 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient3D: A Unified Framework for Adaptive and Debiased Token Reduction in 3D MLLMs
Apr 03, 2026Recent advances in Multimodal Large Language Models (MLLMs) have expanded reasoning capabilities into 3D domains, enabling fine-grained spatial understanding. However, the substantial size of 3D MLLMs and the high dimensionality of input features introduce considerable inference overhead, which limits practical deployment on resource constrained platforms. To overcome this limitation, this paper presents Efficient3D, a unified framework for visual token pruning that accelerates 3D MLLMs while maintaining competitive accuracy. The proposed framework introduces a Debiased Visual Token Importance Estimator (DVTIE) module, which considers the influence of shallow initial layers during attention aggregation, thereby producing more reliable importance predictions for visual tokens. In addition, an Adaptive Token Rebalancing (ATR) strategy is developed to dynamically adjust pruning strength based on scene complexity, preserving semantic completeness and maintaining balanced attention across layers. Together, they enable context-aware token reduction that maintains essential semantics with lower computation. Comprehensive experiments conducted on five representative 3D vision and language benchmarks, including ScanRefer, Multi3DRefer, Scan2Cap, ScanQA, and SQA3D, demonstrate that Efficient3D achieves superior performance compared with unpruned baselines, with a +2.57% CIDEr improvement on the Scan2Cap dataset. Therefore, Efficient3D provides a scalable and effective solution for efficient inference in 3D MLLMs. The code is released at: https://github.com/sol924/Efficient3D
TALENT: Target-aware Efficient Tuning for Referring Image Segmentation
Apr 01, 2026Referring image segmentation aims to segment specific targets based on a natural text expression. Recently, parameter-efficient tuning (PET) has emerged as a promising paradigm. However, existing PET-based methods often suffer from the fact that visual features can't emphasize the text-referred target instance but activate co-category yet unrelated objects. We analyze and quantify this problem, terming it the `non-target activation' (NTA) issue. To address this, we propose a novel framework, TALENT, which utilizes target-aware efficient tuning for PET-based RIS. Specifically, we first propose a Rectified Cost Aggregator (RCA) to efficiently aggregate text-referred features. Then, to calibrate `NTA' into accurate target activation, we adopt a Target-aware Learning Mechanism (TLM), including contextual pairwise consistency learning and target-centric contrastive learning. The former uses the sentence-level text feature to achieve a holistic understanding of the referent and constructs a text-referred affinity map to optimize the semantic association of visual features. The latter further enhances target localization to discover the distinct instance while suppressing associations with other unrelated ones. The two objectives work in concert and address `NTA' effectively. Extensive evaluations show that TALENT outperforms existing methods across various metrics (e.g., 2.5\% mIoU gains on G-Ref val set). Our codes will be released at: https://github.com/Kimsure/TALENT.
TF-SSD: A Strong Pipeline via Synergic Mask Filter for Training-free Co-salient Object Detection
Apr 01, 2026Co-salient Object Detection (CoSOD) aims to segment salient objects that consistently appear across a group of related images. Despite the notable progress achieved by recent training-based approaches, they still remain constrained by the closed-set datasets and exhibit limited generalization. However, few studies explore the potential of Vision Foundation Models (VFMs) to address CoSOD, which demonstrate a strong generalized ability and robust saliency understanding. In this paper, we investigate and leverage VFMs for CoSOD, and further propose a novel training-free method, TF-SSD, through the synergy between SAM and DINO. Specifically, we first utilize SAM to generate comprehensive raw proposals, which serve as a candidate mask pool. Then, we introduce a quality mask generator to filter out redundant masks, thereby acquiring a refined mask set. Since this generator is built upon SAM, it inherently lacks semantic understanding of saliency. To this end, we adopt an intra-image saliency filter that employs DINO's attention maps to identify visually salient masks within individual images. Moreover, to extend saliency understanding across group images, we propose an inter-image prototype selector, which computes similarity scores among cross-image prototypes to select masks with the highest score. These selected masks serve as final predictions for CoSOD. Extensive experiments show that our TF-SSD outperforms existing methods (e.g., 13.7\% gains over the recent training-free method). Codes are available at https://github.com/hzz-yy/TF-SSD.
SynthSeg-Agents: Multi-Agent Synthetic Data Generation for Zero-Shot Weakly Supervised Semantic Segmentation
Dec 17, 2025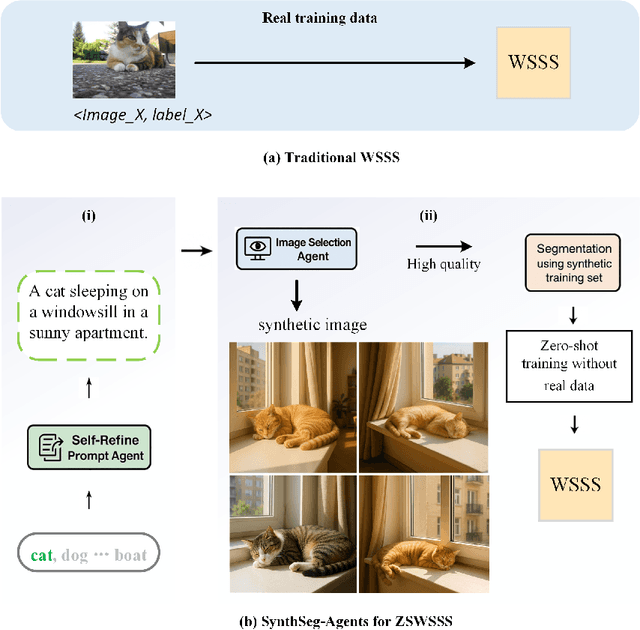
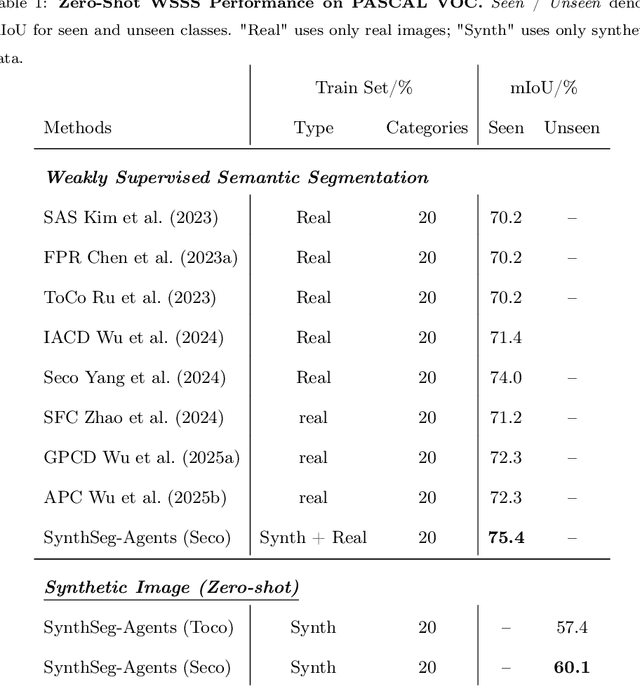
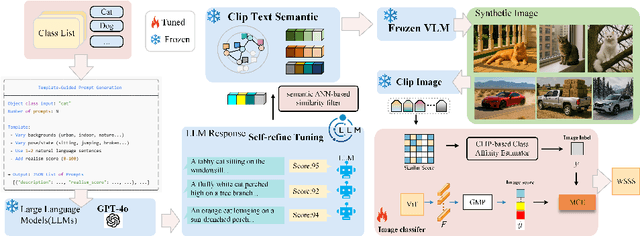
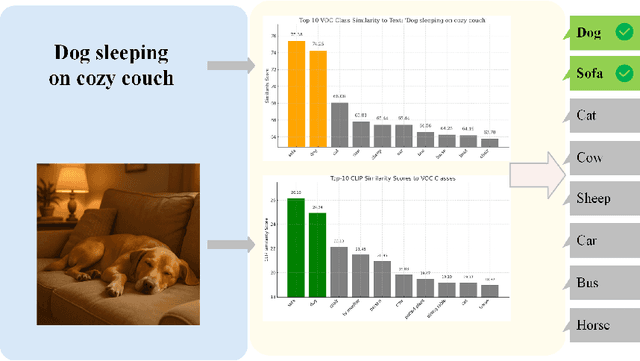
Weakly Supervised Semantic Segmentation (WSSS) with image level labels aims to produce pixel level predictions without requiring dense annotations. While recent approaches have leveraged generative models to augment existing data, they remain dependent on real world training samples. In this paper, we introduce a novel direction, Zero Shot Weakly Supervised Semantic Segmentation (ZSWSSS), and propose SynthSeg Agents, a multi agent framework driven by Large Language Models (LLMs) to generate synthetic training data entirely without real images. SynthSeg Agents comprises two key modules, a Self Refine Prompt Agent and an Image Generation Agent. The Self Refine Prompt Agent autonomously crafts diverse and semantically rich image prompts via iterative refinement, memory mechanisms, and prompt space exploration, guided by CLIP based similarity and nearest neighbor diversity filtering. These prompts are then passed to the Image Generation Agent, which leverages Vision Language Models (VLMs) to synthesize candidate images. A frozen CLIP scoring model is employed to select high quality samples, and a ViT based classifier is further trained to relabel the entire synthetic dataset with improved semantic precision. Our framework produces high quality training data without any real image supervision. Experiments on PASCAL VOC 2012 and COCO 2014 show that SynthSeg Agents achieves competitive performance without using real training images. This highlights the potential of LLM driven agents in enabling cost efficient and scalable semantic segmentation.
Normal-Abnormal Guided Generalist Anomaly Detection
Oct 02, 2025Generalist Anomaly Detection (GAD) aims to train a unified model on an original domain that can detect anomalies in new target domains. Previous GAD methods primarily use only normal samples as references, overlooking the valuable information contained in anomalous samples that are often available in real-world scenarios. To address this limitation, we propose a more practical approach: normal-abnormal-guided generalist anomaly detection, which leverages both normal and anomalous samples as references to guide anomaly detection across diverse domains. We introduce the Normal-Abnormal Generalist Learning (NAGL) framework, consisting of two key components: Residual Mining (RM) and Anomaly Feature Learning (AFL). RM extracts abnormal patterns from normal-abnormal reference residuals to establish transferable anomaly representations, while AFL adaptively learns anomaly features in query images through residual mapping to identify instance-aware anomalies. Our approach effectively utilizes both normal and anomalous references for more accurate and efficient cross-domain anomaly detection. Extensive experiments across multiple benchmarks demonstrate that our method significantly outperforms existing GAD approaches. This work represents the first to adopt a mixture of normal and abnormal samples as references in generalist anomaly detection. The code and datasets are available at https://github.com/JasonKyng/NAGL.
Contrastive Prompt Clustering for Weakly Supervised Semantic Segmentation
Aug 23, 2025



Weakly Supervised Semantic Segmentation (WSSS) with image-level labels has gained attention for its cost-effectiveness. Most existing methods emphasize inter-class separation, often neglecting the shared semantics among related categories and lacking fine-grained discrimination. To address this, we propose Contrastive Prompt Clustering (CPC), a novel WSSS framework. CPC exploits Large Language Models (LLMs) to derive category clusters that encode intrinsic inter-class relationships, and further introduces a class-aware patch-level contrastive loss to enforce intra-class consistency and inter-class separation. This hierarchical design leverages clusters as coarse-grained semantic priors while preserving fine-grained boundaries, thereby reducing confusion among visually similar categories. Experiments on PASCAL VOC 2012 and MS COCO 2014 demonstrate that CPC surpasses existing state-of-the-art methods in WSSS.
Hierarchical Attention Fusion of Visual and Textual Representations for Cross-Domain Sequential Recommendation
Apr 21, 2025Cross-Domain Sequential Recommendation (CDSR) predicts user behavior by leveraging historical interactions across multiple domains, focusing on modeling cross-domain preferences through intra- and inter-sequence item relationships. Inspired by human cognitive processes, we propose Hierarchical Attention Fusion of Visual and Textual Representations (HAF-VT), a novel approach integrating visual and textual data to enhance cognitive modeling. Using the frozen CLIP model, we generate image and text embeddings, enriching item representations with multimodal data. A hierarchical attention mechanism jointly learns single-domain and cross-domain preferences, mimicking human information integration. Evaluated on four e-commerce datasets, HAF-VT outperforms existing methods in capturing cross-domain user interests, bridging cognitive principles with computational models and highlighting the role of multimodal data in sequential decision-making.
FANeRV: Frequency Separation and Augmentation based Neural Representation for Video
Apr 09, 2025Neural representations for video (NeRV) have gained considerable attention for their strong performance across various video tasks. However, existing NeRV methods often struggle to capture fine spatial details, resulting in vague reconstructions. In this paper, we present a Frequency Separation and Augmentation based Neural Representation for video (FANeRV), which addresses these limitations with its core Wavelet Frequency Upgrade Block.This block explicitly separates input frames into high and low-frequency components using discrete wavelet transform, followed by targeted enhancement using specialized modules. Finally, a specially designed gated network effectively fuses these frequency components for optimal reconstruction. Additionally, convolutional residual enhancement blocks are integrated into the later stages of the network to balance parameter distribution and improve the restoration of high-frequency details. Experimental results demonstrate that FANeRV significantly improves reconstruction performance and excels in multiple tasks, including video compression, inpainting, and interpolation, outperforming existing NeRV methods.
CNC: Cross-modal Normality Constraint for Unsupervised Multi-class Anomaly Detection
Dec 31, 2024



Existing unsupervised distillation-based methods rely on the differences between encoded and decoded features to locate abnormal regions in test images. However, the decoder trained only on normal samples still reconstructs abnormal patch features well, degrading performance. This issue is particularly pronounced in unsupervised multi-class anomaly detection tasks. We attribute this behavior to over-generalization(OG) of decoder: the significantly increasing diversity of patch patterns in multi-class training enhances the model generalization on normal patches, but also inadvertently broadens its generalization to abnormal patches. To mitigate OG, we propose a novel approach that leverages class-agnostic learnable prompts to capture common textual normality across various visual patterns, and then apply them to guide the decoded features towards a normal textual representation, suppressing over-generalization of the decoder on abnormal patterns. To further improve performance, we also introduce a gated mixture-of-experts module to specialize in handling diverse patch patterns and reduce mutual interference between them in multi-class training. Our method achieves competitive performance on the MVTec AD and VisA datasets, demonstrating its effectiveness.
Image Augmentation Agent for Weakly Supervised Semantic Segmentation
Dec 29, 2024Weakly-supervised semantic segmentation (WSSS) has achieved remarkable progress using only image-level labels. However, most existing WSSS methods focus on designing new network structures and loss functions to generate more accurate dense labels, overlooking the limitations imposed by fixed datasets, which can constrain performance improvements. We argue that more diverse trainable images provides WSSS richer information and help model understand more comprehensive semantic pattern. Therefore in this paper, we introduce a novel approach called Image Augmentation Agent (IAA) which shows that it is possible to enhance WSSS from data generation perspective. IAA mainly design an augmentation agent that leverages large language models (LLMs) and diffusion models to automatically generate additional images for WSSS. In practice, to address the instability in prompt generation by LLMs, we develop a prompt self-refinement mechanism. It allow LLMs to re-evaluate the rationality of generated prompts to produce more coherent prompts. Additionally, we insert an online filter into diffusion generation process to dynamically ensure the quality and balance of generated images. Experimental results show that our method significantly surpasses state-of-the-art WSSS approaches on the PASCAL VOC 2012 and MS COCO 2014 datasets.