 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeULW-SleepNet: An Ultra-Lightweight Network for Multimodal Sleep Stage Scoring
Feb 27, 2026Automatic sleep stage scoring is crucial for the diagnosis and treatment of sleep disorders. Although deep learning models have advanced the field, many existing models are computationally demanding and designed for single-channel electroencephalography (EEG), limiting their practicality for multimodal polysomnography (PSG) data. To overcome this, we propose ULW-SleepNet, an ultra-lightweight multimodal sleep stage scoring framework that efficiently integrates information from multiple physiological signals. ULW-SleepNet incorporates a novel Dual-Stream Separable Convolution (DSSC) Block, depthwise separable convolutions, channel-wise parameter sharing, and global average pooling to reduce computational overhead while maintaining competitive accuracy. Evaluated on the Sleep-EDF-20 and Sleep-EDF-78 datasets, ULW-SleepNet achieves accuracies of 86.9% and 81.4%, respectively, with only 13.3K parameters and 7.89M FLOPs. Compared to state-of-the-art methods, our model reduces parameters by up to 98.6% with only marginal performance loss, demonstrating its strong potential for real-time sleep monitoring on wearable and IoT devices. The source code for this study is publicly available at https://github.com/wzw999/ULW-SLEEPNET.
Generalized Reference Kernel With Negative Samples For Support Vector One-class Classification
Jun 17, 2025This paper focuses on small-scale one-class classification with some negative samples available. We propose Generalized Reference Kernel with Negative Samples (GRKneg) for One-class Support Vector Machine (OC-SVM). We study different ways to select/generate the reference vectors and recommend an approach for the problem at hand. It is worth noting that the proposed method does not use any labels in the model optimization but uses the original OC-SVM implementation. Only the kernel used in the process is improved using the negative data. We compare our method with the standard OC-SVM and with the binary Support Vector Machine (SVM) using different amounts of negative samples. Our approach consistently outperforms the standard OC-SVM using Radial Basis Function kernel. When there are plenty of negative samples, the binary SVM outperforms the one-class approaches as expected, but we show that for the lowest numbers of negative samples the proposed approach clearly outperforms the binary SVM.
AquaMonitor: A multimodal multi-view image sequence dataset for real-life aquatic invertebrate biodiversity monitoring
May 28, 2025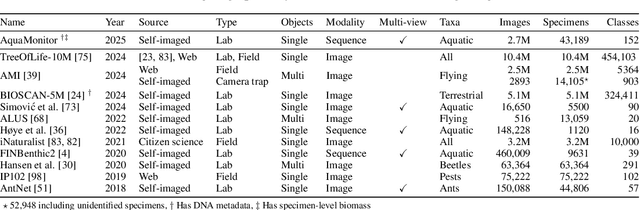
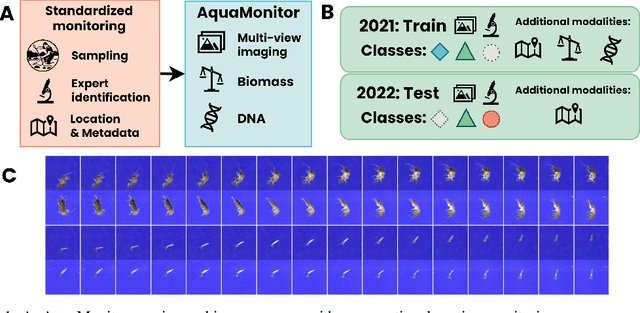
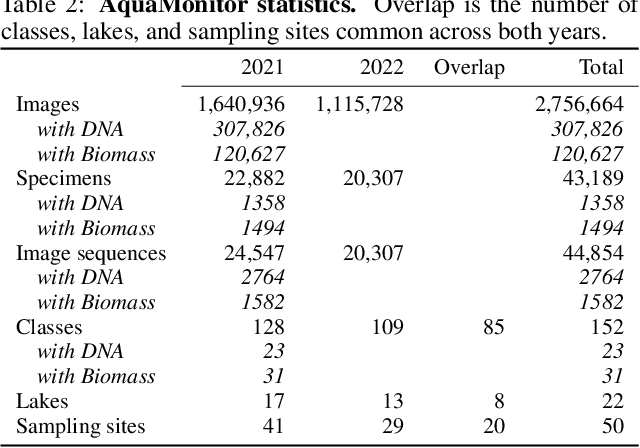
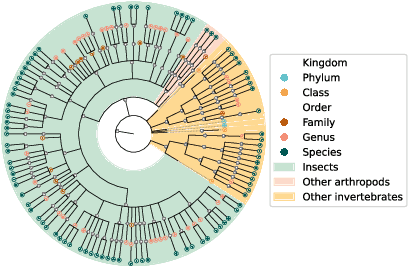
This paper presents the AquaMonitor dataset, the first large computer vision dataset of aquatic invertebrates collected during routine environmental monitoring. While several large species identification datasets exist, they are rarely collected using standardized collection protocols, and none focus on aquatic invertebrates, which are particularly laborious to collect. For AquaMonitor, we imaged all specimens from two years of monitoring whenever imaging was possible given practical limitations. The dataset enables the evaluation of automated identification methods for real-life monitoring purposes using a realistically challenging and unbiased setup. The dataset has 2.7M images from 43,189 specimens, DNA sequences for 1358 specimens, and dry mass and size measurements for 1494 specimens, making it also one of the largest biological multi-view and multimodal datasets to date. We define three benchmark tasks and provide strong baselines for these: 1) Monitoring benchmark, reflecting real-life deployment challenges such as open-set recognition, distribution shift, and extreme class imbalance, 2) Classification benchmark, which follows a standard fine-grained visual categorization setup, and 3) Few-shot benchmark, which targets classes with only few training examples from very fine-grained categories. Advancements on the Monitoring benchmark can directly translate to improvement of aquatic biodiversity monitoring, which is an important component of regular legislative water quality assessment in many countries.
Efficient Curation of Invertebrate Image Datasets Using Feature Embeddings and Automatic Size Comparison
Dec 20, 2024The amount of image datasets collected for environmental monitoring purposes has increased in the past years as computer vision assisted methods have gained interest. Computer vision applications rely on high-quality datasets, making data curation important. However, data curation is often done ad-hoc and the methods used are rarely published. We present a method for curating large-scale image datasets of invertebrates that contain multiple images of the same taxa and/or specimens and have relatively uniform background in the images. Our approach is based on extracting feature embeddings with pretrained deep neural networks, and using these embeddings to find visually most distinct images by comparing their embeddings to the group prototype embedding. Also, we show that a simple area-based size comparison approach is able to find a lot of common erroneous images, such as images containing detached body parts and misclassified samples. In addition to the method, we propose using novel metrics for evaluating human-in-the-loop outlier detection methods. The implementations of the proposed curation methods, as well as a benchmark dataset containing annotated erroneous images, are publicly available in https://github.com/mikkoim/taxonomist-studio.
Linear-time One-Class Classification with Repeated Element-wise Folding
Aug 21, 2024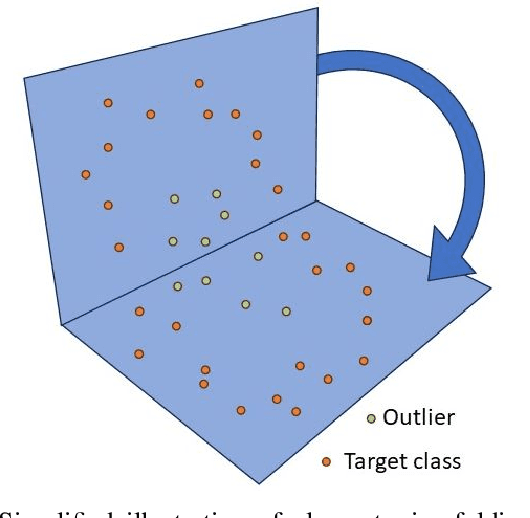
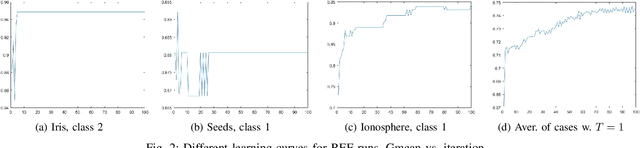
This paper proposes an easy-to-use method for one-class classification: Repeated Element-wise Folding (REF). The algorithm consists of repeatedly standardizing and applying an element-wise folding operation on the one-class training data. Equivalent mappings are performed on unknown test items and the classification prediction is based on the item's distance to the origin of the final distribution. As all the included operations have linear time complexity, the proposed algorithm provides a linear-time alternative for the commonly used computationally much more demanding approaches. Furthermore, REF can avoid the challenges of hyperparameter setting in one-class classification by providing robust default settings. The experiments show that the proposed method can produce similar classification performance or even outperform the more complex algorithms on various benchmark datasets. Matlab codes for REF are publicly available at https://github.com/JenniRaitoharju/REF.
Improving Taxonomic Image-based Out-of-distribution Detection With DNA Barcodes
Jun 27, 2024Image-based species identification could help scaling biodiversity monitoring to a global scale. Many challenges still need to be solved in order to implement these systems in real-world applications. A reliable image-based monitoring system must detect out-of-distribution (OOD) classes it has not been presented before. This is challenging especially with fine-grained classes. Emerging environmental monitoring techniques, DNA metabarcoding and eDNA, can help by providing information on OOD classes that are present in a sample. In this paper, we study if DNA barcodes can also support in finding the outlier images based on the outlier DNA sequence's similarity to the seen classes. We propose a re-ordering approach that can be easily applied on any pre-trained models and existing OOD detection methods. We experimentally show that the proposed approach improves taxonomic OOD detection compared to all common baselines. We also show that the method works thanks to a correlation between visual similarity and DNA barcode proximity. The code and data are available at https://github.com/mikkoim/dnaimg-ood.
Convolutional autoencoder-based multimodal one-class classification
Sep 25, 2023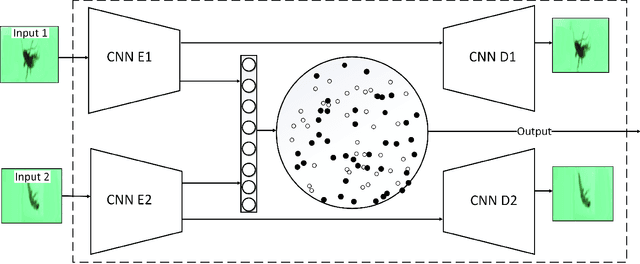
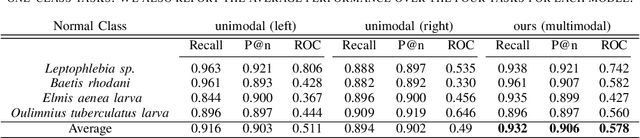

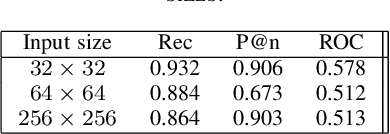
One-class classification refers to approaches of learning using data from a single class only. In this paper, we propose a deep learning one-class classification method suitable for multimodal data, which relies on two convolutional autoencoders jointly trained to reconstruct the positive input data while obtaining the data representations in the latent space as compact as possible. During inference, the distance of the latent representation of an input to the origin can be used as an anomaly score. Experimental results using a multimodal macroinvertebrate image classification dataset show that the proposed multimodal method yields better results as compared to the unimodal approach. Furthermore, study the effect of different input image sizes, and we investigate how recently proposed feature diversity regularizers affect the performance of our approach. We show that such regularizers improve performance.
On Feature Diversity in Energy-based Models
Jun 02, 2023Energy-based learning is a powerful learning paradigm that encapsulates various discriminative and generative approaches. An energy-based model (EBM) is typically formed of inner-model(s) that learn a combination of the different features to generate an energy mapping for each input configuration. In this paper, we focus on the diversity of the produced feature set. We extend the probably approximately correct (PAC) theory of EBMs and analyze the effect of redundancy reduction on the performance of EBMs. We derive generalization bounds for various learning contexts, i.e., regression, classification, and implicit regression, with different energy functions and we show that indeed reducing redundancy of the feature set can consistently decrease the gap between the true and empirical expectation of the energy and boosts the performance of the model.
WLD-Reg: A Data-dependent Within-layer Diversity Regularizer
Jan 03, 2023
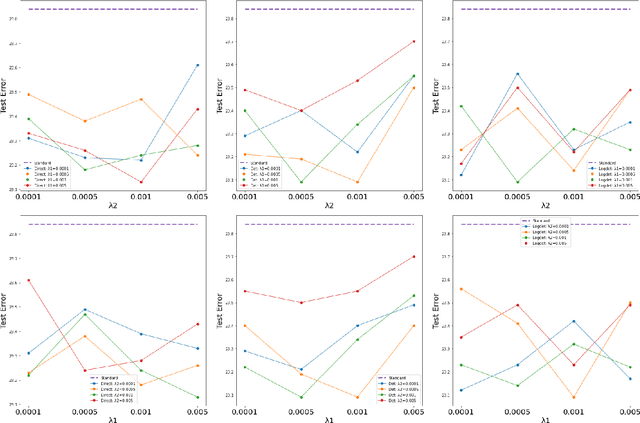

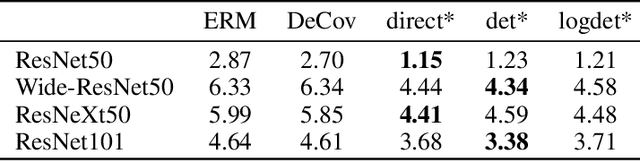
Neural networks are composed of multiple layers arranged in a hierarchical structure jointly trained with a gradient-based optimization, where the errors are back-propagated from the last layer back to the first one. At each optimization step, neurons at a given layer receive feedback from neurons belonging to higher layers of the hierarchy. In this paper, we propose to complement this traditional 'between-layer' feedback with additional 'within-layer' feedback to encourage the diversity of the activations within the same layer. To this end, we measure the pairwise similarity between the outputs of the neurons and use it to model the layer's overall diversity. We present an extensive empirical study confirming that the proposed approach enhances the performance of several state-of-the-art neural network models in multiple tasks. The code is publically available at \url{https://github.com/firasl/AAAI-23-WLD-Reg}
1st Workshop on Maritime Computer Vision 2023: Challenge Results
Nov 28, 2022

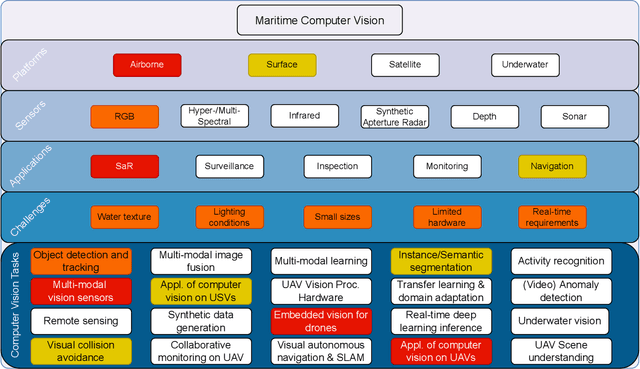
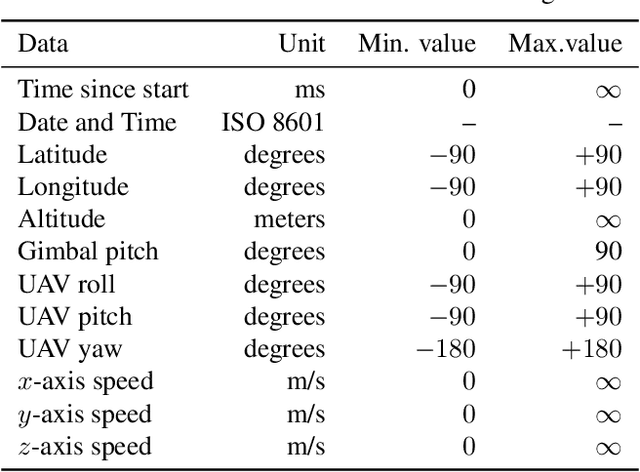
The 1$^{\text{st}}$ Workshop on Maritime Computer Vision (MaCVi) 2023 focused on maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicle (USV), and organized several subchallenges in this domain: (i) UAV-based Maritime Object Detection, (ii) UAV-based Maritime Object Tracking, (iii) USV-based Maritime Obstacle Segmentation and (iv) USV-based Maritime Obstacle Detection. The subchallenges were based on the SeaDronesSee and MODS benchmarks. This report summarizes the main findings of the individual subchallenges and introduces a new benchmark, called SeaDronesSee Object Detection v2, which extends the previous benchmark by including more classes and footage. We provide statistical and qualitative analyses, and assess trends in the best-performing methodologies of over 130 submissions. The methods are summarized in the appendix. The datasets, evaluation code and the leaderboard are publicly available at https://seadronessee.cs.uni-tuebingen.de/macvi.