 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Vaccinate or not to Vaccinate? Analyzing $\mathbb{X}$ Power over the Pandemic
Mar 04, 2025



The COVID-19 pandemic has profoundly affected the normal course of life -- from lock-downs and virtual meetings to the unprecedentedly swift creation of vaccines. To halt the COVID-19 pandemic, the world has started preparing for the global vaccine roll-out. In an effort to navigate the immense volume of information about COVID-19, the public has turned to social networks. Among them, $\mathbb{X}$ (formerly Twitter) has played a key role in distributing related information. Most people are not trained to interpret medical research and remain skeptical about the efficacy of new vaccines. Measuring their reactions and perceptions is gaining significance in the fight against COVID-19. To assess the public perception regarding the COVID-19 vaccine, our work applies a sentiment analysis approach, using natural language processing of $\mathbb{X}$ data. We show how to use textual analytics and textual data visualization to discover early insights (for example, by analyzing the most frequently used keywords and hashtags). Furthermore, we look at how people's sentiments vary across the countries. Our results indicate that although the overall reaction to the vaccine is positive, there are also negative sentiments associated with the tweets, especially when examined at the country level. Additionally, from the extracted tweets, we manually labeled 100 tweets as positive and 100 tweets as negative and trained various One-Class Classifiers (OCCs). The experimental results indicate that the S-SVDD classifiers outperform other OCCs.
Anomaly Detection in Smart Power Grids with Graph-Regularized MS-SVDD: a Multimodal Subspace Learning Approach
Feb 18, 2025



In this paper, we address an anomaly detection problem in smart power grids using Multimodal Subspace Support Vector Data Description (MS-SVDD). This approach aims to leverage better feature relations by considering the data as coming from different modalities. These data are projected into a shared lower-dimensionality subspace which aims to preserve their inner characteristics. To supplement the previous work on this subject, we introduce novel multimodal graph-embedded regularizers that leverage graph information for every modality to enhance the training process, and we consider an improved training equation that allows us to maximize or minimize each modality according to the specified criteria. We apply this regularized graph-embedded model on a 3-modalities dataset after having generalized MS-SVDD algorithms to any number of modalities. To set up our application, we propose a whole preprocessing procedure to extract One-Class Classification training instances from time-bounded event time series that are used to evaluate both the reliability and earliness of our model for Event Detection.
Deep-BrownConrady: Prediction of Camera Calibration and Distortion Parameters Using Deep Learning and Synthetic Data
Jan 24, 2025



This research addresses the challenge of camera calibration and distortion parameter prediction from a single image using deep learning models. The main contributions of this work are: (1) demonstrating that a deep learning model, trained on a mix of real and synthetic images, can accurately predict camera and lens parameters from a single image, and (2) developing a comprehensive synthetic dataset using the AILiveSim simulation platform. This dataset includes variations in focal length and lens distortion parameters, providing a robust foundation for model training and testing. The training process predominantly relied on these synthetic images, complemented by a small subset of real images, to explore how well models trained on synthetic data can perform calibration tasks on real-world images. Traditional calibration methods require multiple images of a calibration object from various orientations, which is often not feasible due to the lack of such images in publicly available datasets. A deep learning network based on the ResNet architecture was trained on this synthetic dataset to predict camera calibration parameters following the Brown-Conrady lens model. The ResNet architecture, adapted for regression tasks, is capable of predicting continuous values essential for accurate camera calibration in applications such as autonomous driving, robotics, and augmented reality. Keywords: Camera calibration, distortion, synthetic data, deep learning, residual networks (ResNet), AILiveSim, horizontal field-of-view, principal point, Brown-Conrady Model.
Conformal Prediction on Quantifying Uncertainty of Dynamic Systems
Dec 17, 2024



Numerous studies have focused on learning and understanding the dynamics of physical systems from video data, such as spatial intelligence. Artificial intelligence requires quantitative assessments of the uncertainty of the model to ensure reliability. However, there is still a relative lack of systematic assessment of the uncertainties, particularly the uncertainties of the physical data. Our motivation is to introduce conformal prediction into the uncertainty assessment of dynamical systems, providing a method supported by theoretical guarantees. This paper uses the conformal prediction method to assess uncertainties with benchmark operator learning methods. We have also compared the Monte Carlo Dropout and Ensemble methods in the partial differential equations dataset, effectively evaluating uncertainty through straight roll-outs, making it ideal for time-series tasks.
Audio-based Anomaly Detection in Industrial Machines Using Deep One-Class Support Vector Data Description
Dec 14, 2024The frequent breakdowns and malfunctions of industrial equipment have driven increasing interest in utilizing cost-effective and easy-to-deploy sensors, such as microphones, for effective condition monitoring of machinery. Microphones offer a low-cost alternative to widely used condition monitoring sensors with their high bandwidth and capability to detect subtle anomalies that other sensors might have less sensitivity. In this study, we investigate malfunctioning industrial machines to evaluate and compare anomaly detection performance across different machine types and fault conditions. Log-Mel spectrograms of machinery sound are used as input, and the performance is evaluated using the area under the curve (AUC) score for two different methods: baseline dense autoencoder (AE) and one-class deep Support Vector Data Description (deep SVDD) with different subspace dimensions. Our results over the MIMII sound dataset demonstrate that the deep SVDD method with a subspace dimension of 2 provides superior anomaly detection performance, achieving average AUC scores of 0.84, 0.80, and 0.69 for 6 dB, 0 dB, and -6 dB signal-to-noise ratios (SNRs), respectively, compared to 0.82, 0.72, and 0.64 for the baseline model. Moreover, deep SVDD requires 7.4 times fewer trainable parameters than the baseline dense AE, emphasizing its advantage in both effectiveness and computational efficiency.
Refining Myocardial Infarction Detection: A Novel Multi-Modal Composite Kernel Strategy in One-Class Classification
Feb 09, 2024


Early detection of myocardial infarction (MI), a critical condition arising from coronary artery disease (CAD), is vital to prevent further myocardial damage. This study introduces a novel method for early MI detection using a one-class classification (OCC) algorithm in echocardiography. Our study overcomes the challenge of limited echocardiography data availability by adopting a novel approach based on Multi-modal Subspace Support Vector Data Description. The proposed technique involves a specialized MI detection framework employing multi-view echocardiography incorporating a composite kernel in the non-linear projection trick, fusing Gaussian and Laplacian sigmoid functions. Additionally, we enhance the update strategy of the projection matrices by adapting maximization for both or one of the modalities in the optimization process. Our method boosts MI detection capability by efficiently transforming features extracted from echocardiography data into an optimized lower-dimensional subspace. The OCC model trained specifically on target class instances from the comprehensive HMC-QU dataset that includes multiple echocardiography views indicates a marked improvement in MI detection accuracy. Our findings reveal that our proposed multi-view approach achieves a geometric mean of 71.24\%, signifying a substantial advancement in echocardiography-based MI diagnosis and offering more precise and efficient diagnostic tools.
Trustworthiness of $\mathbb{X}$ Users: A One-Class Classification Approach
Feb 03, 2024
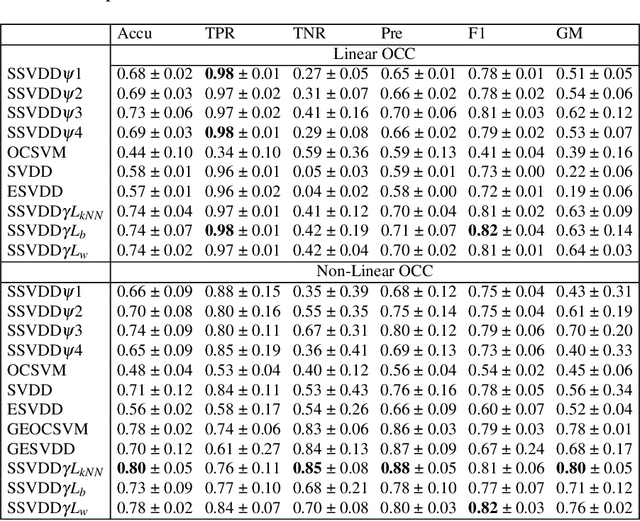
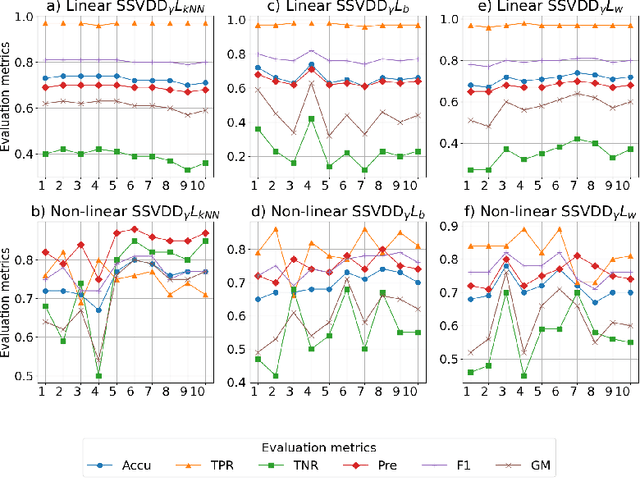
$\mathbb{X}$ (formerly Twitter) is a prominent online social media platform that plays an important role in sharing information making the content generated on this platform a valuable source of information. Ensuring trust on $\mathbb{X}$ is essential to determine the user credibility and prevents issues across various domains. While assigning credibility to $\mathbb{X}$ users and classifying them as trusted or untrusted is commonly carried out using traditional machine learning models, there is limited exploration about the use of One-Class Classification (OCC) models for this purpose. In this study, we use various OCC models for $\mathbb{X}$ user classification. Additionally, we propose using a subspace-learning-based approach that simultaneously optimizes both the subspace and data description for OCC. We also introduce a novel regularization term for Subspace Support Vector Data Description (SSVDD), expressing data concentration in a lower-dimensional subspace that captures diverse graph structures. Experimental results show superior performance of the introduced regularization term for SSVDD compared to baseline models and state-of-the-art techniques for $\mathbb{X}$ user classification.
Credit Card Fraud Detection with Subspace Learning-based One-Class Classification
Sep 26, 2023


In an increasingly digitalized commerce landscape, the proliferation of credit card fraud and the evolution of sophisticated fraudulent techniques have led to substantial financial losses. Automating credit card fraud detection is a viable way to accelerate detection, reducing response times and minimizing potential financial losses. However, addressing this challenge is complicated by the highly imbalanced nature of the datasets, where genuine transactions vastly outnumber fraudulent ones. Furthermore, the high number of dimensions within the feature set gives rise to the ``curse of dimensionality". In this paper, we investigate subspace learning-based approaches centered on One-Class Classification (OCC) algorithms, which excel in handling imbalanced data distributions and possess the capability to anticipate and counter the transactions carried out by yet-to-be-invented fraud techniques. The study highlights the potential of subspace learning-based OCC algorithms by investigating the limitations of current fraud detection strategies and the specific challenges of credit card fraud detection. These algorithms integrate subspace learning into the data description; hence, the models transform the data into a lower-dimensional subspace optimized for OCC. Through rigorous experimentation and analysis, the study validated that the proposed approach helps tackle the curse of dimensionality and the imbalanced nature of credit card data for automatic fraud detection to mitigate financial losses caused by fraudulent activities.
One-Class Classification for Intrusion Detection on Vehicular Networks
Sep 25, 2023

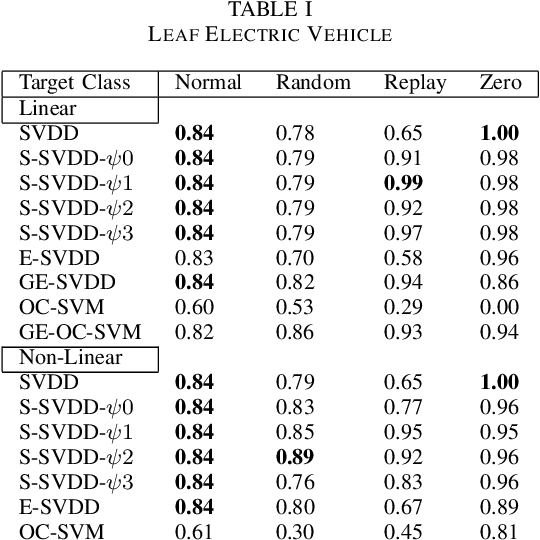
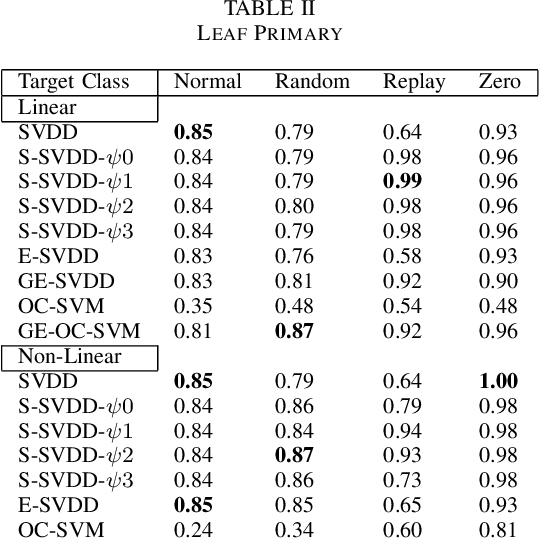
Controller Area Network bus systems within vehicular networks are not equipped with the tools necessary to ward off and protect themselves from modern cyber-security threats. Work has been done on using machine learning methods to detect and report these attacks, but common methods are not robust towards unknown attacks. These methods usually rely on there being a sufficient representation of attack data, which may not be available due to there either not being enough data present to adequately represent its distribution or the distribution itself is too diverse in nature for there to be a sufficient representation of it. With the use of one-class classification methods, this issue can be mitigated as only normal data is required to train a model for the detection of anomalous instances. Research has been done on the efficacy of these methods, most notably One-Class Support Vector Machine and Support Vector Data Description, but many new extensions of these works have been proposed and have yet to be tested for injection attacks in vehicular networks. In this paper, we investigate the performance of various state-of-the-art one-class classification methods for detecting injection attacks on Controller Area Network bus traffic. We investigate the effectiveness of these techniques on attacks launched on Controller Area Network buses from two different vehicles during normal operation and while being attacked. We observe that the Subspace Support Vector Data Description method outperformed all other tested methods with a Gmean of about 85%.
Convolutional autoencoder-based multimodal one-class classification
Sep 25, 2023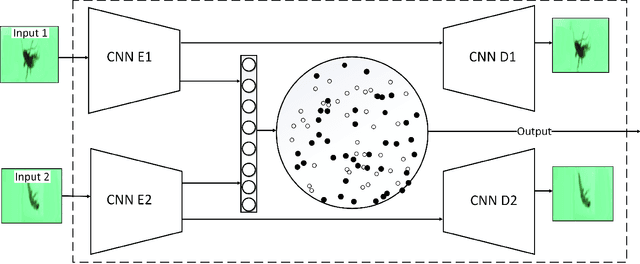
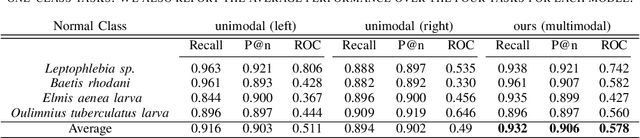

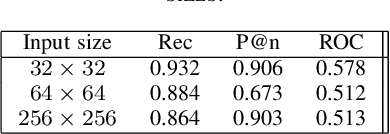
One-class classification refers to approaches of learning using data from a single class only. In this paper, we propose a deep learning one-class classification method suitable for multimodal data, which relies on two convolutional autoencoders jointly trained to reconstruct the positive input data while obtaining the data representations in the latent space as compact as possible. During inference, the distance of the latent representation of an input to the origin can be used as an anomaly score. Experimental results using a multimodal macroinvertebrate image classification dataset show that the proposed multimodal method yields better results as compared to the unimodal approach. Furthermore, study the effect of different input image sizes, and we investigate how recently proposed feature diversity regularizers affect the performance of our approach. We show that such regularizers improve performance.