 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarbon-Aware Governance Gates: An Architecture for Sustainable GenAI Development
Feb 23, 2026The rapid adoption of Generative AI (GenAI) in the software development life cycle (SDLC) increases computational demand, which can raise the carbon footprint of development activities. At the same time, organizations are increasingly embedding governance mechanisms into GenAI-assisted development to support trust, transparency, and accountability. However, these governance mechanisms introduce additional computational workloads, including repeated inference, regeneration cycles, and expanded validation pipelines, increasing energy use and the carbon footprint of GenAI-assisted development. This paper proposes Carbon-Aware Governance Gates (CAGG), an architectural extension that embeds carbon budgets, energy provenance, and sustainability-aware validation orchestration into human-AI governance layers. CAGG comprises three components: (i) an Energy and Carbon Provenance Ledger, (ii) a Carbon Budget Manager, and (iii) a Green Validation Orchestrator, operationalized through governance policies and reusable design patterns.
Towards AI Evaluation in Domain-Specific RAG Systems: The AgriHubi Case Study
Feb 02, 2026Large language models show promise for knowledge-intensive domains, yet their use in agriculture is constrained by weak grounding, English-centric training data, and limited real-world evaluation. These issues are amplified for low-resource languages, where high-quality domain documentation exists but remains difficult to access through general-purpose models. This paper presents AgriHubi, a domain-adapted retrieval-augmented generation (RAG) system for Finnish-language agricultural decision support. AgriHubi integrates Finnish agricultural documents with open PORO family models and combines explicit source grounding with user feedback to support iterative refinement. Developed over eight iterations and evaluated through two user studies, the system shows clear gains in answer completeness, linguistic accuracy, and perceived reliability. The results also reveal practical trade-offs between response quality and latency when deploying larger models. This study provides empirical guidance for designing and evaluating domain-specific RAG systems in low-resource language settings.
Vibe Coding in Practice: Flow, Technical Debt, and Guidelines for Sustainable Use
Dec 11, 2025Vibe Coding (VC) is a form of software development assisted by generative AI, in which developers describe the intended functionality or logic via natural language prompts, and the AI system generates the corresponding source code. VC can be leveraged for rapid prototyping or developing the Minimum Viable Products (MVPs); however, it may introduce several risks throughout the software development life cycle. Based on our experience from several internally developed MVPs and a review of recent industry reports, this article analyzes the flow-debt tradeoffs associated with VC. The flow-debt trade-off arises when the seamless code generation occurs, leading to the accumulation of technical debt through architectural inconsistencies, security vulnerabilities, and increased maintenance overhead. These issues originate from process-level weaknesses, biases in model training data, a lack of explicit design rationale, and a tendency to prioritize quick code generation over human-driven iterative development. Based on our experiences, we identify and explain how current model, platform, and hardware limitations contribute to these issues, and propose countermeasures to address them, informing research and practice towards more sustainable VC approaches.
Engineering RAG Systems for Real-World Applications: Design, Development, and Evaluation
Jun 25, 2025Retrieval-Augmented Generation (RAG) systems are emerging as a key approach for grounding Large Language Models (LLMs) in external knowledge, addressing limitations in factual accuracy and contextual relevance. However, there is a lack of empirical studies that report on the development of RAG-based implementations grounded in real-world use cases, evaluated through general user involvement, and accompanied by systematic documentation of lessons learned. This paper presents five domain-specific RAG applications developed for real-world scenarios across governance, cybersecurity, agriculture, industrial research, and medical diagnostics. Each system incorporates multilingual OCR, semantic retrieval via vector embeddings, and domain-adapted LLMs, deployed through local servers or cloud APIs to meet distinct user needs. A web-based evaluation involving a total of 100 participants assessed the systems across six dimensions: (i) Ease of Use, (ii) Relevance, (iii) Transparency, (iv) Responsiveness, (v) Accuracy, and (vi) Likelihood of Recommendation. Based on user feedback and our development experience, we documented twelve key lessons learned, highlighting technical, operational, and ethical challenges affecting the reliability and usability of RAG systems in practice.
Anomaly Detection in Smart Power Grids with Graph-Regularized MS-SVDD: a Multimodal Subspace Learning Approach
Feb 18, 2025



In this paper, we address an anomaly detection problem in smart power grids using Multimodal Subspace Support Vector Data Description (MS-SVDD). This approach aims to leverage better feature relations by considering the data as coming from different modalities. These data are projected into a shared lower-dimensionality subspace which aims to preserve their inner characteristics. To supplement the previous work on this subject, we introduce novel multimodal graph-embedded regularizers that leverage graph information for every modality to enhance the training process, and we consider an improved training equation that allows us to maximize or minimize each modality according to the specified criteria. We apply this regularized graph-embedded model on a 3-modalities dataset after having generalized MS-SVDD algorithms to any number of modalities. To set up our application, we propose a whole preprocessing procedure to extract One-Class Classification training instances from time-bounded event time series that are used to evaluate both the reliability and earliness of our model for Event Detection.
GPT versus Humans: Uncovering Ethical Concerns in Conversational Generative AI-empowered Multi-Robot Systems
Nov 21, 2024



The emergence of generative artificial intelligence (GAI) and large language models (LLMs) such ChatGPT has enabled the realization of long-harbored desires in software and robotic development. The technology however, has brought with it novel ethical challenges. These challenges are compounded by the application of LLMs in other machine learning systems, such as multi-robot systems. The objectives of the study were to examine novel ethical issues arising from the application of LLMs in multi-robot systems. Unfolding ethical issues in GPT agent behavior (deliberation of ethical concerns) was observed, and GPT output was compared with human experts. The article also advances a model for ethical development of multi-robot systems. A qualitative workshop-based method was employed in three workshops for the collection of ethical concerns: two human expert workshops (N=16 participants) and one GPT-agent-based workshop (N=7 agents; two teams of 6 agents plus one judge). Thematic analysis was used to analyze the qualitative data. The results reveal differences between the human-produced and GPT-based ethical concerns. Human experts placed greater emphasis on new themes related to deviance, data privacy, bias and unethical corporate conduct. GPT agents emphasized concerns present in existing AI ethics guidelines. The study contributes to a growing body of knowledge in context-specific AI ethics and GPT application. It demonstrates the gap between human expert thinking and LLM output, while emphasizing new ethical concerns emerging in novel technology.
Developing Retrieval Augmented Generation (RAG) based LLM Systems from PDFs: An Experience Report
Oct 21, 2024



This paper presents an experience report on the development of Retrieval Augmented Generation (RAG) systems using PDF documents as the primary data source. The RAG architecture combines generative capabilities of Large Language Models (LLMs) with the precision of information retrieval. This approach has the potential to redefine how we interact with and augment both structured and unstructured knowledge in generative models to enhance transparency, accuracy, and contextuality of responses. The paper details the end-to-end pipeline, from data collection, preprocessing, to retrieval indexing and response generation, highlighting technical challenges and practical solutions. We aim to offer insights to researchers and practitioners developing similar systems using two distinct approaches: OpenAI's Assistant API with GPT Series and Llama's open-source models. The practical implications of this research lie in enhancing the reliability of generative AI systems in various sectors where domain-specific knowledge and real-time information retrieval is important. The Python code used in this work is also available at: https://github.com/GPT-Laboratory/RAG-LLM-Development-Guidebook-from-PDFs.
LLM-based agents for automating the enhancement of user story quality: An early report
Mar 14, 2024In agile software development, maintaining high-quality user stories is crucial, but also challenging. This study explores the use of large language models to automatically improve the user story quality in Austrian Post Group IT agile teams. We developed a reference model for an Autonomous LLM-based Agent System and implemented it at the company. The quality of user stories in the study and the effectiveness of these agents for user story quality improvement was assessed by 11 participants across six agile teams. Our findings demonstrate the potential of LLMs in improving user story quality, contributing to the research on AI role in agile development, and providing a practical example of the transformative impact of AI in an industry setting.
Business and ethical concerns in domestic Conversational Generative AI-empowered multi-robot systems
Jan 12, 2024



Business and technology are intricately connected through logic and design. They are equally sensitive to societal changes and may be devastated by scandal. Cooperative multi-robot systems (MRSs) are on the rise, allowing robots of different types and brands to work together in diverse contexts. Generative artificial intelligence has been a dominant topic in recent artificial intelligence (AI) discussions due to its capacity to mimic humans through the use of natural language and the production of media, including deep fakes. In this article, we focus specifically on the conversational aspects of generative AI, and hence use the term Conversational Generative artificial intelligence (CGI). Like MRSs, CGIs have enormous potential for revolutionizing processes across sectors and transforming the way humans conduct business. From a business perspective, cooperative MRSs alone, with potential conflicts of interest, privacy practices, and safety concerns, require ethical examination. MRSs empowered by CGIs demand multi-dimensional and sophisticated methods to uncover imminent ethical pitfalls. This study focuses on ethics in CGI-empowered MRSs while reporting the stages of developing the MORUL model.
Quality of Data in Machine Learning
Dec 17, 2021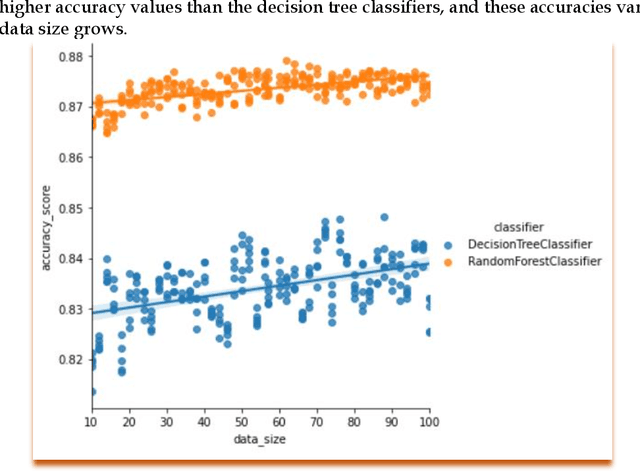



A common assumption exists according to which machine learning models improve their performance when they have more data to learn from. In this study, the authors wished to clarify the dilemma by performing an empirical experiment utilizing novel vocational student data. The experiment compared different machine learning algorithms while varying the number of data and feature combinations available for training and testing the models. The experiment revealed that the increase of data records or their sample frequency does not immediately lead to significant increases in the model accuracies or performance, however the variance of accuracies does diminish in the case of ensemble models. Similar phenomenon was witnessed while increasing the number of input features for the models. The study refutes the starting assumption and continues to state that in this case the significance in data lies in the quality of the data instead of the quantity of the data.