 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAxiomatizing Neural Networks via Pursuit of Subspaces
May 19, 2026While deep neural networks have achieved remarkable success across a wide range of domains, their underlying mechanisms remain poorly understood, and they are often regarded as black boxes. This gap between empirical performance and theoretical understanding poses a challenge analogous to the pre-axiomatic stage of classical geometry. In this work, we introduce the Pursuit of Subspaces (PoS) hypothesis, an axiomatic framework that formulates neural network behavior through a set of geometric postulates. These axioms, together with their derived consequences, provide a unified perspective on representation, computation, and generalization in both shallow and deep architectures. We show that this framework yields geometric explanations for fundamental questions in deep learning, including representation structure, architectural mechanisms, and generalization behavior, offering a principled step toward a coherent theoretical foundation.
The Eleventh NTIRE 2026 Efficient Super-Resolution Challenge Report
Apr 03, 2026This paper reviews the NTIRE 2026 challenge on efficient single-image super-resolution with a focus on the proposed solutions and results. The aim of this challenge is to devise a network that reduces one or several aspects, such as runtime, parameters, and FLOPs, while maintaining PSNR of around 26.90 dB on the DIV2K_LSDIR_valid dataset, and 26.99 dB on the DIV2K_LSDIR_test dataset. The challenge had 95 registered participants, and 15 teams made valid submissions. They gauge the state-of-the-art results for efficient single-image super-resolution.
MTS-CSNet: Multiscale Tensor Factorization for Deep Compressive Sensing on RGB Images
Feb 04, 2026Deep learning based compressive sensing (CS) methods typically learn sampling operators using convolutional or block wise fully connected layers, which limit receptive fields and scale poorly for high dimensional data. We propose MTSCSNet, a CS framework based on Multiscale Tensor Summation (MTS) factorization, a structured operator for efficient multidimensional signal processing. MTS performs mode-wise linear transformations with multiscale summation, enabling large receptive fields and effective modeling of cross-dimensional correlations. In MTSCSNet, MTS is first used as a learnable CS operator that performs linear dimensionality reduction in tensor space, with its adjoint defining the initial back-projection, and is then applied in the reconstruction stage to directly refine this estimate. This results in a simple feed-forward architecture without iterative or proximal optimization, while remaining parameter and computation efficient. Experiments on standard CS benchmarks show that MTSCSNet achieves state-of-the-art reconstruction performance on RGB images, with notable PSNR gains and faster inference, even compared to recent diffusion-based CS methods, while using a significantly more compact feed-forward architecture.
Multi-Scale Tensorial Summation and Dimensional Reduction Guided Neural Network for Edge Detection
Apr 22, 2025



Edge detection has attracted considerable attention thanks to its exceptional ability to enhance performance in downstream computer vision tasks. In recent years, various deep learning methods have been explored for edge detection tasks resulting in a significant performance improvement compared to conventional computer vision algorithms. In neural networks, edge detection tasks require considerably large receptive fields to provide satisfactory performance. In a typical convolutional operation, such a large receptive field can be achieved by utilizing a significant number of consecutive layers, which yields deep network structures. Recently, a Multi-scale Tensorial Summation (MTS) factorization operator was presented, which can achieve very large receptive fields even from the initial layers. In this paper, we propose a novel MTS Dimensional Reduction (MTS-DR) module guided neural network, MTS-DR-Net, for the edge detection task. The MTS-DR-Net uses MTS layers, and corresponding MTS-DR blocks as a new backbone to remove redundant information initially. Such a dimensional reduction module enables the neural network to focus specifically on relevant information (i.e., necessary subspaces). Finally, a weight U-shaped refinement module follows MTS-DR blocks in the MTS-DR-Net. We conducted extensive experiments on two benchmark edge detection datasets: BSDS500 and BIPEDv2 to verify the effectiveness of our model. The implementation of the proposed MTS-DR-Net can be found at https://github.com/LeiXuAI/MTS-DR-Net.git.
Text-Audio-Visual-conditioned Diffusion Model for Video Saliency Prediction
Apr 19, 2025

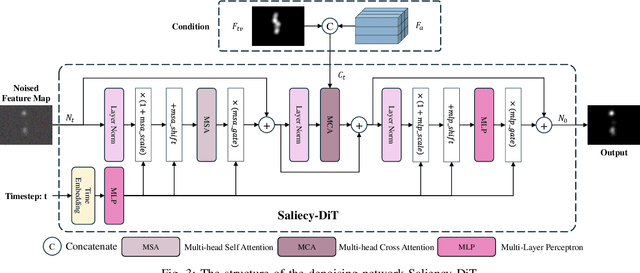

Video saliency prediction is crucial for downstream applications, such as video compression and human-computer interaction. With the flourishing of multimodal learning, researchers started to explore multimodal video saliency prediction, including audio-visual and text-visual approaches. Auditory cues guide the gaze of viewers to sound sources, while textual cues provide semantic guidance for understanding video content. Integrating these complementary cues can improve the accuracy of saliency prediction. Therefore, we attempt to simultaneously analyze visual, auditory, and textual modalities in this paper, and propose TAVDiff, a Text-Audio-Visual-conditioned Diffusion Model for video saliency prediction. TAVDiff treats video saliency prediction as an image generation task conditioned on textual, audio, and visual inputs, and predicts saliency maps through stepwise denoising. To effectively utilize text, a large multimodal model is used to generate textual descriptions for video frames and introduce a saliency-oriented image-text response (SITR) mechanism to generate image-text response maps. It is used as conditional information to guide the model to localize the visual regions that are semantically related to the textual description. Regarding the auditory modality, it is used as another conditional information for directing the model to focus on salient regions indicated by sounds. At the same time, since the diffusion transformer (DiT) directly concatenates the conditional information with the timestep, which may affect the estimation of the noise level. To achieve effective conditional guidance, we propose Saliency-DiT, which decouples the conditional information from the timestep. Experimental results show that TAVDiff outperforms existing methods, improving 1.03\%, 2.35\%, 2.71\% and 0.33\% on SIM, CC, NSS and AUC-J metrics, respectively.
Multiscale Tensor Summation Factorization as a New Neural Network Layer (MTS Layer) for Multidimensional Data Processing
Apr 17, 2025Multilayer perceptrons (MLP), or fully connected artificial neural networks, are known for performing vector-matrix multiplications using learnable weight matrices; however, their practical application in many machine learning tasks, especially in computer vision, can be limited due to the high dimensionality of input-output pairs at each layer. To improve efficiency, convolutional operators have been utilized to facilitate weight sharing and local connections, yet they are constrained by limited receptive fields. In this paper, we introduce Multiscale Tensor Summation (MTS) Factorization, a novel neural network operator that implements tensor summation at multiple scales, where each tensor to be summed is obtained through Tucker-decomposition-like mode products. Unlike other tensor decomposition methods in the literature, MTS is not introduced as a network compression tool; instead, as a new backbone neural layer. MTS not only reduces the number of parameters required while enhancing the efficiency of weight optimization compared to traditional dense layers (i.e., unfactorized weight matrices in MLP layers), but it also demonstrates clear advantages over convolutional layers. The proof-of-concept experimental comparison of the proposed MTS networks with MLPs and Convolutional Neural Networks (CNNs) demonstrates their effectiveness across various tasks, such as classification, compression, and signal restoration. Additionally, when integrated with modern non-linear units such as the multi-head gate (MHG), also introduced in this study, the corresponding neural network, MTSNet, demonstrates a more favorable complexity-performance tradeoff compared to state-of-the-art transformers in various computer vision applications. The software implementation of the MTS layer and the corresponding MTS-based networks, MTSNets, is shared at https://github.com/mehmetyamac/MTSNet.
DVLTA-VQA: Decoupled Vision-Language Modeling with Text-Guided Adaptation for Blind Video Quality Assessment
Apr 16, 2025



Inspired by the dual-stream theory of the human visual system (HVS) - where the ventral stream is responsible for object recognition and detail analysis, while the dorsal stream focuses on spatial relationships and motion perception - an increasing number of video quality assessment (VQA) works built upon this framework are proposed. Recent advancements in large multi-modal models, notably Contrastive Language-Image Pretraining (CLIP), have motivated researchers to incorporate CLIP into dual-stream-based VQA methods. This integration aims to harness the model's superior semantic understanding capabilities to replicate the object recognition and detail analysis in ventral stream, as well as spatial relationship analysis in dorsal stream. However, CLIP is originally designed for images and lacks the ability to capture temporal and motion information inherent in videos. %Furthermore, existing feature fusion strategies in no-reference video quality assessment (NR-VQA) often rely on fixed weighting schemes, which fail to adaptively adjust feature importance. To address the limitation, this paper propose a Decoupled Vision-Language Modeling with Text-Guided Adaptation for Blind Video Quality Assessment (DVLTA-VQA), which decouples CLIP's visual and textual components, and integrates them into different stages of the NR-VQA pipeline.
Progressive Transfer Learning for Multi-Pass Fundus Image Restoration
Apr 14, 2025


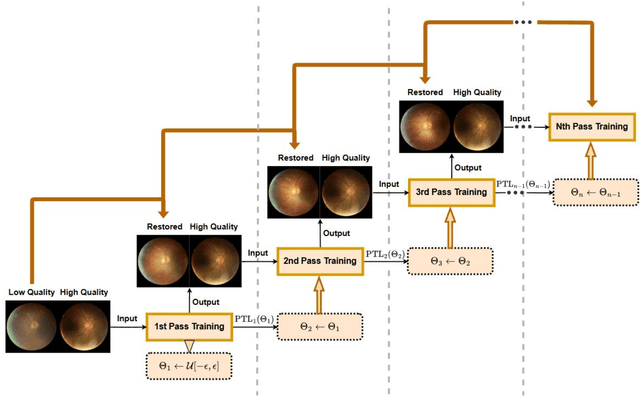
Diabetic retinopathy is a leading cause of vision impairment, making its early diagnosis through fundus imaging critical for effective treatment planning. However, the presence of poor quality fundus images caused by factors such as inadequate illumination, noise, blurring and other motion artifacts yields a significant challenge for accurate DR screening. In this study, we propose progressive transfer learning for multi pass restoration to iteratively enhance the quality of degraded fundus images, ensuring more reliable DR screening. Unlike previous methods that often focus on a single pass restoration, multi pass restoration via PTL can achieve a superior blind restoration performance that can even improve most of the good quality fundus images in the dataset. Initially, a Cycle GAN model is trained to restore low quality images, followed by PTL induced restoration passes over the latest restored outputs to improve overall quality in each pass. The proposed method can learn blind restoration without requiring any paired data while surpassing its limitations by leveraging progressive learning and fine tuning strategies to minimize distortions and preserve critical retinal features. To evaluate PTL's effectiveness on multi pass restoration, we conducted experiments on DeepDRiD, a large scale fundus imaging dataset specifically curated for diabetic retinopathy detection. Our result demonstrates state of the art performance, showcasing PTL's potential as a superior approach to iterative image quality restoration.
FANeRV: Frequency Separation and Augmentation based Neural Representation for Video
Apr 09, 2025Neural representations for video (NeRV) have gained considerable attention for their strong performance across various video tasks. However, existing NeRV methods often struggle to capture fine spatial details, resulting in vague reconstructions. In this paper, we present a Frequency Separation and Augmentation based Neural Representation for video (FANeRV), which addresses these limitations with its core Wavelet Frequency Upgrade Block.This block explicitly separates input frames into high and low-frequency components using discrete wavelet transform, followed by targeted enhancement using specialized modules. Finally, a specially designed gated network effectively fuses these frequency components for optimal reconstruction. Additionally, convolutional residual enhancement blocks are integrated into the later stages of the network to balance parameter distribution and improve the restoration of high-frequency details. Experimental results demonstrate that FANeRV significantly improves reconstruction performance and excels in multiple tasks, including video compression, inpainting, and interpolation, outperforming existing NeRV methods.
Semi-Supervised Co-Training of Time and Time-Frequency Models: Application to Bearing Fault Diagnosis
Mar 14, 2025



Neural networks require massive amounts of annotated data to train intelligent solutions. Acquiring many labeled data in industrial applications is often difficult; therefore, semi-supervised approaches are preferred. We propose a new semi-supervised co-training method, which combines time and time-frequency (TF) machine learning models to improve performance and reliability. The developed framework collaboratively co-trains fast time-domain models by utilizing high-performing TF techniques without increasing the inference complexity. Besides, it operates in cloud-edge networks and offers holistic support for many applications covering edge-real-time monitoring and cloud-based updates and corrections. Experimental results on bearing fault diagnosis verify the superiority of our technique compared to a competing self-training method. The results from two case studies show that our method outperforms self-training for different noise levels and amounts of available data with accuracy gains reaching from 10.6% to 33.9%. They demonstrate that fusing time-domain and TF-based models offers opportunities for developing high-performance industrial solutions.