-date knowledge source that helps reduce LLM hallucinations, 2) graph-based prompting techniques-such as Chain-of-Thought (CoT), Tree-of-Thought (ToT), and Graph-of-Thought (GoT)-enhance LLM reasoning capabilities, and 3) integrating graphs into LLMs improves their understanding of structured data, expanding their applicability to domains such as e-commerce, code, and relational databases (RDBs). We further outlook some future directions including designing sparse LLM architectures based on graphs and brain-inspired memory systems.
GREPO: A Benchmark for Graph Neural Networks on Repository-Level Bug Localization
Feb 14, 2026Repository-level bug localization-the task of identifying where code must be modified to fix a bug-is a critical software engineering challenge. Standard Large Language Modles (LLMs) are often unsuitable for this task due to context window limitations that prevent them from processing entire code repositories. As a result, various retrieval methods are commonly used, including keyword matching, text similarity, and simple graph-based heuristics such as Breadth-First Search. Graph Neural Networks (GNNs) offer a promising alternative due to their ability to model complex, repository-wide dependencies; however, their application has been hindered by the lack of a dedicated benchmark. To address this gap, we introduce GREPO, the first GNN benchmark for repository-scale bug localization tasks. GREPO comprises 86 Python repositories and 47294 bug-fixing tasks, providing graph-based data structures ready for direct GNN processing. Our evaluation of various GNN architectures shows outstanding performance compared to established information retrieval baselines. This work highlights the potential of GNNs for bug localization and established GREPO as a foundation resource for future research, The code is available at https://github.com/qingpingmo/GREPO.
SHINE: A Scalable In-Context Hypernetwork for Mapping Context to LoRA in a Single Pass
Feb 06, 2026We propose SHINE (Scalable Hyper In-context NEtwork), a scalable hypernetwork that can map diverse meaningful contexts into high-quality LoRA adapters for large language models (LLM). By reusing the frozen LLM's own parameters in an in-context hypernetwork design and introducing architectural innovations, SHINE overcomes key limitations of prior hypernetworks and achieves strong expressive power with a relatively small number of parameters. We introduce a pretraining and instruction fine-tuning pipeline, and train our hypernetwork to generate high quality LoRA adapters from diverse meaningful contexts in a single forward pass. It updates LLM parameters without any fine-tuning, and immediately enables complex question answering tasks related to the context without directly accessing the context, effectively transforming in-context knowledge to in-parameter knowledge in one pass. Our work achieves outstanding results on various tasks, greatly saves time, computation and memory costs compared to SFT-based LLM adaptation, and shows great potential for scaling. Our code is available at https://github.com/Yewei-Liu/SHINE
WordCraft: Scaffolding the Keyword Method for L2 Vocabulary Learning with Multimodal LLMs
Jan 31, 2026Applying the keyword method for vocabulary memorization remains a significant challenge for L1 Chinese-L2 English learners. They frequently struggle to generate phonologically appropriate keywords, construct coherent associations, and create vivid mental imagery to aid long-term retention. Existing approaches, including fully automated keyword generation and outcome-oriented mnemonic aids, either compromise learner engagement or lack adequate process-oriented guidance. To address these limitations, we conducted a formative study with L1 Chinese-L2 English learners and educators (N=18), which revealed key difficulties and requirements in applying the keyword method to vocabulary learning. Building on these insights, we introduce WordCraft, a learner-centered interactive tool powered by Multimodal Large Language Models (MLLMs). WordCraft scaffolds the keyword method by guiding learners through keyword selection, association construction, and image formation, thereby enhancing the effectiveness of vocabulary memorization. Two user studies demonstrate that WordCraft not only preserves the generation effect but also achieves high levels of effectiveness and usability.
Diffusion As Self-Distillation: End-to-End Latent Diffusion In One Model
Nov 18, 2025



Standard Latent Diffusion Models rely on a complex, three-part architecture consisting of a separate encoder, decoder, and diffusion network, which are trained in multiple stages. This modular design is computationally inefficient, leads to suboptimal performance, and prevents the unification of diffusion with the single-network architectures common in vision foundation models. Our goal is to unify these three components into a single, end-to-end trainable network. We first demonstrate that a naive joint training approach fails catastrophically due to ``latent collapse'', where the diffusion training objective interferes with the network's ability to learn a good latent representation. We identify the root causes of this instability by drawing a novel analogy between diffusion and self-distillation based unsupervised learning method. Based on this insight, we propose Diffusion as Self-Distillation (DSD), a new framework with key modifications to the training objective that stabilize the latent space. This approach enables, for the first time, the stable end-to-end training of a single network that simultaneously learns to encode, decode, and perform diffusion. DSD achieves outstanding performance on the ImageNet $256\times 256$ conditional generation task: FID=13.44/6.38/4.25 with only 42M/118M/205M parameters and 50 training epochs on ImageNet, without using classifier-free-guidance.
GILT: An LLM-Free, Tuning-Free Graph Foundational Model for In-Context Learning
Oct 06, 2025Graph Neural Networks (GNNs) are powerful tools for precessing relational data but often struggle to generalize to unseen graphs, giving rise to the development of Graph Foundational Models (GFMs). However, current GFMs are challenged by the extreme heterogeneity of graph data, where each graph can possess a unique feature space, label set, and topology. To address this, two main paradigms have emerged. The first leverages Large Language Models (LLMs), but is fundamentally text-dependent, thus struggles to handle the numerical features in vast graphs. The second pre-trains a structure-based model, but the adaptation to new tasks typically requires a costly, per-graph tuning stage, creating a critical efficiency bottleneck. In this work, we move beyond these limitations and introduce \textbf{G}raph \textbf{I}n-context \textbf{L}earning \textbf{T}ransformer (GILT), a framework built on an LLM-free and tuning-free architecture. GILT introduces a novel token-based framework for in-context learning (ICL) on graphs, reframing classification tasks spanning node, edge and graph levels in a unified framework. This mechanism is the key to handling heterogeneity, as it is designed to operate on generic numerical features. Further, its ability to understand class semantics dynamically from the context enables tuning-free adaptation. Comprehensive experiments show that GILT achieves stronger few-shot performance with significantly less time than LLM-based or tuning-based baselines, validating the effectiveness of our approach.
Round-trip Reinforcement Learning: Self-Consistent Training for Better Chemical LLMs
Oct 01, 2025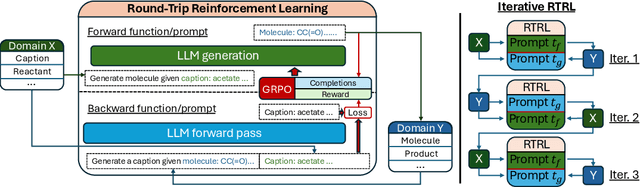
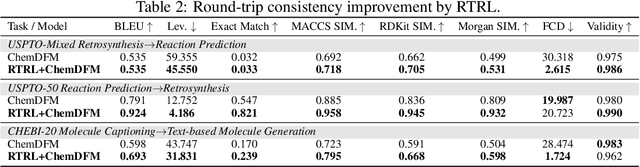
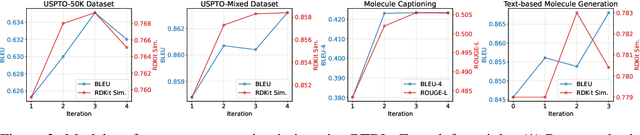
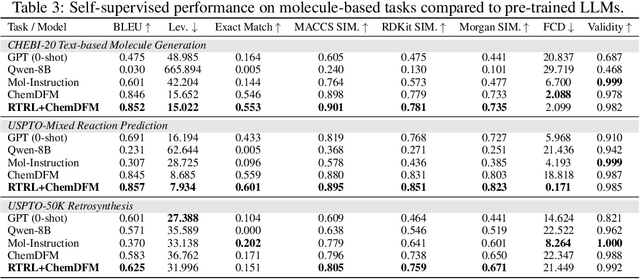
Large Language Models (LLMs) are emerging as versatile foundation models for computational chemistry, handling bidirectional tasks like reaction prediction and retrosynthesis. However, these models often lack round-trip consistency. For instance, a state-of-the-art chemical LLM may successfully caption a molecule, yet be unable to accurately reconstruct the original structure from its own generated text. This inconsistency suggests that models are learning unidirectional memorization rather than flexible mastery. Indeed, recent work has demonstrated a strong correlation between a model's round-trip consistency and its performance on the primary tasks. This strong correlation reframes consistency into a direct target for model improvement. We therefore introduce Round-Trip Reinforcement Learning (RTRL), a novel framework that trains a model to improve its consistency by using the success of a round-trip transformation as a reward signal. We further propose an iterative variant where forward and reverse mappings alternately train each other in a self-improvement loop, a process that is highly data-efficient and notably effective with the massive amount of unlabelled data common in chemistry. Experiments demonstrate that RTRL significantly \textbf{boosts performance and consistency} over strong baselines across supervised, self-supervised, and synthetic data regimes. This work shows that round-trip consistency is not just a desirable property but a trainable objective, offering a new path toward more robust and reliable foundation models.
Be.FM: Open Foundation Models for Human Behavior
May 29, 2025



Despite their success in numerous fields, the potential of foundation models for modeling and understanding human behavior remains largely unexplored. We introduce Be.FM, one of the first open foundation models designed for human behavior modeling. Built upon open-source large language models and fine-tuned on a diverse range of behavioral data, Be.FM can be used to understand and predict human decision-making. We construct a comprehensive set of benchmark tasks for testing the capabilities of behavioral foundation models. Our results demonstrate that Be.FM can predict behaviors, infer characteristics of individuals and populations, generate insights about contexts, and apply behavioral science knowledge.
OCN: Effectively Utilizing Higher-Order Common Neighbors for Better Link Prediction
May 26, 2025



Common Neighbors (CNs) and their higher-order variants are important pairwise features widely used in state-of-the-art link prediction methods. However, existing methods often struggle with the repetition across different orders of CNs and fail to fully leverage their potential. We identify that these limitations stem from two key issues: redundancy and over-smoothing in high-order common neighbors. To address these challenges, we design orthogonalization to eliminate redundancy between different-order CNs and normalization to mitigate over-smoothing. By combining these two techniques, we propose Orthogonal Common Neighbor (OCN), a novel approach that significantly outperforms the strongest baselines by an average of 7.7% on popular link prediction benchmarks. A thorough theoretical analysis is provided to support our method. Ablation studies also verify the effectiveness of our orthogonalization and normalization techniques.