 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSDEnhancer: Taming Real-World Space-Time Video Super-Resolution with One-Step Diffusion
Jan 28, 2026Diffusion models (DMs) have demonstrated exceptional success in video super-resolution (VSR), showcasing a powerful capacity for generating fine-grained details. However, their potential for space-time video super-resolution (STVSR), which necessitates not only recovering realistic visual content from low-resolution to high-resolution but also improving the frame rate with coherent temporal dynamics, remains largely underexplored. Moreover, existing STVSR methods predominantly address spatiotemporal upsampling under simplified degradation assumptions, which often struggle in real-world scenarios with complex unknown degradations. Such a high demand for reconstruction fidelity and temporal consistency makes the development of a robust STVSR framework particularly non-trivial. To address these challenges, we propose OSDEnhancer, a novel framework that, to the best of our knowledge, represents the first method to achieve real-world STVSR through an efficient one-step diffusion process. OSDEnhancer initializes essential spatiotemporal structures through a linear pre-interpolation strategy and pivots on training temporal refinement and spatial enhancement mixture of experts (TR-SE MoE), which allows distinct expert pathways to progressively learn robust, specialized representations for temporal coherence and spatial detail, further collaboratively reinforcing each other during inference. A bidirectional deformable variational autoencoder (VAE) decoder is further introduced to perform recurrent spatiotemporal aggregation and propagation, enhancing cross-frame reconstruction fidelity. Experiments demonstrate that the proposed method achieves state-of-the-art performance while maintaining superior generalization capability in real-world scenarios.
Neural B-frame Video Compression with Bi-directional Reference Harmonization
Nov 12, 2025Neural video compression (NVC) has made significant progress in recent years, while neural B-frame video compression (NBVC) remains underexplored compared to P-frame compression. NBVC can adopt bi-directional reference frames for better compression performance. However, NBVC's hierarchical coding may complicate continuous temporal prediction, especially at some hierarchical levels with a large frame span, which could cause the contribution of the two reference frames to be unbalanced. To optimize reference information utilization, we propose a novel NBVC method, termed Bi-directional Reference Harmonization Video Compression (BRHVC), with the proposed Bi-directional Motion Converge (BMC) and Bi-directional Contextual Fusion (BCF). BMC converges multiple optical flows in motion compression, leading to more accurate motion compensation on a larger scale. Then BCF explicitly models the weights of reference contexts under the guidance of motion compensation accuracy. With more efficient motions and contexts, BRHVC can effectively harmonize bi-directional references. Experimental results indicate that our BRHVC outperforms previous state-of-the-art NVC methods, even surpassing the traditional coding, VTM-RA (under random access configuration), on the HEVC datasets. The source code is released at https://github.com/kwai/NVC.
EvEnhancer: Empowering Effectiveness, Efficiency and Generalizability for Continuous Space-Time Video Super-Resolution with Events
May 07, 2025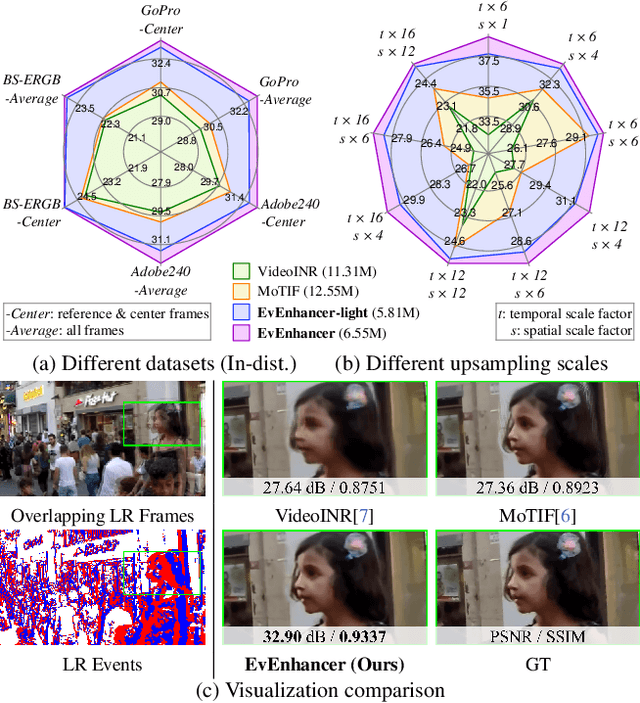
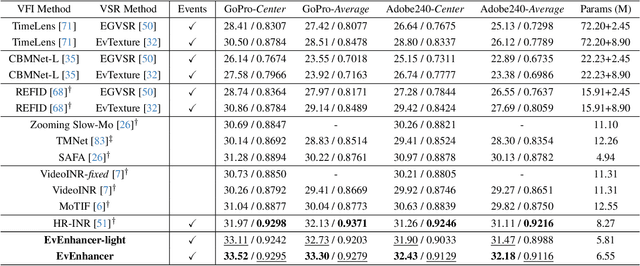
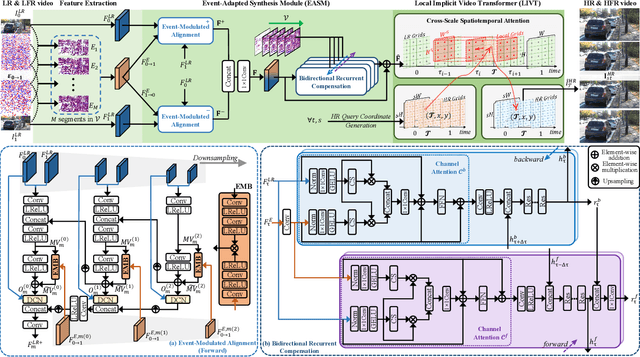
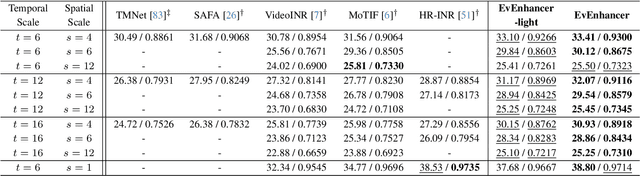
Continuous space-time video super-resolution (C-STVSR) endeavors to upscale videos simultaneously at arbitrary spatial and temporal scales, which has recently garnered increasing interest. However, prevailing methods struggle to yield satisfactory videos at out-of-distribution spatial and temporal scales. On the other hand, event streams characterized by high temporal resolution and high dynamic range, exhibit compelling promise in vision tasks. This paper presents EvEnhancer, an innovative approach that marries the unique advantages of event streams to elevate effectiveness, efficiency, and generalizability for C-STVSR. Our approach hinges on two pivotal components: 1) Event-adapted synthesis capitalizes on the spatiotemporal correlations between frames and events to discern and learn long-term motion trajectories, enabling the adaptive interpolation and fusion of informative spatiotemporal features; 2) Local implicit video transformer integrates local implicit video neural function with cross-scale spatiotemporal attention to learn continuous video representations utilized to generate plausible videos at arbitrary resolutions and frame rates. Experiments show that EvEnhancer achieves superiority on synthetic and real-world datasets and preferable generalizability on out-of-distribution scales against state-of-the-art methods. Code is available at https://github.com/W-Shuoyan/EvEnhancer.
TransVFC: A Transformable Video Feature Compression Framework for Machines
Mar 31, 2025Nowadays, more and more video transmissions primarily aim at downstream machine vision tasks rather than humans. While widely deployed Human Visual System (HVS) oriented video coding standards like H.265/HEVC and H.264/AVC are efficient, they are not the optimal approaches for Video Coding for Machines (VCM) scenarios, leading to unnecessary bitrate expenditure. The academic and technical exploration within the VCM domain has led to the development of several strategies, and yet, conspicuous limitations remain in their adaptability for multi-task scenarios. To address the challenge, we propose a Transformable Video Feature Compression (TransVFC) framework. It offers a compress-then-transfer solution and includes a video feature codec and Feature Space Transform (FST) modules. In particular, the temporal redundancy of video features is squeezed by the codec through the scheme-based inter-prediction module. Then, the codec implements perception-guided conditional coding to minimize spatial redundancy and help the reconstructed features align with downstream machine perception.After that, the reconstructed features are transferred to new feature spaces for diverse downstream tasks by FST modules. To accommodate a new downstream task, it only requires training one lightweight FST module, avoiding retraining and redeploying the upstream codec and downstream task networks. Experiments show that TransVFC achieves high rate-task performance for diverse tasks of different granularities. We expect our work can provide valuable insights for video feature compression in multi-task scenarios. The codes are at https://github.com/Ws-Syx/TransVFC.
Prompt to Restore, Restore to Prompt: Cyclic Prompting for Universal Adverse Weather Removal
Mar 12, 2025
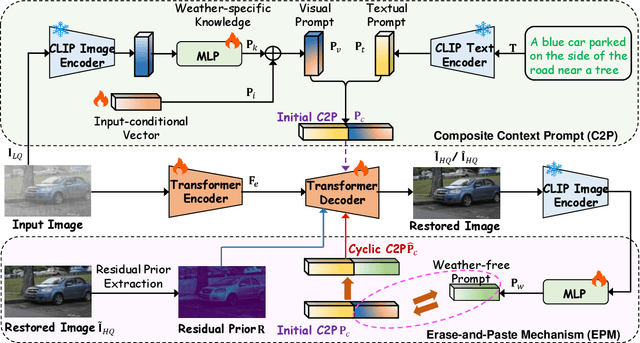
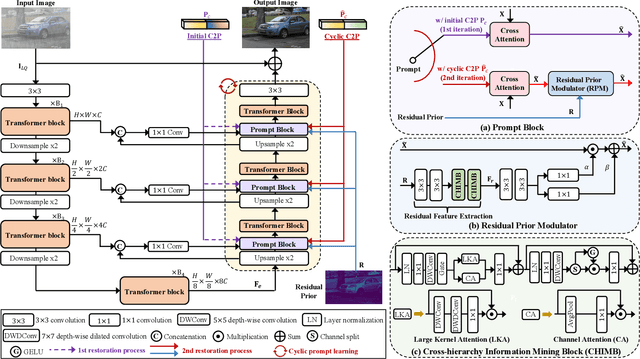

Universal adverse weather removal (UAWR) seeks to address various weather degradations within a unified framework. Recent methods are inspired by prompt learning using pre-trained vision-language models (e.g., CLIP), leveraging degradation-aware prompts to facilitate weather-free image restoration, yielding significant improvements. In this work, we propose CyclicPrompt, an innovative cyclic prompt approach designed to enhance the effectiveness, adaptability, and generalizability of UAWR. CyclicPrompt Comprises two key components: 1) a composite context prompt that integrates weather-related information and context-aware representations into the network to guide restoration. This prompt differs from previous methods by marrying learnable input-conditional vectors with weather-specific knowledge, thereby improving adaptability across various degradations. 2) The erase-and-paste mechanism, after the initial guided restoration, substitutes weather-specific knowledge with constrained restoration priors, inducing high-quality weather-free concepts into the composite prompt to further fine-tune the restoration process. Therefore, we can form a cyclic "Prompt-Restore-Prompt" pipeline that adeptly harnesses weather-specific knowledge, textual contexts, and reliable textures. Extensive experiments on synthetic and real-world datasets validate the superior performance of CyclicPrompt. The code is available at: https://github.com/RongxinL/CyclicPrompt.
CNC: Cross-modal Normality Constraint for Unsupervised Multi-class Anomaly Detection
Dec 31, 2024



Existing unsupervised distillation-based methods rely on the differences between encoded and decoded features to locate abnormal regions in test images. However, the decoder trained only on normal samples still reconstructs abnormal patch features well, degrading performance. This issue is particularly pronounced in unsupervised multi-class anomaly detection tasks. We attribute this behavior to over-generalization(OG) of decoder: the significantly increasing diversity of patch patterns in multi-class training enhances the model generalization on normal patches, but also inadvertently broadens its generalization to abnormal patches. To mitigate OG, we propose a novel approach that leverages class-agnostic learnable prompts to capture common textual normality across various visual patterns, and then apply them to guide the decoded features towards a normal textual representation, suppressing over-generalization of the decoder on abnormal patterns. To further improve performance, we also introduce a gated mixture-of-experts module to specialize in handling diverse patch patterns and reduce mutual interference between them in multi-class training. Our method achieves competitive performance on the MVTec AD and VisA datasets, demonstrating its effectiveness.
PSVMA+: Exploring Multi-granularity Semantic-visual Adaption for Generalized Zero-shot Learning
Oct 15, 2024



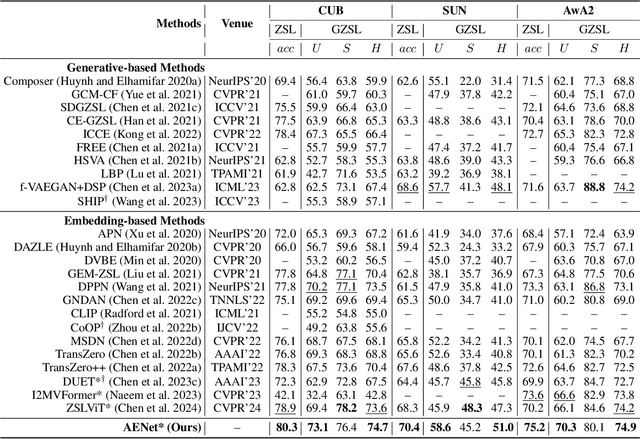
Generalized zero-shot learning (GZSL) endeavors to identify the unseen categories using knowledge from the seen domain, necessitating the intrinsic interactions between the visual features and attribute semantic features. However, GZSL suffers from insufficient visual-semantic correspondences due to the attribute diversity and instance diversity. Attribute diversity refers to varying semantic granularity in attribute descriptions, ranging from low-level (specific, directly observable) to high-level (abstract, highly generic) characteristics. This diversity challenges the collection of adequate visual cues for attributes under a uni-granularity. Additionally, diverse visual instances corresponding to the same sharing attributes introduce semantic ambiguity, leading to vague visual patterns. To tackle these problems, we propose a multi-granularity progressive semantic-visual mutual adaption (PSVMA+) network, where sufficient visual elements across granularity levels can be gathered to remedy the granularity inconsistency. PSVMA+ explores semantic-visual interactions at different granularity levels, enabling awareness of multi-granularity in both visual and semantic elements. At each granularity level, the dual semantic-visual transformer module (DSVTM) recasts the sharing attributes into instance-centric attributes and aggregates the semantic-related visual regions, thereby learning unambiguous visual features to accommodate various instances. Given the diverse contributions of different granularities, PSVMA+ employs selective cross-granularity learning to leverage knowledge from reliable granularities and adaptively fuses multi-granularity features for comprehensive representations. Experimental results demonstrate that PSVMA+ consistently outperforms state-of-the-art methods.
Instructing Prompt-to-Prompt Generation for Zero-Shot Learning
Jun 05, 2024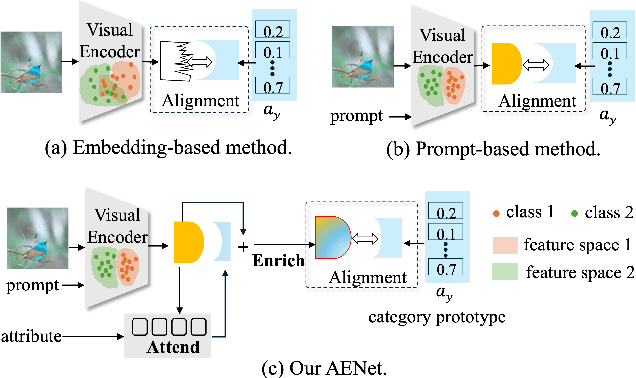
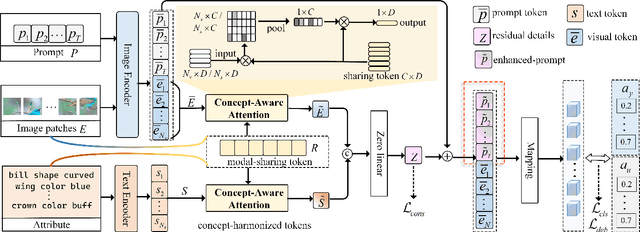

Zero-shot learning (ZSL) aims to explore the semantic-visual interactions to discover comprehensive knowledge transferred from seen categories to classify unseen categories. Recently, prompt engineering has emerged in ZSL, demonstrating impressive potential as it enables the zero-shot transfer of diverse visual concepts to downstream tasks. However, these methods are still not well generalized to broad unseen domains. A key reason is that the fixed adaption of learnable prompts on seen domains makes it tend to over-emphasize the primary visual features observed during training. In this work, we propose a \textbf{P}rompt-to-\textbf{P}rompt generation methodology (\textbf{P2P}), which addresses this issue by further embracing the instruction-following technique to distill instructive visual prompts for comprehensive transferable knowledge discovery. The core of P2P is to mine semantic-related instruction from prompt-conditioned visual features and text instruction on modal-sharing semantic concepts and then inversely rectify the visual representations with the guidance of the learned instruction prompts. This enforces the compensation for missing visual details to primary contexts and further eliminates the cross-modal disparity, endowing unseen domain generalization. Through extensive experimental results, we demonstrate the efficacy of P2P in achieving superior performance over state-of-the-art methods.
Once-for-All: Controllable Generative Image Compression with Dynamic Granularity Adaption
Jun 02, 2024



Although recent generative image compression methods have demonstrated impressive potential in optimizing the rate-distortion-perception trade-off, they still face the critical challenge of flexible rate adaption to diverse compression necessities and scenarios. To overcome this challenge, this paper proposes a Controllable Generative Image Compression framework, Control-GIC, the first capable of fine-grained bitrate adaption across a broad spectrum while ensuring high-fidelity and generality compression. We base Control-GIC on a VQGAN framework representing an image as a sequence of variable-length codes (i.e. VQ-indices), which can be losslessly compressed and exhibits a direct positive correlation with the bitrates. Therefore, drawing inspiration from the classical coding principle, we naturally correlate the information density of local image patches with their granular representations, to achieve dynamic adjustment of the code quantity following different granularity decisions. This implies we can flexibly determine a proper allocation of granularity for the patches to acquire desirable compression rates. We further develop a probabilistic conditional decoder that can trace back to historic encoded multi-granularity representations according to transmitted codes, and then reconstruct hierarchical granular features in the formalization of conditional probability, enabling more informative aggregation to improve reconstruction realism. Our experiments show that Control-GIC allows highly flexible and controllable bitrate adaption and even once compression on an entire dataset to fulfill constrained bitrate conditions. Experimental results demonstrate its superior performance over recent state-of-the-art methods.
BlindDiff: Empowering Degradation Modelling in Diffusion Models for Blind Image Super-Resolution
Mar 15, 2024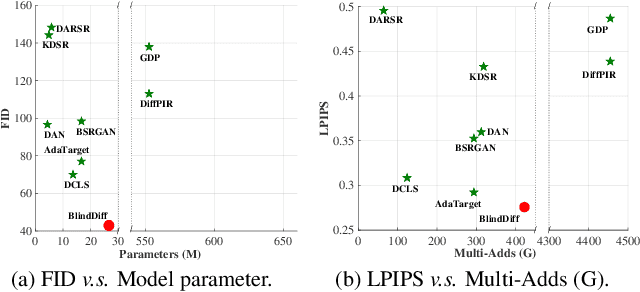

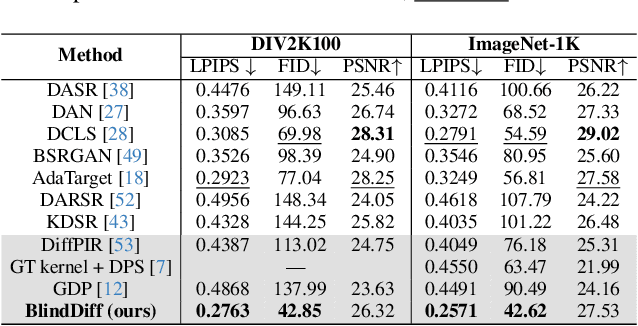
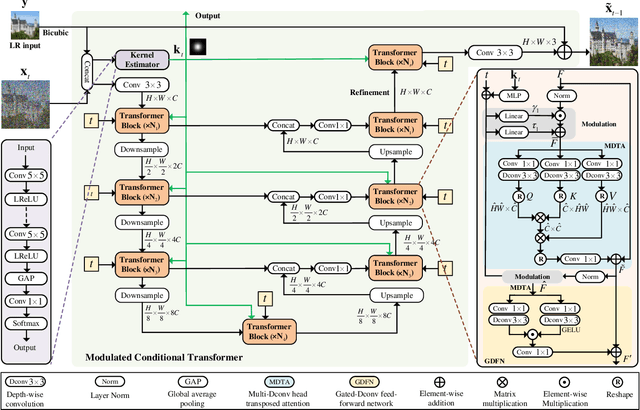
Diffusion models (DM) have achieved remarkable promise in image super-resolution (SR). However, most of them are tailored to solving non-blind inverse problems with fixed known degradation settings, limiting their adaptability to real-world applications that involve complex unknown degradations. In this work, we propose BlindDiff, a DM-based blind SR method to tackle the blind degradation settings in SISR. BlindDiff seamlessly integrates the MAP-based optimization into DMs, which constructs a joint distribution of the low-resolution (LR) observation, high-resolution (HR) data, and degradation kernels for the data and kernel priors, and solves the blind SR problem by unfolding MAP approach along with the reverse process. Unlike most DMs, BlindDiff firstly presents a modulated conditional transformer (MCFormer) that is pre-trained with noise and kernel constraints, further serving as a posterior sampler to provide both priors simultaneously. Then, we plug a simple yet effective kernel-aware gradient term between adjacent sampling iterations that guides the diffusion model to learn degradation consistency knowledge. This also enables to joint refine the degradation model as well as HR images by observing the previous denoised sample. With the MAP-based reverse diffusion process, we show that BlindDiff advocates alternate optimization for blur kernel estimation and HR image restoration in a mutual reinforcing manner. Experiments on both synthetic and real-world datasets show that BlindDiff achieves the state-of-the-art performance with significant model complexity reduction compared to recent DM-based methods. Code will be available at \url{https://github.com/lifengcs/BlindDiff}