 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructing Prompt-to-Prompt Generation for Zero-Shot Learning
Paper and Code
Jun 05, 2024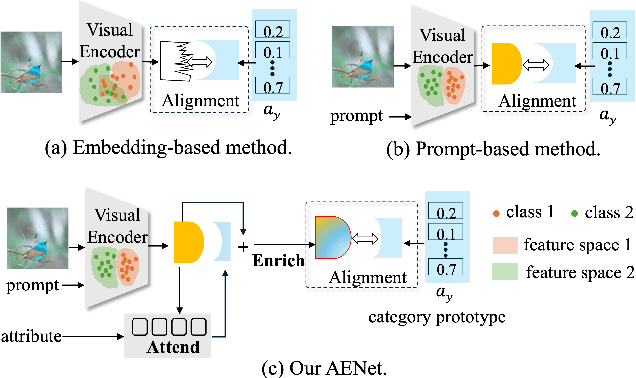
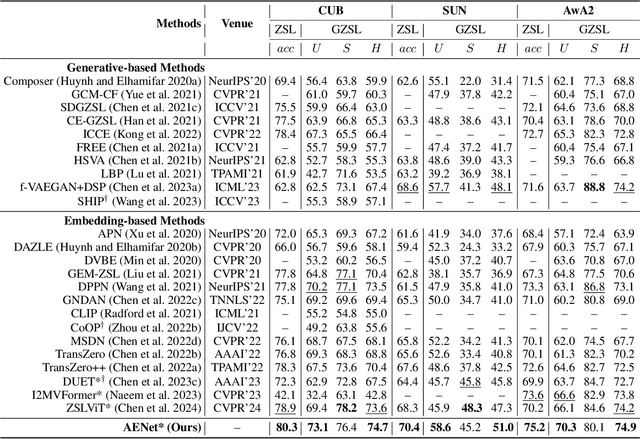
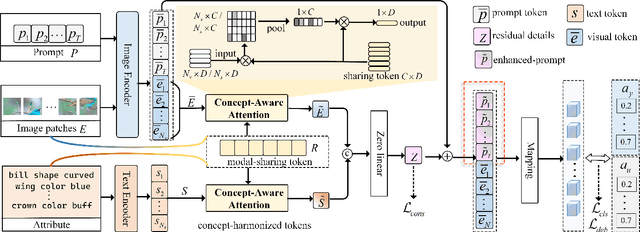

Zero-shot learning (ZSL) aims to explore the semantic-visual interactions to discover comprehensive knowledge transferred from seen categories to classify unseen categories. Recently, prompt engineering has emerged in ZSL, demonstrating impressive potential as it enables the zero-shot transfer of diverse visual concepts to downstream tasks. However, these methods are still not well generalized to broad unseen domains. A key reason is that the fixed adaption of learnable prompts on seen domains makes it tend to over-emphasize the primary visual features observed during training. In this work, we propose a \textbf{P}rompt-to-\textbf{P}rompt generation methodology (\textbf{P2P}), which addresses this issue by further embracing the instruction-following technique to distill instructive visual prompts for comprehensive transferable knowledge discovery. The core of P2P is to mine semantic-related instruction from prompt-conditioned visual features and text instruction on modal-sharing semantic concepts and then inversely rectify the visual representations with the guidance of the learned instruction prompts. This enforces the compensation for missing visual details to primary contexts and further eliminates the cross-modal disparity, endowing unseen domain generalization. Through extensive experimental results, we demonstrate the efficacy of P2P in achieving superior performance over state-of-the-art methods.