 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeirênes: Adversarial Self-Play with Evolving Distractions for LLM Reasoning
May 12, 2026We present Seirênes, a self-play RL framework that transforms contextual interference from a failure mode of LLM reasoning into an internal training signal for co-evolving more resilient reasoners. While RL with verifiable rewards has significantly advanced reasoning capabilities, models can still exhibit fragility when encountering non-idealized contexts: scenarios characterized by superfluous information, tangential instructions, or incidental correlations that differ from the clean distributions typical of standard benchmarks. Seirênes harnesses this vulnerability through a parameter-shared and adversarial self-play loop. Within this framework, a single model is trained to both construct plausible yet distracting contexts that expose its own reasoning blind spots, and solve problems by discerning the essential task from these perturbations to recover the core underlying logic. By pitting these competing objectives against each other, Seirênes compels the model to move beyond superficial pattern matching and anchors its capabilities in robust underlying reasoning. This continuous interaction sustains an informative co-evolutionary curriculum as the model improves. Across seven mathematical reasoning benchmarks and model scales from 4B to 30B, Seirênes achieves average gains of +10.2, +9.1, and +7.2 points. Besides, distracting contexts produced by the 4B Seirênes model reduce the accuracy of top-tier closed-source models (GPT and Gemini) by roughly 4--5 points, revealing Seirênes' general ability to uncover reasoning models' blind spots.
HISA: Efficient Hierarchical Indexing for Fine-Grained Sparse Attention
Apr 01, 2026Token-level sparse attention mechanisms, exemplified by DeepSeek Sparse Attention (DSA), achieve fine-grained key selection by scoring every historical key for each query through a lightweight indexer, then computing attention only on the selected subset. While the downstream sparse attention itself scales favorably, the indexer must still scan the entire prefix for every query, introducing an per-layer bottleneck that grows prohibitively with context length. We propose HISA (Hierarchical Indexed Sparse Attention), a plug-and-play replacement for the indexer that rewrites the search path from a flat token scan into a two-stage hierarchical procedure: (1) a block-level coarse filtering stage that scores pooled block representations to discard irrelevant regions, followed by (2) a token-level refinement stage that applies the original indexer exclusively within the retained candidate blocks. HISA preserves the identical token-level top-sparse pattern consumed by the downstream Sparse MLA operator and requires no additional training. On kernel-level benchmarks, HISA achieves up to speedup at 64K context. On Needle-in-a-Haystack and LongBench, we directly replace the indexer in DeepSeek-V3.2 and GLM-5 with our HISA indexer, without any finetuning. HISA closely matches the original DSA in quality, while substantially outperforming block-sparse baselines.
AgentGym-RL: Training LLM Agents for Long-Horizon Decision Making through Multi-Turn Reinforcement Learning
Sep 10, 2025Developing autonomous LLM agents capable of making a series of intelligent decisions to solve complex, real-world tasks is a fast-evolving frontier. Like human cognitive development, agents are expected to acquire knowledge and skills through exploration and interaction with the environment. Despite advances, the community still lacks a unified, interactive reinforcement learning (RL) framework that can effectively train such agents from scratch -- without relying on supervised fine-tuning (SFT) -- across diverse and realistic environments. To bridge this gap, we introduce AgentGym-RL, a new framework to train LLM agents for multi-turn interactive decision-making through RL. The framework features a modular and decoupled architecture, ensuring high flexibility and extensibility. It encompasses a wide variety of real-world scenarios, and supports mainstream RL algorithms. Furthermore, we propose ScalingInter-RL, a training approach designed for exploration-exploitation balance and stable RL optimization. In early stages, it emphasizes exploitation by restricting the number of interactions, and gradually shifts towards exploration with larger horizons to encourage diverse problem-solving strategies. In this way, the agent develops more diverse behaviors and is less prone to collapse under long horizons. We perform extensive experiments to validate the stability and effectiveness of both the AgentGym-RL framework and the ScalingInter-RL approach. Our agents match or surpass commercial models on 27 tasks across diverse environments. We offer key insights and will open-source the complete AgentGym-RL framework -- including code and datasets -- to empower the research community in developing the next generation of intelligent agents.
Feedback-Driven Tool-Use Improvements in Large Language Models via Automated Build Environments
Aug 12, 2025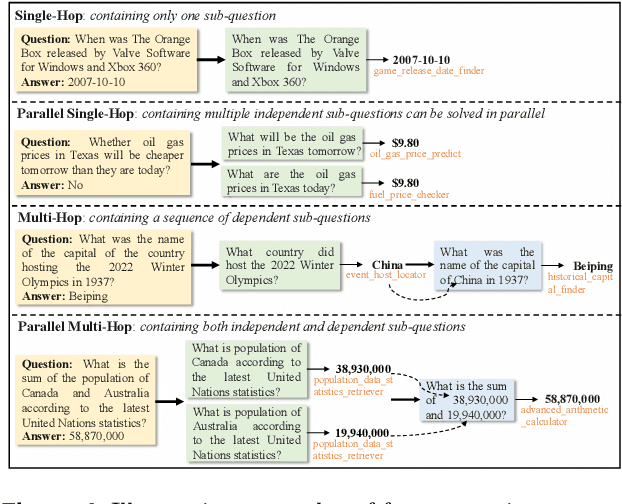

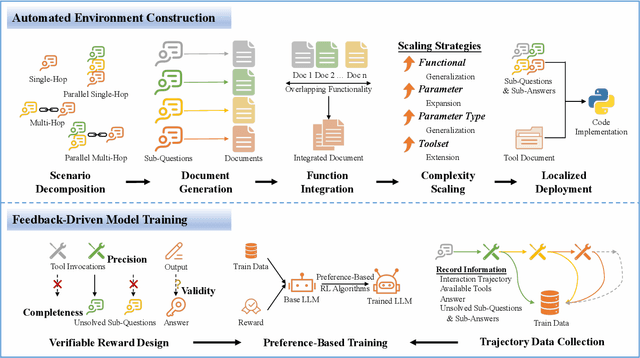
Effective tool use is essential for large language models (LLMs) to interact meaningfully with their environment. However, progress is limited by the lack of efficient reinforcement learning (RL) frameworks specifically designed for tool use, due to challenges in constructing stable training environments and designing verifiable reward mechanisms. To address this, we propose an automated environment construction pipeline, incorporating scenario decomposition, document generation, function integration, complexity scaling, and localized deployment. This enables the creation of high-quality training environments that provide detailed and measurable feedback without relying on external tools. Additionally, we introduce a verifiable reward mechanism that evaluates both the precision of tool use and the completeness of task execution. When combined with trajectory data collected from the constructed environments, this mechanism integrates seamlessly with standard RL algorithms to facilitate feedback-driven model training. Experiments on LLMs of varying scales demonstrate that our approach significantly enhances the models' tool-use performance without degrading their general capabilities, regardless of inference modes or training algorithms. Our analysis suggests that these gains result from improved context understanding and reasoning, driven by updates to the lower-layer MLP parameters in models.
Recitation over Reasoning: How Cutting-Edge Language Models Can Fail on Elementary School-Level Reasoning Problems?
Apr 01, 2025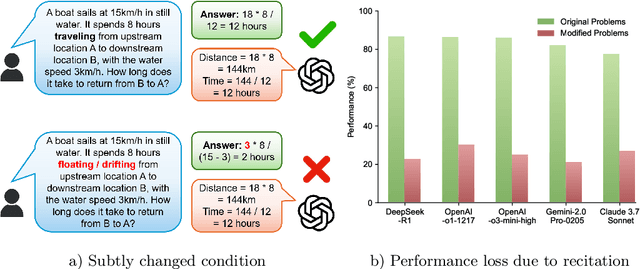
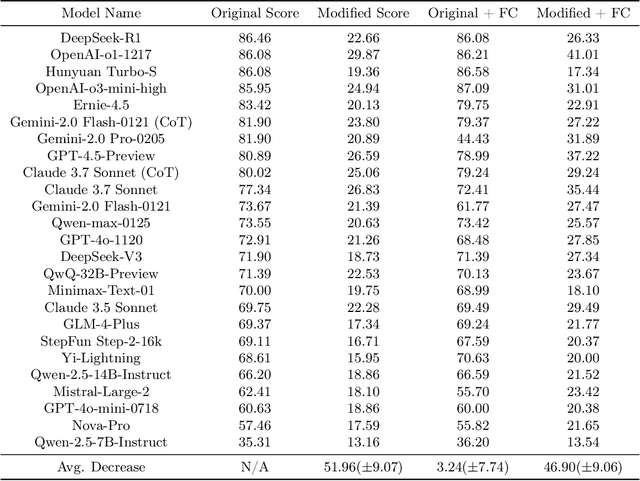

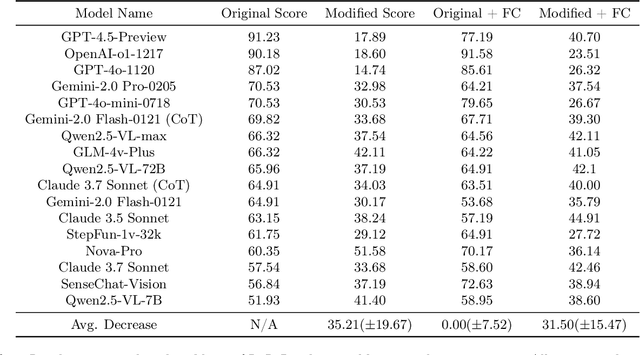
The rapid escalation from elementary school-level to frontier problems of the difficulty for LLM benchmarks in recent years have weaved a miracle for researchers that we are only inches away from surpassing human intelligence. However, is the LLMs' remarkable reasoning ability indeed comes from true intelligence by human standards, or are they simply reciting solutions witnessed during training at an Internet level? To study this problem, we propose RoR-Bench, a novel, multi-modal benchmark for detecting LLM's recitation behavior when asked simple reasoning problems but with conditions subtly shifted, and conduct empirical analysis on our benchmark. Surprisingly, we found existing cutting-edge LLMs unanimously exhibits extremely severe recitation behavior; by changing one phrase in the condition, top models such as OpenAI-o1 and DeepSeek-R1 can suffer $60\%$ performance loss on elementary school-level arithmetic and reasoning problems. Such findings are a wake-up call to the LLM community that compels us to re-evaluate the true intelligence level of cutting-edge LLMs.
LIFT: Improving Long Context Understanding of Large Language Models through Long Input Fine-Tuning
Feb 20, 2025Long context understanding remains challenging for large language models due to their limited context windows. This paper presents Long Input Fine-Tuning (LIFT), a novel framework for long-context modeling that can improve the long-context performance of arbitrary (short-context) LLMs by dynamically adapting model parameters based on the long input. Importantly, LIFT, rather than endlessly extending the context window size to accommodate increasingly longer inputs in context, chooses to store and absorb the long input in parameter. By fine-tuning the long input into model parameters, LIFT allows short-context LLMs to answer questions even when the required information is not provided in the context during inference. Furthermore, to enhance LIFT performance while maintaining the original in-context learning (ICL) capabilities, we introduce Gated Memory, a specialized attention adapter that automatically balances long input memorization and ICL. We provide a comprehensive analysis of the strengths and limitations of LIFT on long context understanding, offering valuable directions for future research.
ToolHop: A Query-Driven Benchmark for Evaluating Large Language Models in Multi-Hop Tool Use
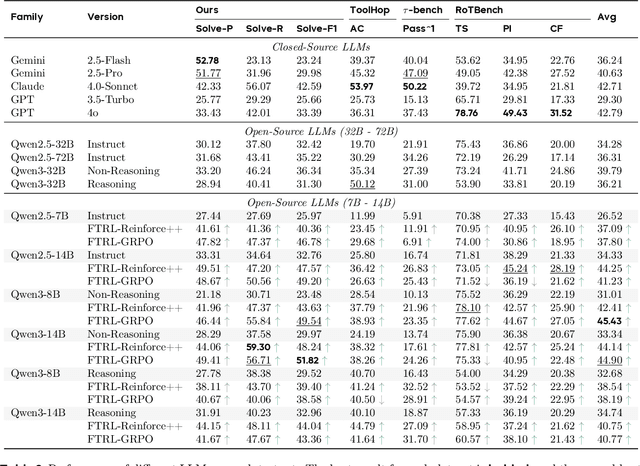
Jan 07, 2025Effective evaluation of multi-hop tool use is critical for analyzing the understanding, reasoning, and function-calling capabilities of large language models (LLMs). However, progress has been hindered by a lack of reliable evaluation datasets. To address this, we present ToolHop, a dataset comprising 995 user queries and 3,912 associated tools, specifically designed for rigorous evaluation of multi-hop tool use. ToolHop ensures diverse queries, meaningful interdependencies, locally executable tools, detailed feedback, and verifiable answers through a novel query-driven data construction approach that includes tool creation, document refinement, and code generation. We evaluate 14 LLMs across five model families (i.e., LLaMA3.1, Qwen2.5, Gemini1.5, Claude3.5, and GPT), uncovering significant challenges in handling multi-hop tool-use scenarios. The leading model, GPT-4o, achieves an accuracy of 49.04%, underscoring substantial room for improvement. Further analysis reveals variations in tool-use strategies for various families, offering actionable insights to guide the development of more effective approaches. Code and data can be found in https://huggingface.co/datasets/bytedance-research/ToolHop.
When ControlNet Meets Inexplicit Masks: A Case Study of ControlNet on its Contour-following Ability
Mar 01, 2024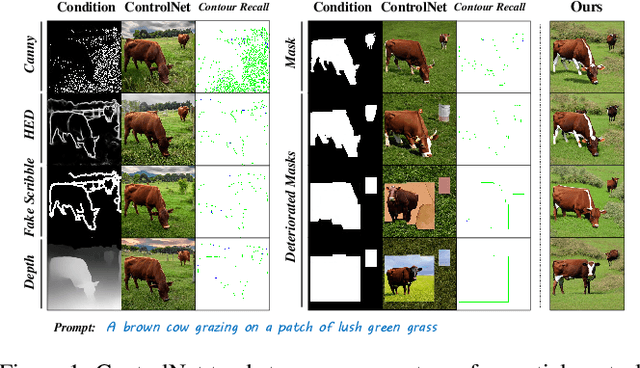
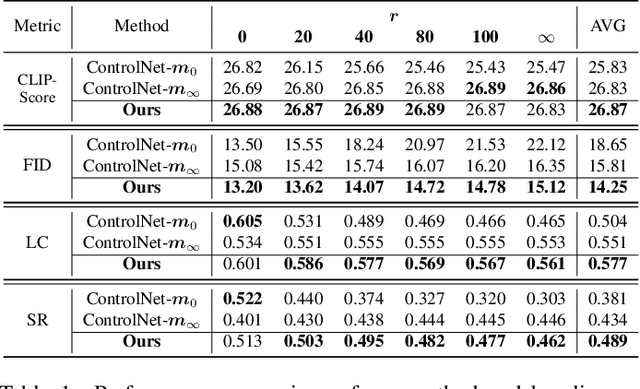


ControlNet excels at creating content that closely matches precise contours in user-provided masks. However, when these masks contain noise, as a frequent occurrence with non-expert users, the output would include unwanted artifacts. This paper first highlights the crucial role of controlling the impact of these inexplicit masks with diverse deterioration levels through in-depth analysis. Subsequently, to enhance controllability with inexplicit masks, an advanced Shape-aware ControlNet consisting of a deterioration estimator and a shape-prior modulation block is devised. The deterioration estimator assesses the deterioration factor of the provided masks. Then this factor is utilized in the modulation block to adaptively modulate the model's contour-following ability, which helps it dismiss the noise part in the inexplicit masks. Extensive experiments prove its effectiveness in encouraging ControlNet to interpret inaccurate spatial conditions robustly rather than blindly following the given contours. We showcase application scenarios like modifying shape priors and composable shape-controllable generation. Codes are soon available.
APTv2: Benchmarking Animal Pose Estimation and Tracking with a Large-scale Dataset and Beyond
Dec 25, 2023Animal Pose Estimation and Tracking (APT) is a critical task in detecting and monitoring the keypoints of animals across a series of video frames, which is essential for understanding animal behavior. Past works relating to animals have primarily focused on either animal tracking or single-frame animal pose estimation only, neglecting the integration of both aspects. The absence of comprehensive APT datasets inhibits the progression and evaluation of animal pose estimation and tracking methods based on videos, thereby constraining their real-world applications. To fill this gap, we introduce APTv2, the pioneering large-scale benchmark for animal pose estimation and tracking. APTv2 comprises 2,749 video clips filtered and collected from 30 distinct animal species. Each video clip includes 15 frames, culminating in a total of 41,235 frames. Following meticulous manual annotation and stringent verification, we provide high-quality keypoint and tracking annotations for a total of 84,611 animal instances, split into easy and hard subsets based on the number of instances that exists in the frame. With APTv2 as the foundation, we establish a simple baseline method named \posetrackmethodname and provide benchmarks for representative models across three tracks: (1) single-frame animal pose estimation track to evaluate both intra- and inter-domain transfer learning performance, (2) low-data transfer and generalization track to evaluate the inter-species domain generalization performance, and (3) animal pose tracking track. Our experimental results deliver key empirical insights, demonstrating that APTv2 serves as a valuable benchmark for animal pose estimation and tracking. It also presents new challenges and opportunities for future research. The code and dataset are released at \href{https://github.com/ViTAE-Transformer/APTv2}{https://github.com/ViTAE-Transformer/APTv2}.
HandRefiner: Refining Malformed Hands in Generated Images by Diffusion-based Conditional Inpainting
Nov 29, 2023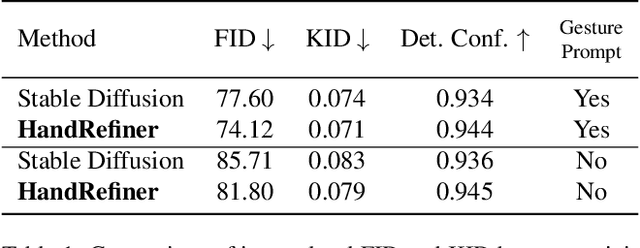
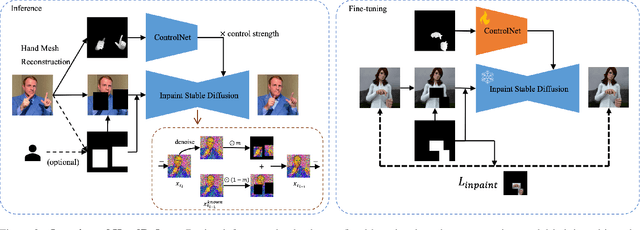


Diffusion models have achieved remarkable success in generating realistic images but suffer from generating accurate human hands, such as incorrect finger counts or irregular shapes. This difficulty arises from the complex task of learning the physical structure and pose of hands from training images, which involves extensive deformations and occlusions. For correct hand generation, our paper introduces a lightweight post-processing solution called $\textbf{HandRefiner}$. HandRefiner employs a conditional inpainting approach to rectify malformed hands while leaving other parts of the image untouched. We leverage the hand mesh reconstruction model that consistently adheres to the correct number of fingers and hand shape, while also being capable of fitting the desired hand pose in the generated image. Given a generated failed image due to malformed hands, we utilize ControlNet modules to re-inject such correct hand information. Additionally, we uncover a phase transition phenomenon within ControlNet as we vary the control strength. It enables us to take advantage of more readily available synthetic data without suffering from the domain gap between realistic and synthetic hands. Experiments demonstrate that HandRefiner can significantly improve the generation quality quantitatively and qualitatively. The code is available at https://github.com/wenquanlu/HandRefiner .